 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany Hands Make Light Work: Task-Oriented Dialogue System with Module-Based Mixture-of-Experts
May 16, 2024Task-oriented dialogue systems are broadly used in virtual assistants and other automated services, providing interfaces between users and machines to facilitate specific tasks. Nowadays, task-oriented dialogue systems have greatly benefited from pre-trained language models (PLMs). However, their task-solving performance is constrained by the inherent capacities of PLMs, and scaling these models is expensive and complex as the model size becomes larger. To address these challenges, we propose Soft Mixture-of-Expert Task-Oriented Dialogue system (SMETOD) which leverages an ensemble of Mixture-of-Experts (MoEs) to excel at subproblems and generate specialized outputs for task-oriented dialogues. SMETOD also scales up a task-oriented dialogue system with simplicity and flexibility while maintaining inference efficiency. We extensively evaluate our model on three benchmark functionalities: intent prediction, dialogue state tracking, and dialogue response generation. Experimental results demonstrate that SMETOD achieves state-of-the-art performance on most evaluated metrics. Moreover, comparisons against existing strong baselines show that SMETOD has a great advantage in the cost of inference and correctness in problem-solving.
Schema Graph-Guided Prompt for Multi-Domain Dialogue State Tracking
Nov 10, 2023



Tracking dialogue states is an essential topic in task-oriented dialogue systems, which involve filling in the necessary information in pre-defined slots corresponding to a schema. While general pre-trained language models have been shown effective in slot-filling, their performance is limited when applied to specific domains. We propose a graph-based framework that learns domain-specific prompts by incorporating the dialogue schema. Specifically, we embed domain-specific schema encoded by a graph neural network into the pre-trained language model, which allows for relations in the schema to guide the model for better adaptation to the specific domain. Our experiments demonstrate that the proposed graph-based method outperforms other multi-domain DST approaches while using similar or fewer trainable parameters. We also conduct a comprehensive study of schema graph architectures, parameter usage, and module ablation that demonstrate the effectiveness of our model on multi-domain dialogue state tracking.
CLICKER: Attention-Based Cross-Lingual Commonsense Knowledge Transfer
Feb 26, 2023Recent advances in cross-lingual commonsense reasoning (CSR) are facilitated by the development of multilingual pre-trained models (mPTMs). While mPTMs show the potential to encode commonsense knowledge for different languages, transferring commonsense knowledge learned in large-scale English corpus to other languages is challenging. To address this problem, we propose the attention-based Cross-LIngual Commonsense Knowledge transfER (CLICKER) framework, which minimizes the performance gaps between English and non-English languages in commonsense question-answering tasks. CLICKER effectively improves commonsense reasoning for non-English languages by differentiating non-commonsense knowledge from commonsense knowledge. Experimental results on public benchmarks demonstrate that CLICKER achieves remarkable improvements in the cross-lingual CSR task for languages other than English.
Choice Fusion as Knowledge for Zero-Shot Dialogue State Tracking
Feb 25, 2023With the demanding need for deploying dialogue systems in new domains with less cost, zero-shot dialogue state tracking (DST), which tracks user's requirements in task-oriented dialogues without training on desired domains, draws attention increasingly. Although prior works have leveraged question-answering (QA) data to reduce the need for in-domain training in DST, they fail to explicitly model knowledge transfer and fusion for tracking dialogue states. To address this issue, we propose CoFunDST, which is trained on domain-agnostic QA datasets and directly uses candidate choices of slot-values as knowledge for zero-shot dialogue-state generation, based on a T5 pre-trained language model. Specifically, CoFunDST selects highly-relevant choices to the reference context and fuses them to initialize the decoder to constrain the model outputs. Our experimental results show that our proposed model achieves outperformed joint goal accuracy compared to existing zero-shot DST approaches in most domains on the MultiWOZ 2.1. Extensive analyses demonstrate the effectiveness of our proposed approach for improving zero-shot DST learning from QA.
