 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALUEFLOW: Toward Pluralistic and Steerable Value-based Alignment in Large Language Models
Feb 03, 2026Aligning Large Language Models (LLMs) with the diverse spectrum of human values remains a central challenge: preference-based methods often fail to capture deeper motivational principles. Value-based approaches offer a more principled path, yet three gaps persist: extraction often ignores hierarchical structure, evaluation detects presence but not calibrated intensity, and the steerability of LLMs at controlled intensities remains insufficiently understood. To address these limitations, we introduce VALUEFLOW, the first unified framework that spans extraction, evaluation, and steering with calibrated intensity control. The framework integrates three components: (i) HIVES, a hierarchical value embedding space that captures intra- and cross-theory value structure; (ii) the Value Intensity DataBase (VIDB), a large-scale resource of value-labeled texts with intensity estimates derived from ranking-based aggregation; and (iii) an anchor-based evaluator that produces consistent intensity scores for model outputs by ranking them against VIDB panels. Using VALUEFLOW, we conduct a comprehensive large-scale study across ten models and four value theories, identifying asymmetries in steerability and composition laws for multi-value control. This paper establishes a scalable infrastructure for evaluating and controlling value intensity, advancing pluralistic alignment of LLMs.
Towards Efficient Visual-Language Alignment of the Q-Former for Visual Reasoning Tasks
Oct 12, 2024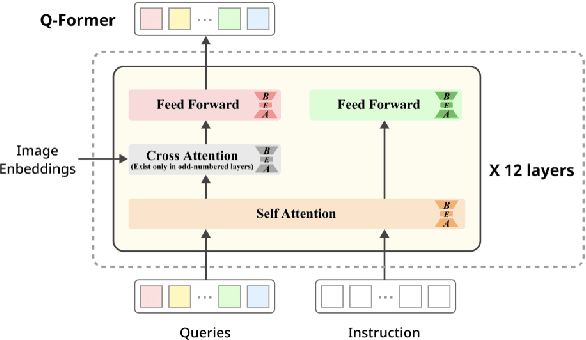
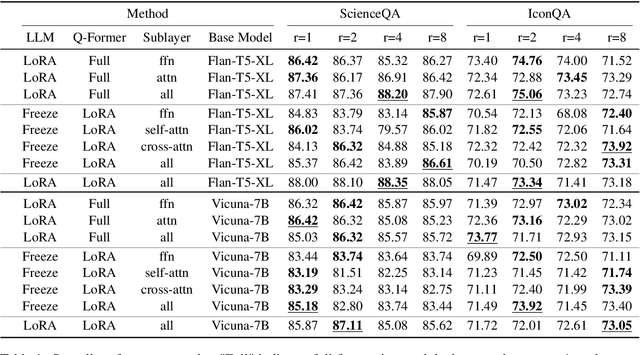
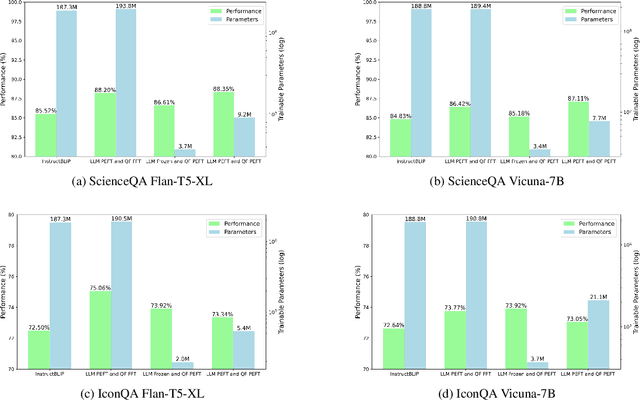
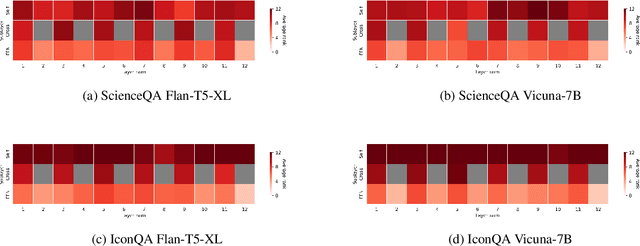
Recent advancements in large language models have demonstrated enhanced capabilities in visual reasoning tasks by employing additional encoders for aligning different modalities. While the Q-Former has been widely used as a general encoder for aligning several modalities including image, video, audio, and 3D with large language models, previous works on its efficient training and the analysis of its individual components have been limited. In this work, we investigate the effectiveness of parameter efficient fine-tuning (PEFT) the Q-Former using InstructBLIP with visual reasoning benchmarks ScienceQA and IconQA. We observe that applying PEFT to the Q-Former achieves comparable performance to full fine-tuning using under 2% of the trainable parameters. Additionally, we employ AdaLoRA for dynamic parameter budget reallocation to examine the relative importance of the Q-Former's sublayers with 4 different benchmarks. Our findings reveal that the self-attention layers are noticeably more important in perceptual visual-language reasoning tasks, and relative importance of FFN layers depends on the complexity of visual-language patterns involved in tasks. The code is available at https://github.com/AttentionX/InstructBLIP_PEFT.