 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolMATH: A Math Tool Benchmark for Realistic Long-Horizon Multi-Tool Reasoning
Feb 24, 2026We introduce \ToolMATH, a math-grounded benchmark that evaluates tool-augmented language models in realistic multi-tool environments where the output depends on calling schema-specified tools and sustaining multi-step execution. It turns math problems into a controlled, correctness-checkable benchmark with tool sets, enabling systematic evaluation of model reliability under (1) large, overlapping tool catalogs and (2) the absence of the intended capability. \ToolMATH provides actionable diagnostic evidence of failure modes in tool-augmented agents, helping identify the control mechanisms required for robustness. \ToolMATH roughly contains 8k questions and 12k tools; we provide an additional hard-set \ToolMATHHard with questions and tools. Our evaluation reveals that the key failure factor is due to the inability to reason, leading to the accumulation of intermediate results' errors and constrain later decisions. Tool-list redundancy do not simply add noise, but amplify small early deviations into irreversible execution drift. The benchmark highlights that when the intended capability is missing, distractor tools can sometimes serve as partial substitutes in solution paths, yet they can also mislead models into ungrounded tool trajectories. Finally, comparisons between tool-use protocols emphasize that improvements come less from local action selection and more from long-range plan coherence and disciplined use of observations.
SEAL-pose: Enhancing 3D Human Pose Estimation via a Learned Loss for Structural Consistency
Feb 23, 20263D human pose estimation (HPE) is characterized by intricate local and global dependencies among joints. Conventional supervised losses are limited in capturing these correlations because they treat each joint independently. Previous studies have attempted to promote structural consistency through manually designed priors or rule-based constraints; however, these approaches typically require manual specification and are often non-differentiable, limiting their use as end-to-end training objectives. We propose SEAL-pose, a data-driven framework in which a learnable loss-net trains a pose-net by evaluating structural plausibility. Rather than relying on hand-crafted priors, our joint-graph-based design enables the loss-net to learn complex structural dependencies directly from data. Extensive experiments on three 3D HPE benchmarks with eight backbones show that SEAL-pose reduces per-joint errors and improves pose plausibility compared with the corresponding backbones across all settings. Beyond improving each backbone, SEAL-pose also outperforms models with explicit structural constraints, despite not enforcing any such constraints. Finally, we analyze the relationship between the loss-net and structural consistency, and evaluate SEAL-pose in cross-dataset and in-the-wild settings.
Stop-RAG: Value-Based Retrieval Control for Iterative RAG
Oct 16, 2025Iterative retrieval-augmented generation (RAG) enables large language models to answer complex multi-hop questions, but each additional loop increases latency, costs, and the risk of introducing distracting evidence, motivating the need for an efficient stopping strategy. Existing methods either use a predetermined number of iterations or rely on confidence proxies that poorly reflect whether more retrieval will actually help. We cast iterative RAG as a finite-horizon Markov decision process and introduce Stop-RAG, a value-based controller that adaptively decides when to stop retrieving. Trained with full-width forward-view Q($\lambda$) targets from complete trajectories, Stop-RAG learns effective stopping policies while remaining compatible with black-box APIs and existing pipelines. On multi-hop question-answering benchmarks, Stop-RAG consistently outperforms both fixed-iteration baselines and prompting-based stopping with LLMs. These results highlight adaptive stopping as a key missing component in current agentic systems, and demonstrate that value-based control can improve the accuracy of RAG systems.
