 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema Graph-Guided Prompt for Multi-Domain Dialogue State Tracking
Nov 10, 2023



Tracking dialogue states is an essential topic in task-oriented dialogue systems, which involve filling in the necessary information in pre-defined slots corresponding to a schema. While general pre-trained language models have been shown effective in slot-filling, their performance is limited when applied to specific domains. We propose a graph-based framework that learns domain-specific prompts by incorporating the dialogue schema. Specifically, we embed domain-specific schema encoded by a graph neural network into the pre-trained language model, which allows for relations in the schema to guide the model for better adaptation to the specific domain. Our experiments demonstrate that the proposed graph-based method outperforms other multi-domain DST approaches while using similar or fewer trainable parameters. We also conduct a comprehensive study of schema graph architectures, parameter usage, and module ablation that demonstrate the effectiveness of our model on multi-domain dialogue state tracking.
Data Augmentation for Improving Tail-traffic Robustness in Skill-routing for Dialogue Systems
Jun 07, 2023Large-scale conversational systems typically rely on a skill-routing component to route a user request to an appropriate skill and interpretation to serve the request. In such system, the agent is responsible for serving thousands of skills and interpretations which create a long-tail distribution due to the natural frequency of requests. For example, the samples related to play music might be a thousand times more frequent than those asking for theatre show times. Moreover, inputs used for ML-based skill routing are often a heterogeneous mix of strings, embedding vectors, categorical and scalar features which makes employing augmentation-based long-tail learning approaches challenging. To improve the skill-routing robustness, we propose an augmentation of heterogeneous skill-routing data and training targeted for robust operation in long-tail data regimes. We explore a variety of conditional encoder-decoder generative frameworks to perturb original data fields and create synthetic training data. To demonstrate the effectiveness of the proposed method, we conduct extensive experiments using real-world data from a commercial conversational system. Based on the experiment results, the proposed approach improves more than 80% (51 out of 63) of intents with less than 10K of traffic instances in the skill-routing replication task.
Choice Fusion as Knowledge for Zero-Shot Dialogue State Tracking
Feb 25, 2023With the demanding need for deploying dialogue systems in new domains with less cost, zero-shot dialogue state tracking (DST), which tracks user's requirements in task-oriented dialogues without training on desired domains, draws attention increasingly. Although prior works have leveraged question-answering (QA) data to reduce the need for in-domain training in DST, they fail to explicitly model knowledge transfer and fusion for tracking dialogue states. To address this issue, we propose CoFunDST, which is trained on domain-agnostic QA datasets and directly uses candidate choices of slot-values as knowledge for zero-shot dialogue-state generation, based on a T5 pre-trained language model. Specifically, CoFunDST selects highly-relevant choices to the reference context and fuses them to initialize the decoder to constrain the model outputs. Our experimental results show that our proposed model achieves outperformed joint goal accuracy compared to existing zero-shot DST approaches in most domains on the MultiWOZ 2.1. Extensive analyses demonstrate the effectiveness of our proposed approach for improving zero-shot DST learning from QA.