Act-Aware Slot-Value Predicting in Multi-Domain Dialogue State Tracking
Aug 04, 2022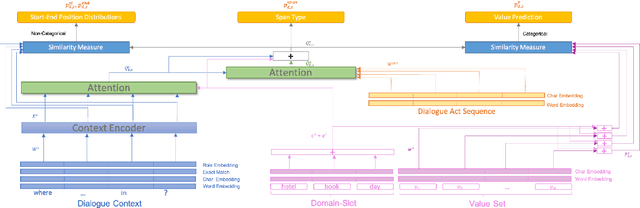
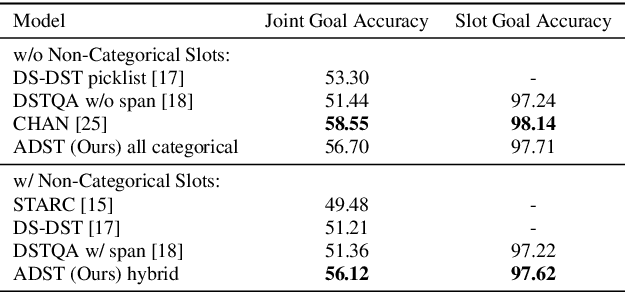
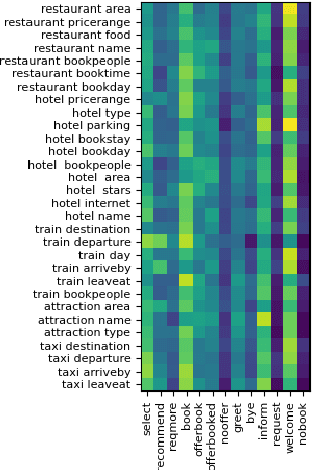

As an essential component in task-oriented dialogue systems, dialogue state tracking (DST) aims to track human-machine interactions and generate state representations for managing the dialogue. Representations of dialogue states are dependent on the domain ontology and the user's goals. In several task-oriented dialogues with a limited scope of objectives, dialogue states can be represented as a set of slot-value pairs. As the capabilities of dialogue systems expand to support increasing naturalness in communication, incorporating dialogue act processing into dialogue model design becomes essential. The lack of such consideration limits the scalability of dialogue state tracking models for dialogues having specific objectives and ontology. To address this issue, we formulate and incorporate dialogue acts, and leverage recent advances in machine reading comprehension to predict both categorical and non-categorical types of slots for multi-domain dialogue state tracking. Experimental results show that our models can improve the overall accuracy of dialogue state tracking on the MultiWOZ 2.1 dataset, and demonstrate that incorporating dialogue acts can guide dialogue state design for future task-oriented dialogue systems.
* Published in Spoken Dialogue Systems I, Interspeech 2021. Code is now publicly available on Github: https://github.com/youlandasu/ACT-AWARE-DST
Why patient data cannot be easily forgotten?
Jun 29, 2022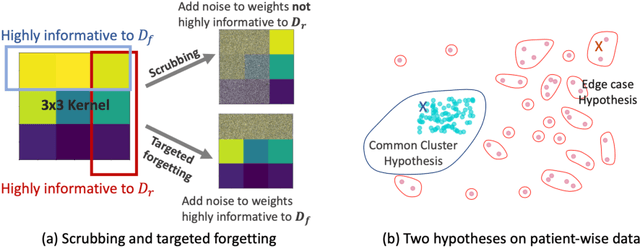
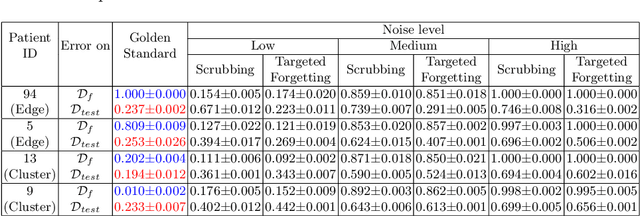
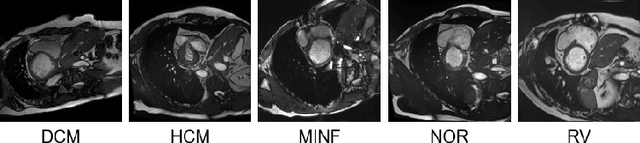
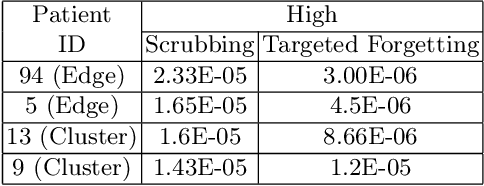
Rights provisioned within data protection regulations, permit patients to request that knowledge about their information be eliminated by data holders. With the advent of AI learned on data, one can imagine that such rights can extent to requests for forgetting knowledge of patient's data within AI models. However, forgetting patients' imaging data from AI models, is still an under-explored problem. In this paper, we study the influence of patient data on model performance and formulate two hypotheses for a patient's data: either they are common and similar to other patients or form edge cases, i.e. unique and rare cases. We show that it is not possible to easily forget patient data. We propose a targeted forgetting approach to perform patient-wise forgetting. Extensive experiments on the benchmark Automated Cardiac Diagnosis Challenge dataset showcase the improved performance of the proposed targeted forgetting approach as opposed to a state-of-the-art method.
