 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALUEFLOW: Toward Pluralistic and Steerable Value-based Alignment in Large Language Models
Feb 03, 2026Aligning Large Language Models (LLMs) with the diverse spectrum of human values remains a central challenge: preference-based methods often fail to capture deeper motivational principles. Value-based approaches offer a more principled path, yet three gaps persist: extraction often ignores hierarchical structure, evaluation detects presence but not calibrated intensity, and the steerability of LLMs at controlled intensities remains insufficiently understood. To address these limitations, we introduce VALUEFLOW, the first unified framework that spans extraction, evaluation, and steering with calibrated intensity control. The framework integrates three components: (i) HIVES, a hierarchical value embedding space that captures intra- and cross-theory value structure; (ii) the Value Intensity DataBase (VIDB), a large-scale resource of value-labeled texts with intensity estimates derived from ranking-based aggregation; and (iii) an anchor-based evaluator that produces consistent intensity scores for model outputs by ranking them against VIDB panels. Using VALUEFLOW, we conduct a comprehensive large-scale study across ten models and four value theories, identifying asymmetries in steerability and composition laws for multi-value control. This paper establishes a scalable infrastructure for evaluating and controlling value intensity, advancing pluralistic alignment of LLMs.
MatKV: Trading Compute for Flash Storage in LLM Inference
Dec 20, 2025We observe two major trends in LLM-based generative AI: (1) inference is becoming the dominant factor in terms of cost and power consumption, surpassing training, and (2) retrieval augmented generation (RAG) is becoming prevalent. When processing long inputs in RAG, the prefill phase of computing the key-value vectors of input text is energy-intensive and time-consuming even with high-end GPUs. Thus, it is crucial to make the prefill phase in RAG inference efficient. To address this issue, we propose MatKV, a scheme that precomputes the key-value vectors (KVs) of RAG objects (e.g., documents), materializes them in inexpensive but fast and power-efficient flash storage, and reuses them at inference time instead of recomputing the KVs using costly and power-inefficient GPU. Experimental results using Hugging Face's Transformers library across state-of-the-art GPUs and flash memory SSDs confirm that, compared to full KV computation on GPUs, MatKV reduces both inference time and power consumption by half for RAG workloads, without severely impacting accuracy in the question-answering task. Furthermore, we demonstrate that MatKV enables additional optimizations in two ways. First, a GPU can decode text while simultaneously loading the materialized KVs for the next instance, reducing load latency. Second, since decoding speed is less sensitive to GPU performance than KV computation, low-end GPUs can be leveraged for decoding without significantly compromising speed once the materialized KVs are loaded into GPU memory. These findings underscore MatKV's potential to make large-scale generative AI applications more cost-effective, power-efficient, and accessible across a wider range of tasks and hardware environments.
Don't Let It Fade: Preserving Edits in Diffusion Language Models via Token Timestep Allocation
Oct 30, 2025While diffusion language models (DLMs) enable fine-grained refinement, their practical controllability remains fragile. We identify and formally characterize a central failure mode called update forgetting, in which uniform and context agnostic updates induce token level fluctuations across timesteps, erasing earlier semantic edits and disrupting the cumulative refinement process, thereby degrading fluency and coherence. As this failure originates in uniform and context agnostic updates, effective control demands explicit token ordering. We propose Token Timestep Allocation (TTA), which realizes soft and semantic token ordering via per token timestep schedules: critical tokens are frozen early, while uncertain tokens receive continued refinement. This timestep based ordering can be instantiated as either a fixed policy or an adaptive policy driven by task signals, thereby supporting a broad spectrum of refinement strategies. Because it operates purely at inference time, it applies uniformly across various DLMs and naturally extends to diverse supervision sources. Empirically, TTA improves controllability and fluency: on sentiment control, it yields more than 20 percent higher accuracy and nearly halves perplexity using less than one fifth the steps; in detoxification, it lowers maximum toxicity (12.2 versus 14.5) and perplexity (26.0 versus 32.0). Together, these results demonstrate that softened ordering via timestep allocation is the critical lever for mitigating update forgetting and achieving stable and controllable diffusion text generation.
SECOND: Mitigating Perceptual Hallucination in Vision-Language Models via Selective and Contrastive Decoding
Jun 10, 2025Despite significant advancements in Vision-Language Models (VLMs), the performance of existing VLMs remains hindered by object hallucination, a critical challenge to achieving accurate visual understanding. To address this issue, we propose SECOND: Selective and Contrastive Decoding, a novel approach that enables VLMs to effectively leverage multi-scale visual information with an object-centric manner, closely aligning with human visual perception. SECOND progressively selects and integrates multi-scale visual information, facilitating a more precise interpretation of images. By contrasting these visual information iteratively, SECOND significantly reduces perceptual hallucinations and outperforms a wide range of benchmarks. Our theoretical analysis and experiments highlight the largely unexplored potential of multi-scale application in VLMs, showing that prioritizing and contrasting across scales outperforms existing methods.
MathReader : Text-to-Speech for Mathematical Documents
Jan 13, 2025