Act-Aware Slot-Value Predicting in Multi-Domain Dialogue State Tracking
Aug 04, 2022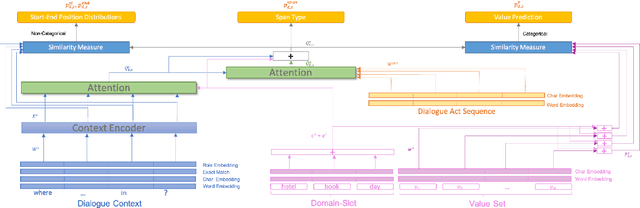
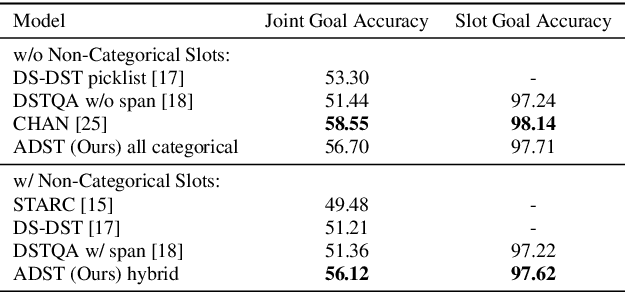
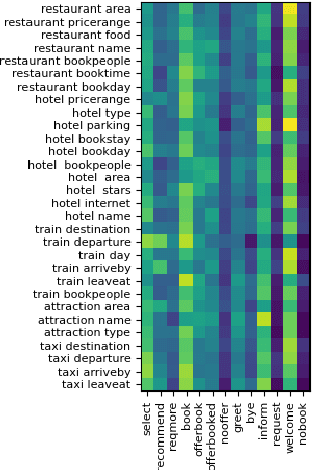

As an essential component in task-oriented dialogue systems, dialogue state tracking (DST) aims to track human-machine interactions and generate state representations for managing the dialogue. Representations of dialogue states are dependent on the domain ontology and the user's goals. In several task-oriented dialogues with a limited scope of objectives, dialogue states can be represented as a set of slot-value pairs. As the capabilities of dialogue systems expand to support increasing naturalness in communication, incorporating dialogue act processing into dialogue model design becomes essential. The lack of such consideration limits the scalability of dialogue state tracking models for dialogues having specific objectives and ontology. To address this issue, we formulate and incorporate dialogue acts, and leverage recent advances in machine reading comprehension to predict both categorical and non-categorical types of slots for multi-domain dialogue state tracking. Experimental results show that our models can improve the overall accuracy of dialogue state tracking on the MultiWOZ 2.1 dataset, and demonstrate that incorporating dialogue acts can guide dialogue state design for future task-oriented dialogue systems.
* Published in Spoken Dialogue Systems I, Interspeech 2021. Code is now publicly available on Github: https://github.com/youlandasu/ACT-AWARE-DST
Knowledge Augmented BERT Mutual Network in Multi-turn Spoken Dialogues
Feb 23, 2022
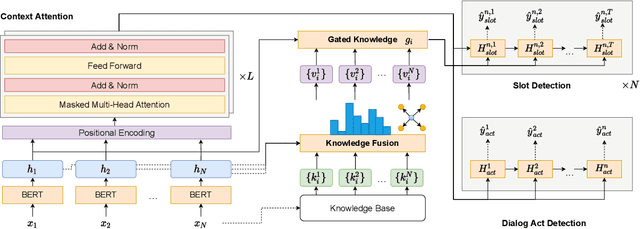


Modern spoken language understanding (SLU) systems rely on sophisticated semantic notions revealed in single utterances to detect intents and slots. However, they lack the capability of modeling multi-turn dynamics within a dialogue particularly in long-term slot contexts. Without external knowledge, depending on limited linguistic legitimacy within a word sequence may overlook deep semantic information across dialogue turns. In this paper, we propose to equip a BERT-based joint model with a knowledge attention module to mutually leverage dialogue contexts between two SLU tasks. A gating mechanism is further utilized to filter out irrelevant knowledge triples and to circumvent distracting comprehension. Experimental results in two complicated multi-turn dialogue datasets have demonstrate by mutually modeling two SLU tasks with filtered knowledge and dialogue contexts, our approach has considerable improvements compared with several competitive baselines.