A Context-Aware Hierarchical BERT Fusion Network for Multi-turn Dialog Act Detection
Sep 03, 2021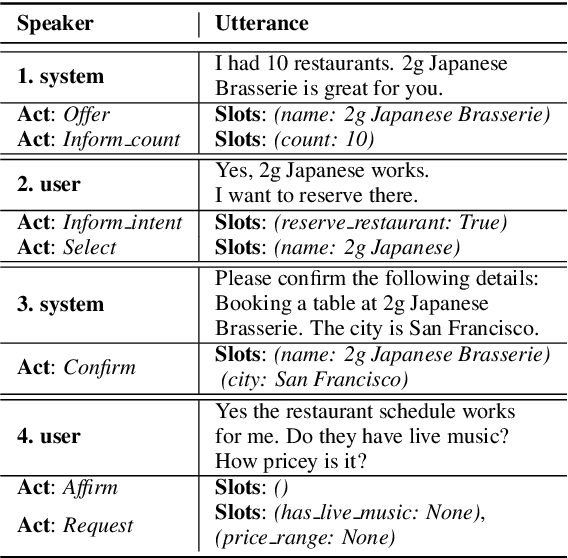
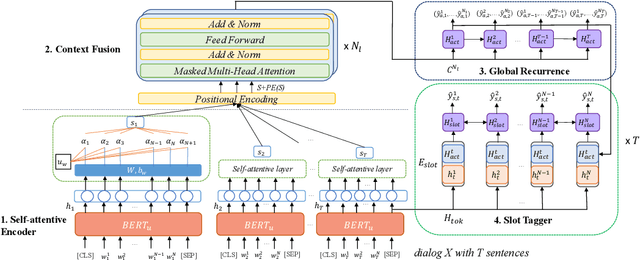
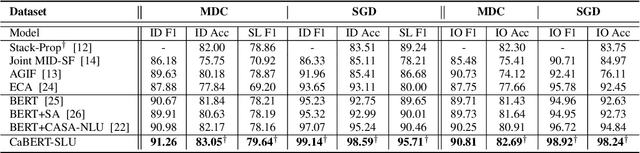

The success of interactive dialog systems is usually associated with the quality of the spoken language understanding (SLU) task, which mainly identifies the corresponding dialog acts and slot values in each turn. By treating utterances in isolation, most SLU systems often overlook the semantic context in which a dialog act is expected. The act dependency between turns is non-trivial and yet critical to the identification of the correct semantic representations. Previous works with limited context awareness have exposed the inadequacy of dealing with complexity in multiproned user intents, which are subject to spontaneous change during turn transitions. In this work, we propose to enhance SLU in multi-turn dialogs, employing a context-aware hierarchical BERT fusion Network (CaBERT-SLU) to not only discern context information within a dialog but also jointly identify multiple dialog acts and slots in each utterance. Experimental results show that our approach reaches new state-of-the-art (SOTA) performances in two complicated multi-turn dialogue datasets with considerable improvements compared with previous methods, which only consider single utterances for multiple intents and slot filling.