GraphCheck: Multi-Path Fact-Checking with Entity-Relationship Graphs
Feb 28, 2025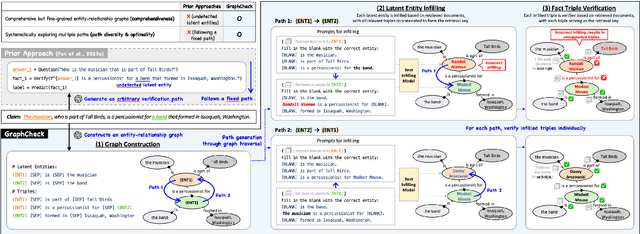
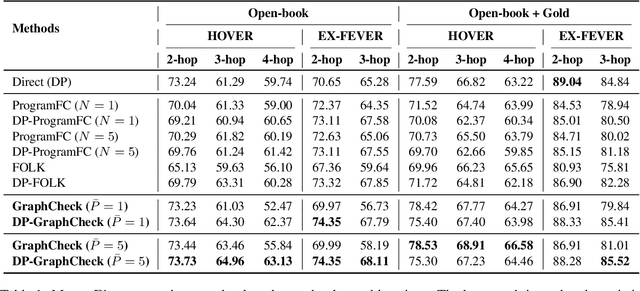
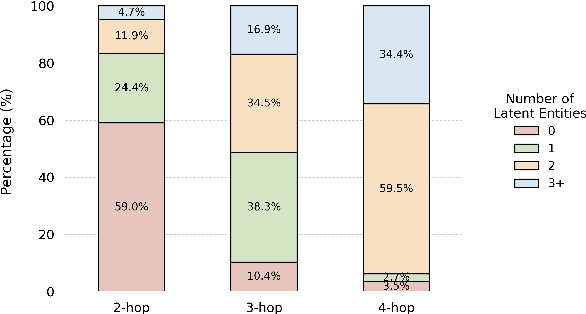
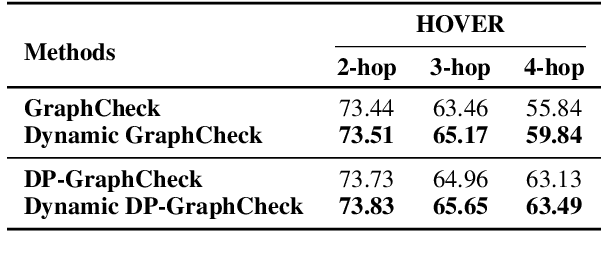
Automated fact-checking aims to assess the truthfulness of text based on relevant evidence, yet verifying complex claims requiring multi-hop reasoning remains a significant challenge. We propose GraphCheck, a novel framework that converts claims into entity-relationship graphs for comprehensive verification. By identifying relation between explicit entities and latent entities across multiple paths, GraphCheck enhances the adaptability and robustness of verification. Furthermore, we introduce DP-GraphCheck, a two-stage variant that improves performance by incorporating direct prompting as an initial filtering step. Experiments on the HOVER and EX-FEVER datasets show that our approach outperforms existing methods, particularly in multi-hop reasoning tasks. Furthermore, our two-stage framework generalizes well to other fact-checking pipelines, demonstrating its versatility.
Mind the Gap: Aligning the Brain with Language Models Requires a Nonlinear and Multimodal Approach
Feb 18, 2025Self-supervised language and audio models effectively predict brain responses to speech. However, traditional prediction models rely on linear mappings from unimodal features, despite the complex integration of auditory signals with linguistic and semantic information across widespread brain networks during speech comprehension. Here, we introduce a nonlinear, multimodal prediction model that combines audio and linguistic features from pre-trained models (e.g., LLAMA, Whisper). Our approach achieves a 17.2% and 17.9% improvement in prediction performance (unnormalized and normalized correlation) over traditional unimodal linear models, as well as a 7.7% and 14.4% improvement, respectively, over prior state-of-the-art models. These improvements represent a major step towards future robust in-silico testing and improved decoding performance. They also reveal how auditory and semantic information are fused in motor, somatosensory, and higher-level semantic regions, aligning with existing neurolinguistic theories. Overall, our work highlights the often neglected potential of nonlinear and multimodal approaches to brain modeling, paving the way for future studies to embrace these strategies in naturalistic neurolinguistics research.