A Context-Aware Hierarchical BERT Fusion Network for Multi-turn Dialog Act Detection
Sep 03, 2021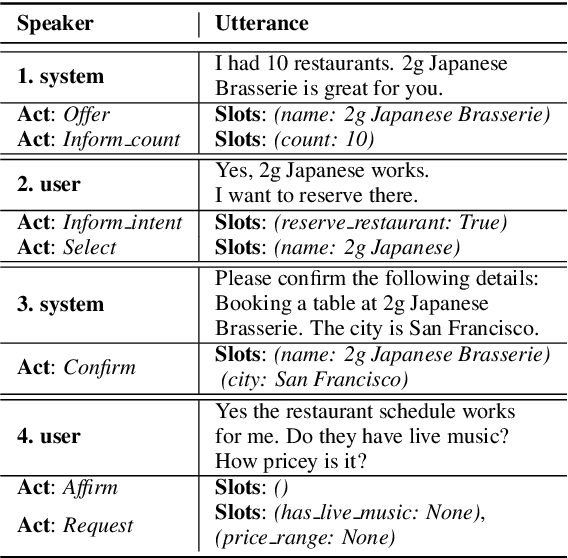
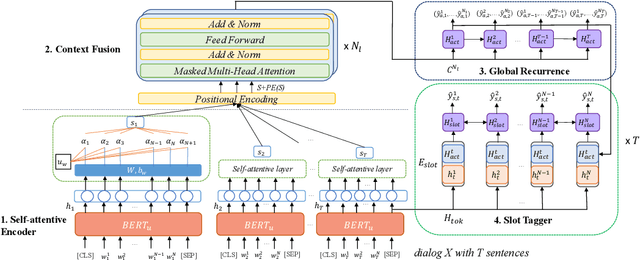
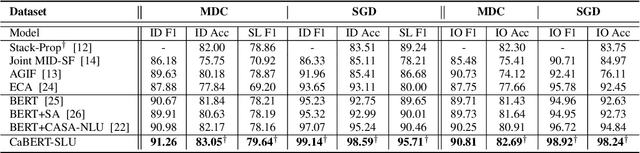

The success of interactive dialog systems is usually associated with the quality of the spoken language understanding (SLU) task, which mainly identifies the corresponding dialog acts and slot values in each turn. By treating utterances in isolation, most SLU systems often overlook the semantic context in which a dialog act is expected. The act dependency between turns is non-trivial and yet critical to the identification of the correct semantic representations. Previous works with limited context awareness have exposed the inadequacy of dealing with complexity in multiproned user intents, which are subject to spontaneous change during turn transitions. In this work, we propose to enhance SLU in multi-turn dialogs, employing a context-aware hierarchical BERT fusion Network (CaBERT-SLU) to not only discern context information within a dialog but also jointly identify multiple dialog acts and slots in each utterance. Experimental results show that our approach reaches new state-of-the-art (SOTA) performances in two complicated multi-turn dialogue datasets with considerable improvements compared with previous methods, which only consider single utterances for multiple intents and slot filling.
Longer Version for "Deep Context-Encoding Network for Retinal Image Captioning"
May 30, 2021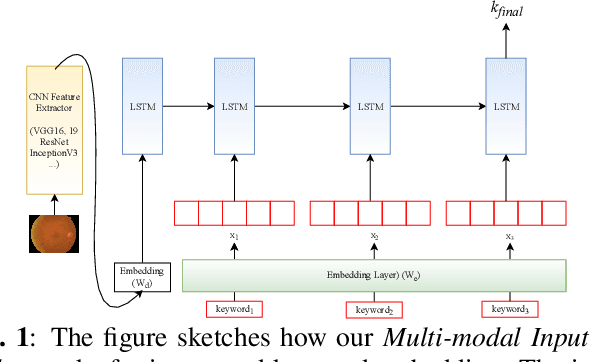
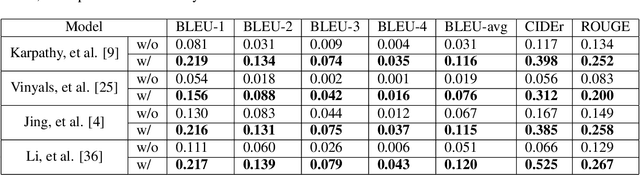
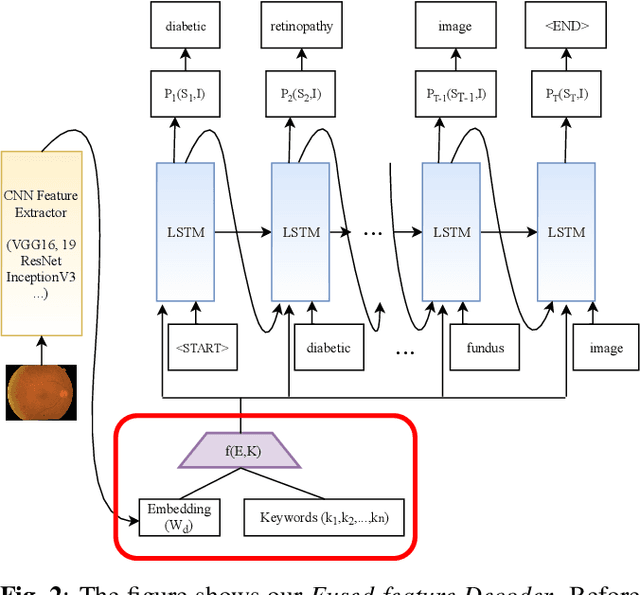

Automatically generating medical reports for retinal images is one of the promising ways to help ophthalmologists reduce their workload and improve work efficiency. In this work, we propose a new context-driven encoding network to automatically generate medical reports for retinal images. The proposed model is mainly composed of a multi-modal input encoder and a fused-feature decoder. Our experimental results show that our proposed method is capable of effectively leveraging the interactive information between the input image and context, i.e., keywords in our case. The proposed method creates more accurate and meaningful reports for retinal images than baseline models and achieves state-of-the-art performance. This performance is shown in several commonly used metrics for the medical report generation task: BLEU-avg (+16%), CIDEr (+10.2%), and ROUGE (+8.6%).