TTS (Text-to-Speech) document reader from Microsoft, Adobe, Apple, and OpenAI have been serviced worldwide. They provide relatively good TTS results for general plain text, but sometimes skip contents or provide unsatisfactory results for mathematical expressions. This is because most modern academic papers are written in LaTeX, and when LaTeX formulas are compiled, they are rendered as distinctive text forms within the document. However, traditional TTS document readers output only the text as it is recognized, without considering the mathematical meaning of the formulas. To address this issue, we propose MathReader, which effectively integrates OCR, a fine-tuned T5 model, and TTS. MathReader demonstrated a lower Word Error Rate (WER) than existing TTS document readers, such as Microsoft Edge and Adobe Acrobat, when processing documents containing mathematical formulas. MathReader reduced the WER from 0.510 to 0.281 compared to Microsoft Edge, and from 0.617 to 0.281 compared to Adobe Acrobat. This will significantly contribute to alleviating the inconvenience faced by users who want to listen to documents, especially those who are visually impaired. The code is available at https://github.com/hyeonsieun/MathReader.
MathSpeech: Leveraging Small LMs for Accurate Conversion in Mathematical Speech-to-Formula
Dec 20, 2024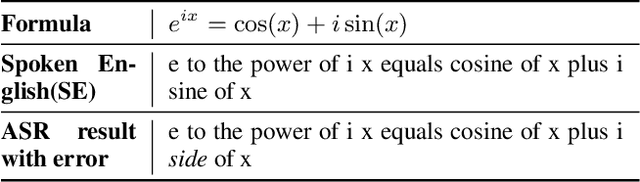
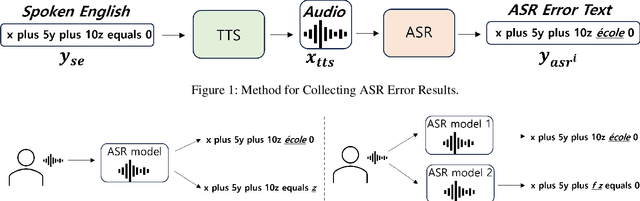
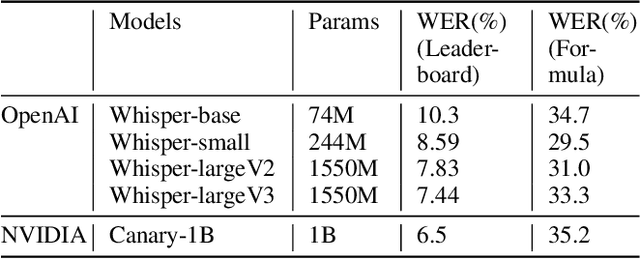