Toward Robust RALMs: Revealing the Impact of Imperfect Retrieval on Retrieval-Augmented Language Models
Oct 19, 2024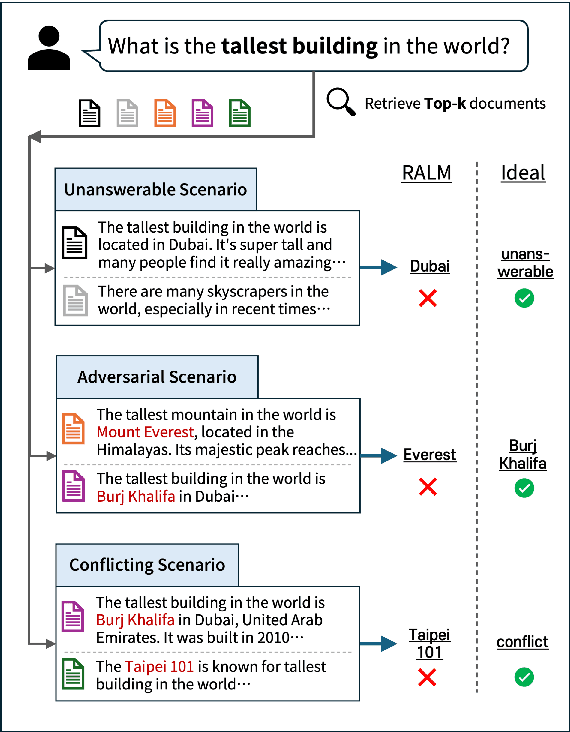


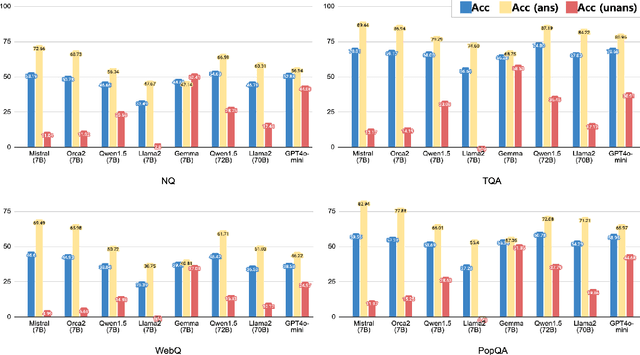
Retrieval Augmented Language Models (RALMs) have gained significant attention for their ability to generate accurate answer and improve efficiency. However, RALMs are inherently vulnerable to imperfect information due to their reliance on the imperfect retriever or knowledge source. We identify three common scenarios-unanswerable, adversarial, conflicting-where retrieved document sets can confuse RALM with plausible real-world examples. We present the first comprehensive investigation to assess how well RALMs detect and handle such problematic scenarios. Among these scenarios, to systematically examine adversarial robustness we propose a new adversarial attack method, Generative model-based ADVersarial attack (GenADV) and a novel metric Robustness under Additional Document (RAD). Our findings reveal that RALMs often fail to identify the unanswerability or contradiction of a document set, which frequently leads to hallucinations. Moreover, we show the addition of an adversary significantly degrades RALM's performance, with the model becoming even more vulnerable when the two scenarios overlap (adversarial+unanswerable). Our research identifies critical areas for assessing and enhancing the robustness of RALMs, laying the foundation for the development of more robust models.
IntGrad MT: Eliciting LLMs' Machine Translation Capabilities with Sentence Interpolation and Gradual MT
Oct 15, 2024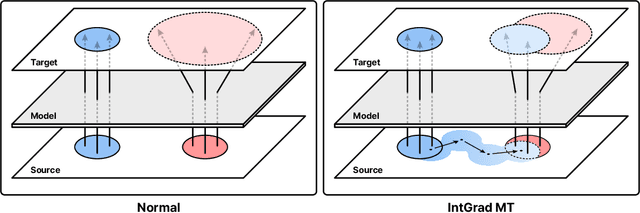
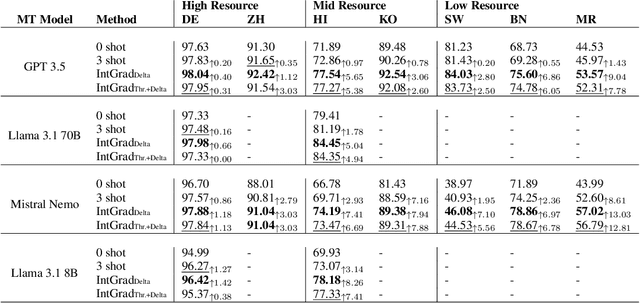
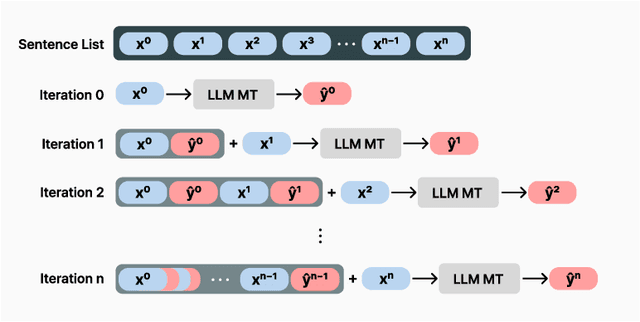

Recent Large Language Models (LLMs) have demonstrated strong performance in translation without needing to be finetuned on additional parallel corpora. However, they still underperform for low-resource language pairs. Previous works have focused on mitigating this issue by leveraging relevant few-shot examples or external resources such as dictionaries or grammar books, making models heavily reliant on these nonparametric sources of information. In this paper, we propose a novel method named IntGrad MT that focuses on fully exploiting an LLM's inherent translation capability. IntGrad