Ensemble-based Transfer Learning for Low-resource Machine Translation Quality Estimation
May 17, 2021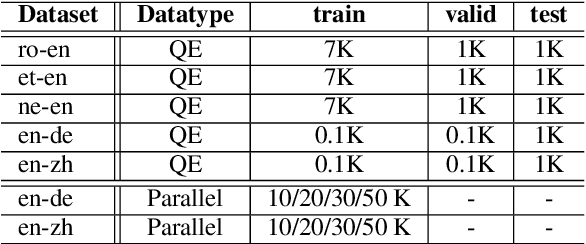

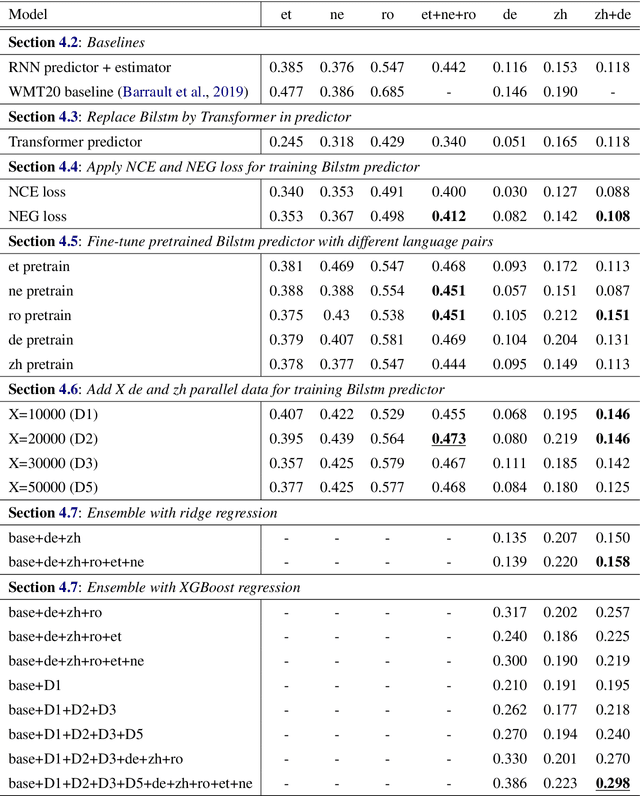
Quality Estimation (QE) of Machine Translation (MT) is a task to estimate the quality scores for given translation outputs from an unknown MT system. However, QE scores for low-resource languages are usually intractable and hard to collect. In this paper, we focus on the Sentence-Level QE Shared Task of the Fifth Conference on Machine Translation (WMT20), but in a more challenging setting. We aim to predict QE scores of given translation outputs when barely none of QE scores of that paired languages are given during training. We propose an ensemble-based predictor-estimator QE model with transfer learning to overcome such QE data scarcity challenge by leveraging QE scores from other miscellaneous languages and translation results of targeted languages. Based on the evaluation results, we provide a detailed analysis of how each of our extension affects QE models on the reliability and the generalization ability to perform transfer learning under multilingual tasks. Finally, we achieve the best performance on the ensemble model combining the models pretrained by individual languages as well as different levels of parallel trained corpus with a Pearson's correlation of 0.298, which is 2.54 times higher than baselines.