In various academic and professional settings, such as mathematics lectures or research presentations, it is often necessary to convey mathematical expressions orally. However, reading mathematical expressions aloud without accompanying visuals can significantly hinder comprehension, especially for those who are hearing-impaired or rely on subtitles due to language barriers. For instance, when a presenter reads Euler's Formula, current Automatic Speech Recognition (ASR) models often produce a verbose and error-prone textual description (e.g., e to the power of i x equals cosine of x plus i $\textit{side}$ of x), instead of the concise $\LaTeX{}$ format (i.e., $ e^{ix} = \cos(x) + i\sin(x) $), which hampers clear understanding and communication. To address this issue, we introduce MathSpeech, a novel pipeline that integrates ASR models with small Language Models (sLMs) to correct errors in mathematical expressions and accurately convert spoken expressions into structured $\LaTeX{}$ representations. Evaluated on a new dataset derived from lecture recordings, MathSpeech demonstrates $\LaTeX{}$ generation capabilities comparable to leading commercial Large Language Models (LLMs), while leveraging fine-tuned small language models of only 120M parameters. Specifically, in terms of CER, BLEU, and ROUGE scores for $\LaTeX{}$ translation, MathSpeech demonstrated significantly superior capabilities compared to GPT-4o. We observed a decrease in CER from 0.390 to 0.298, and higher ROUGE/BLEU scores compared to GPT-4o.
MathBridge: A Large Corpus Dataset for Translating Spoken Mathematical Expressions into $LaTeX$ Formulas for Improved Readability
Aug 15, 2024



Understanding sentences that contain mathematical expressions in text form poses significant challenges. To address this, the importance of converting these expressions into a compiled formula is highlighted. For instance, the expression ``x equals minus b plus or minus the square root of b squared minus four a c, all over two a'' from automatic speech recognition (ASR) is more readily comprehensible when displayed as a compiled formula $x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$. To develop a text-to-formula conversion system, we can break down the process into text-to-LaTeX and LaTeX-to-formula conversions, with the latter managed by various existing LaTeX engines. However, the former approach has been notably hindered by the severe scarcity of text-to-LaTeX paired data, which presents a significant challenge in this field. In this context, we introduce MathBridge, the first extensive dataset for translating mathematical spoken expressions into LaTeX, to establish a robust baseline for future research on text-to-LaTeX translation. MathBridge comprises approximately 23 million LaTeX formulas paired with the corresponding spoken English expressions. Through comprehensive evaluations, including fine-tuning and testing with data, we discovered that MathBridge significantly enhances the capabilities of pretrained language models for text-to-LaTeX translation. Specifically, for the T5-large model, the sacreBLEU score increased from 4.77 to 46.8, demonstrating substantial enhancement. Our findings indicate the need for a new metric, specifically for text-to-LaTeX conversion evaluations.
Aligning Large Language Models via Fine-grained Supervision
Jun 04, 2024



Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1\%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
Data Augmentation for Improving Tail-traffic Robustness in Skill-routing for Dialogue Systems
Jun 07, 2023Large-scale conversational systems typically rely on a skill-routing component to route a user request to an appropriate skill and interpretation to serve the request. In such system, the agent is responsible for serving thousands of skills and interpretations which create a long-tail distribution due to the natural frequency of requests. For example, the samples related to play music might be a thousand times more frequent than those asking for theatre show times. Moreover, inputs used for ML-based skill routing are often a heterogeneous mix of strings, embedding vectors, categorical and scalar features which makes employing augmentation-based long-tail learning approaches challenging. To improve the skill-routing robustness, we propose an augmentation of heterogeneous skill-routing data and training targeted for robust operation in long-tail data regimes. We explore a variety of conditional encoder-decoder generative frameworks to perturb original data fields and create synthetic training data. To demonstrate the effectiveness of the proposed method, we conduct extensive experiments using real-world data from a commercial conversational system. Based on the experiment results, the proposed approach improves more than 80% (51 out of 63) of intents with less than 10K of traffic instances in the skill-routing replication task.
Scalable and Safe Remediation of Defective Actions in Self-Learning Conversational Systems
May 17, 2023



Off-Policy reinforcement learning has been a driving force for the state-of-the-art conversational AIs leading to more natural humanagent interactions and improving the user satisfaction for goal-oriented agents. However, in large-scale commercial settings, it is often challenging to balance between policy improvements and experience continuity on the broad spectrum of applications handled by such system. In the literature, off-policy evaluation and guard-railing on aggregate statistics has been commonly used to address this problem. In this paper, we propose a method for curating and leveraging high-precision samples sourced from historical regression incident reports to validate, safe-guard, and improve policies prior to the online deployment. We conducted extensive experiments using data from a real-world conversational system and actual regression incidents. The proposed method is currently deployed in our production system to protect customers against broken experiences and enable long-term policy improvements.