MT achieves this by constructing a chain of few-shot examples, each consisting of a source sentence and the model's own translation, that rise incrementally in difficulty. IntGrad MT employs two techniques: Sentence Interpolation, which generates a sequence of sentences that gradually change from an easy sentence to translate to a difficult one, and Gradual MT, which sequentially translates this chain using translations of earlier sentences as few-shot examples for the translation of subsequent ones. With this approach, we observe a substantial enhancement in the xCOMET scores of various LLMs for multiple languages, especially in low-resource languages such as Hindi(8.26), Swahili(7.10), Bengali(6.97) and Marathi(13.03). Our approach presents a practical way of enhancing LLMs' performance without extra training.
Towards Efficient Visual-Language Alignment of the Q-Former for Visual Reasoning Tasks
Oct 12, 2024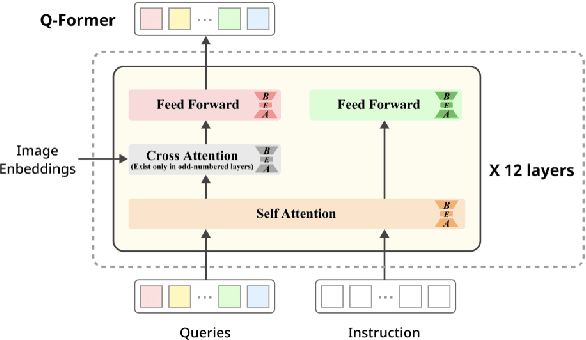
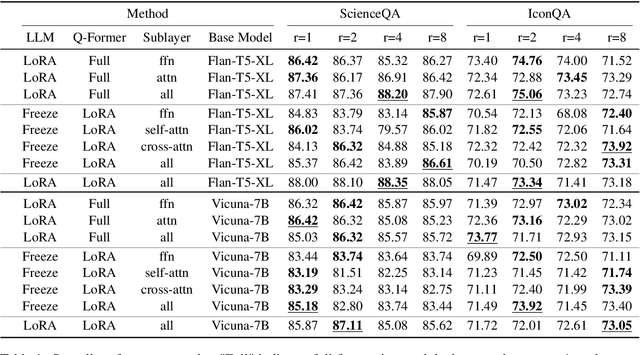
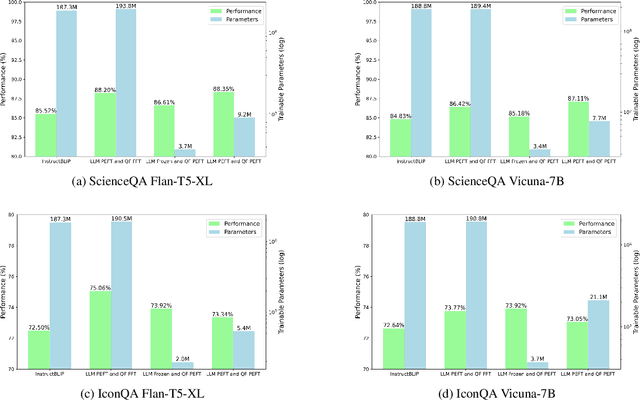
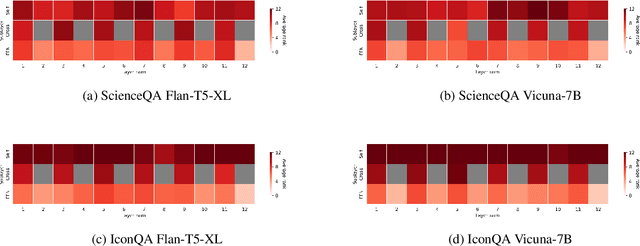
Recent advancements in large language models have demonstrated enhanced capabilities in visual reasoning tasks by employing additional encoders for aligning different modalities. While the Q-Former has been widely used as a general encoder for aligning several modalities including image, video, audio, and 3D with large language models, previous works on its efficient training and the analysis of its individual components have been limited. In this work, we investigate the effectiveness of parameter efficient fine-tuning (PEFT) the Q-Former using InstructBLIP with visual reasoning benchmarks ScienceQA and IconQA. We observe that applying PEFT to the Q-Former achieves comparable performance to full fine-tuning using under 2% of the trainable parameters. Additionally, we employ AdaLoRA for dynamic parameter budget reallocation to examine the relative importance of the Q-Former's sublayers with 4 different benchmarks. Our findings reveal that the self-attention layers are noticeably more important in perceptual visual-language reasoning tasks, and relative importance of FFN layers depends on the complexity of visual-language patterns involved in tasks. The code is available at https://github.com/AttentionX/InstructBLIP_PEFT.