Contextualized Keyword Representations for Multi-modal Retinal Image Captioning
Apr 26, 2021



Medical image captioning automatically generates a medical description to describe the content of a given medical image. A traditional medical image captioning model creates a medical description only based on a single medical image input. Hence, an abstract medical description or concept is hard to be generated based on the traditional approach. Such a method limits the effectiveness of medical image captioning. Multi-modal medical image captioning is one of the approaches utilized to address this problem. In multi-modal medical image captioning, textual input, e.g., expert-defined keywords, is considered as one of the main drivers of medical description generation. Thus, encoding the textual input and the medical image effectively are both important for the task of multi-modal medical image captioning. In this work, a new end-to-end deep multi-modal medical image captioning model is proposed. Contextualized keyword representations, textual feature reinforcement, and masked self-attention are used to develop the proposed approach. Based on the evaluation of the existing multi-modal medical image captioning dataset, experimental results show that the proposed model is effective with the increase of +53.2% in BLEU-avg and +18.6% in CIDEr, compared with the state-of-the-art method.
DeepOpht: Medical Report Generation for Retinal Images via Deep Models and Visual Explanation
Nov 01, 2020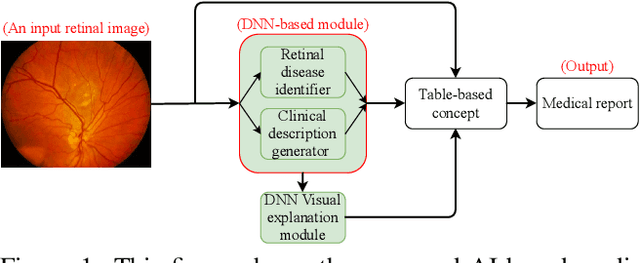
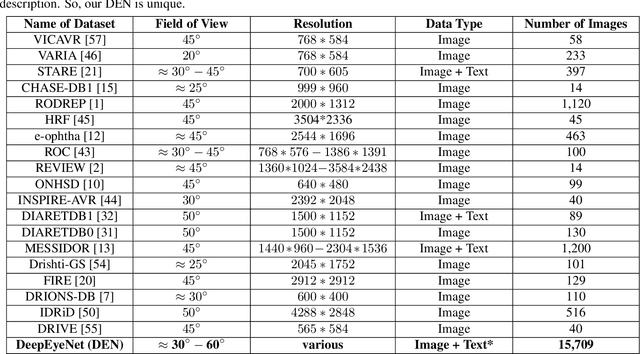
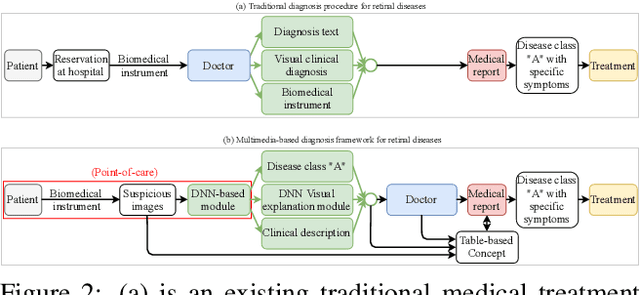
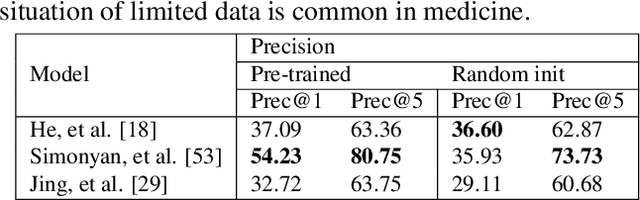
In this work, we propose an AI-based method that intends to improve the conventional retinal disease treatment procedure and help ophthalmologists increase diagnosis efficiency and accuracy. The proposed method is composed of a deep neural networks-based (DNN-based) module, including a retinal disease identifier and clinical description generator, and a DNN visual explanation module. To train and validate the effectiveness of our DNN-based module, we propose a large-scale retinal disease image dataset. Also, as ground truth, we provide a retinal image dataset manually labeled by ophthalmologists to qualitatively show, the proposed AI-based method is effective. With our experimental results, we show that the proposed method is quantitatively and qualitatively effective. Our method is capable of creating meaningful retinal image descriptions and visual explanations that are clinically relevant.