 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Visual-Language Alignment of the Q-Former for Visual Reasoning Tasks
Oct 12, 2024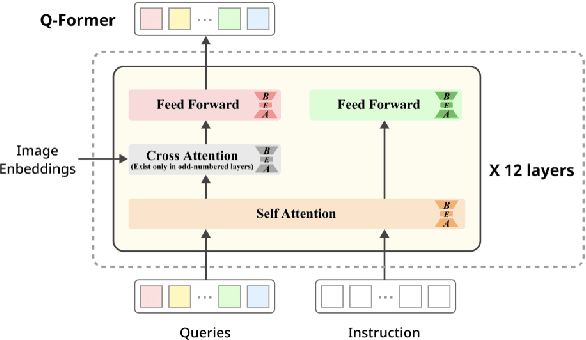
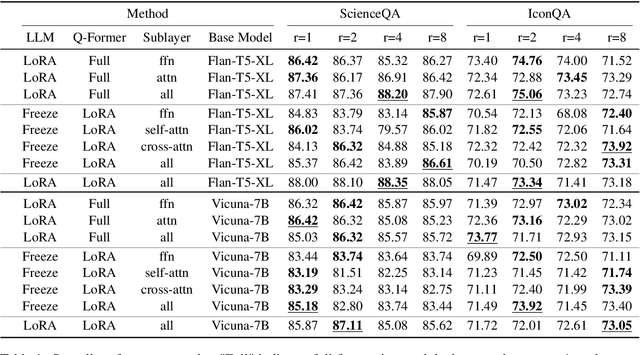
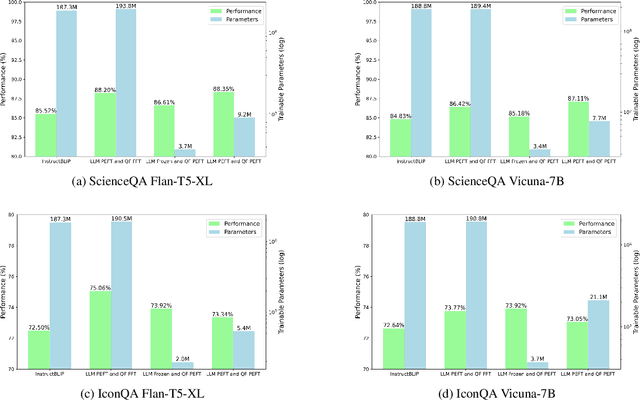
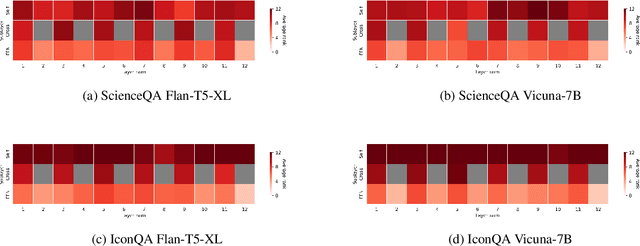
Recent advancements in large language models have demonstrated enhanced capabilities in visual reasoning tasks by employing additional encoders for aligning different modalities. While the Q-Former has been widely used as a general encoder for aligning several modalities including image, video, audio, and 3D with large language models, previous works on its efficient training and the analysis of its individual components have been limited. In this work, we investigate the effectiveness of parameter efficient fine-tuning (PEFT) the Q-Former using InstructBLIP with visual reasoning benchmarks ScienceQA and IconQA. We observe that applying PEFT to the Q-Former achieves comparable performance to full fine-tuning using under 2% of the trainable parameters. Additionally, we employ AdaLoRA for dynamic parameter budget reallocation to examine the relative importance of the Q-Former's sublayers with 4 different benchmarks. Our findings reveal that the self-attention layers are noticeably more important in perceptual visual-language reasoning tasks, and relative importance of FFN layers depends on the complexity of visual-language patterns involved in tasks. The code is available at https://github.com/AttentionX/InstructBLIP_PEFT.
Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models
Mar 26, 2024Hallucinations in vision-language models pose a significant challenge to their reliability, particularly in the generation of long captions. Current methods fall short of accurately identifying and mitigating these hallucinations. To address this issue, we introduce ESREAL, a novel unsupervised learning framework designed to suppress the generation of hallucinations through accurate localization and penalization of hallucinated tokens. Initially, ESREAL creates a reconstructed image based on the generated caption and aligns its corresponding regions with those of the original image. This semantic reconstruction aids in identifying both the presence and type of token-level hallucinations within the generated caption. Subsequently, ESREAL computes token-level hallucination scores by assessing the semantic similarity of aligned regions based on the type of hallucination. Finally, ESREAL employs a proximal policy optimization algorithm, where it selectively penalizes hallucinated tokens according to their token-level hallucination scores. Our framework notably reduces hallucinations in LLaVA, InstructBLIP, and mPLUG-Owl2 by 32.81%, 27.08%, and 7.46% on the CHAIR metric. This improvement is achieved solely through signals derived from the image itself, without the need for any image-text pairs.