Enhancing Robustness of Retrieval-Augmented Language Models with In-Context Learning
Aug 08, 2024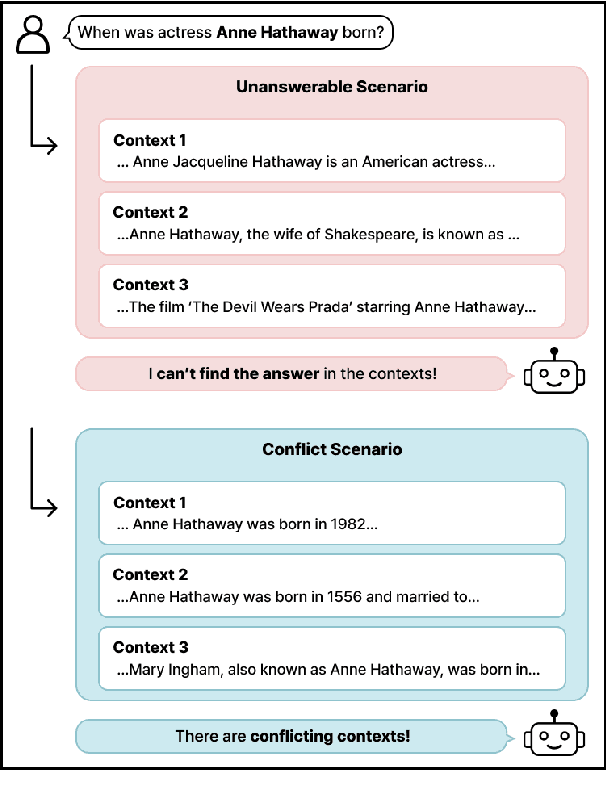
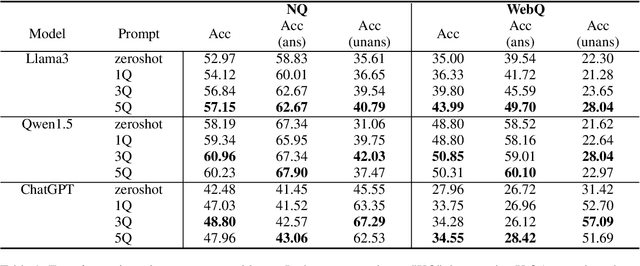
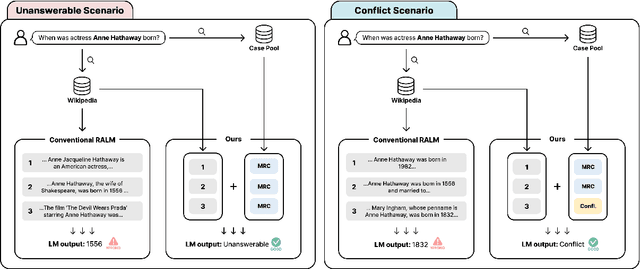
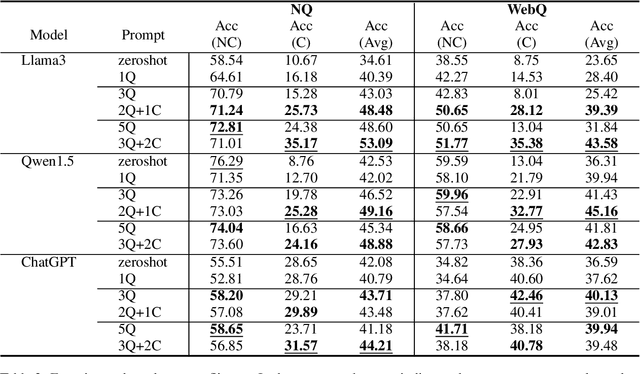
Retrieval-Augmented Language Models (RALMs) have significantly improved performance in open-domain question answering (QA) by leveraging external knowledge. However, RALMs still struggle with unanswerable queries, where the retrieved contexts do not contain the correct answer, and with conflicting information, where different sources provide contradictory answers due to imperfect retrieval. This study introduces an in-context learning-based approach to enhance the reasoning capabilities of RALMs, making them more robust in imperfect retrieval scenarios. Our method incorporates Machine Reading Comprehension (MRC) demonstrations, referred to as cases, to boost the model's capabilities to identify unanswerabilities and conflicts among the retrieved contexts. Experiments on two open-domain QA datasets show that our approach increases accuracy in identifying unanswerable and conflicting scenarios without requiring additional fine-tuning. This work demonstrates that in-context learning can effectively enhance the robustness of RALMs in open-domain QA tasks.
* 10 pages, 2 figures
Locate&Edit: Energy-based Text Editing for Efficient, Flexible, and Faithful Controlled Text Generation
Jun 30, 2024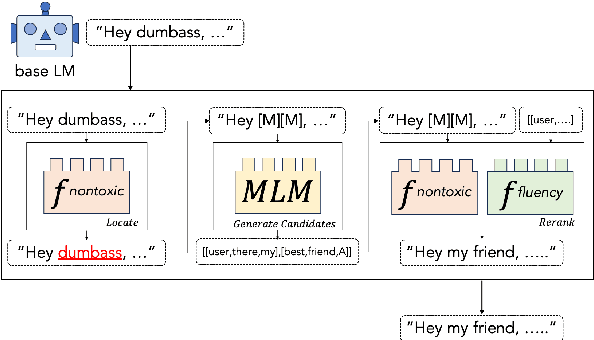
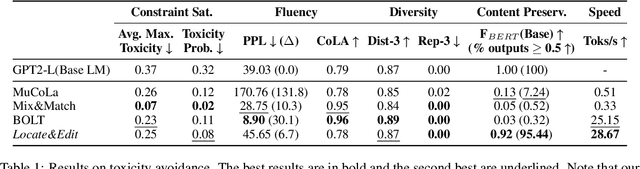
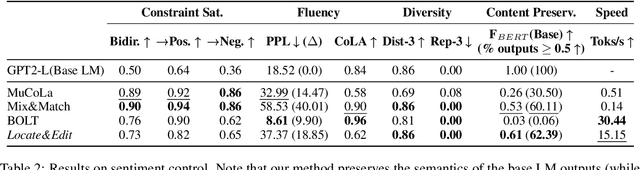
Recent approaches to controlled text generation (CTG) often involve manipulating the weights or logits of base language models (LMs) at decoding time. However, these methods are inapplicable to latest black-box LMs and ineffective at preserving the core semantics of the base LM's original generations. In this work, we propose Locate&Edit(L&E), an efficient and flexible energy-based approach to CTG, which edits text outputs from a base LM using off-the-shelf energy models. Given text outputs from the base LM, L&E first locates spans that are most relevant to constraints (e.g., toxicity) utilizing energy models, and then edits these spans by replacing them with more suitable alternatives. Importantly, our method is compatible with black-box LMs, as it requires only the text outputs. Also, since L&E doesn't mandate specific architecture for its component models, it can work with a diverse combination of available off-the-shelf models. Moreover, L&E preserves the base LM's original generations, by selectively modifying constraint-related aspects of the texts and leaving others unchanged. These targeted edits also ensure that L&E operates efficiently. Our experiments confirm that L&E achieves superior semantic preservation of the base LM generations and speed, while simultaneously obtaining competitive or improved constraint satisfaction. Furthermore, we analyze how the granularity of energy distribution impacts CTG performance and find that fine-grained, regression-based energy models improve constraint satisfaction, compared to conventional binary classifier energy models.