 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Jan 30, 2026RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. In practice, prompt pools are often static or only loosely tied to the model's learning progress, so uniform sampling can't keep up with the shifting capability frontier and ends up wasting rollouts on prompts that are already solved or still out of reach. Existing approaches improve efficiency through filtering, curricula, adaptive rollout allocation, or teacher guidance, but they typically assume a fixed pool-which makes it hard to support stable on-policy pool growth-or they add extra teacher cost and latency. We introduce HeaPA (Heap Sampling and On-Policy Query Augmentation), which maintains a bounded, evolving pool, tracks the frontier using heap-based boundary sampling, expands the pool via on-policy augmentation with lightweight asynchronous validation, and stabilizes correlated queries through topology-aware re-estimation of pool statistics and controlled reinsertion. Across two training corpora, two training recipes, and seven benchmarks, HeaPA consistently improves accuracy and reaches target performance with fewer computations while keeping wall-clock time comparable. Our analyses suggest these gains come from frontier-focused sampling and on-policy pool growth, with the benefits becoming larger as model scale increases. Our code is available at https://github.com/horizon-rl/HeaPA.
Language-Image Alignment with Fixed Text Encoders
Jun 04, 2025Currently, the most dominant approach to establishing language-image alignment is to pre-train text and image encoders jointly through contrastive learning, such as CLIP and its variants. In this work, we question whether such a costly joint training is necessary. In particular, we investigate if a pre-trained fixed large language model (LLM) offers a good enough text encoder to guide visual representation learning. That is, we propose to learn Language-Image alignment with a Fixed Text encoder (LIFT) from an LLM by training only the image encoder. Somewhat surprisingly, through comprehensive benchmarking and ablation studies, we find that this much simplified framework LIFT is highly effective and it outperforms CLIP in most scenarios that involve compositional understanding and long captions, while achieving considerable gains in computational efficiency. Our work takes a first step towards systematically exploring how text embeddings from LLMs can guide visual learning and suggests an alternative design choice for learning language-aligned visual representations.
RRO: LLM Agent Optimization Through Rising Reward Trajectories
May 27, 2025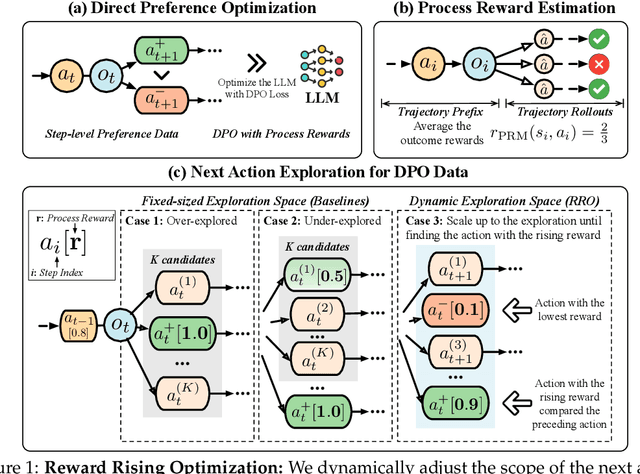
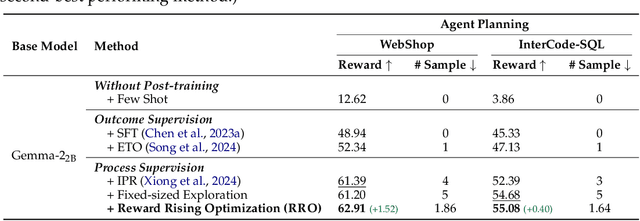
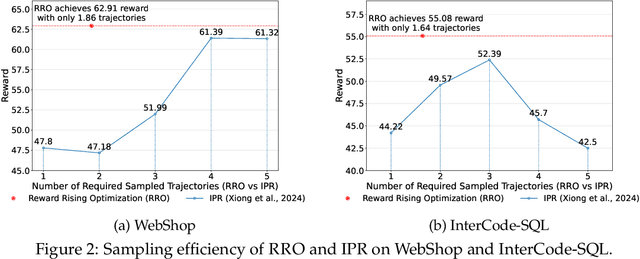

Large language models (LLMs) have exhibited extraordinary performance in a variety of tasks while it remains challenging for them to solve complex multi-step tasks as agents. In practice, agents sensitive to the outcome of certain key steps which makes them likely to fail the task because of a subtle mistake in the planning trajectory. Recent approaches resort to calibrating the reasoning process through reinforcement learning. They reward or penalize every reasoning step with process supervision, as known as Process Reward Models (PRMs). However, PRMs are difficult and costly to scale up with a large number of next action candidates since they require extensive computations to acquire the training data through the per-step trajectory exploration. To mitigate this issue, we focus on the relative reward trend across successive reasoning steps and propose maintaining an increasing reward in the collected trajectories for process supervision, which we term Reward Rising Optimization (RRO). Specifically, we incrementally augment the process supervision until identifying a step exhibiting positive reward differentials, i.e. rising rewards, relative to its preceding iteration. This method dynamically expands the search space for the next action candidates, efficiently capturing high-quality data. We provide mathematical groundings and empirical results on the WebShop and InterCode-SQL benchmarks, showing that our proposed RRO achieves superior performance while requiring much less exploration cost.
Adversarial Generative Flow Network for Solving Vehicle Routing Problems
Mar 03, 2025Recent research into solving vehicle routing problems (VRPs) has gained significant traction, particularly through the application of deep (reinforcement) learning for end-to-end solution construction. However, many current construction-based neural solvers predominantly utilize Transformer architectures, which can face scalability challenges and struggle to produce diverse solutions. To address these limitations, we introduce a novel framework beyond Transformer-based approaches, i.e., Adversarial Generative Flow Networks (AGFN). This framework integrates the generative flow network (GFlowNet)-a probabilistic model inherently adept at generating diverse solutions (routes)-with a complementary model for discriminating (or evaluating) the solutions. These models are trained alternately in an adversarial manner to improve the overall solution quality, followed by a proposed hybrid decoding method to construct the solution. We apply the AGFN framework to solve the capacitated vehicle routing problem (CVRP) and travelling salesman problem (TSP), and our experimental results demonstrate that AGFN surpasses the popular construction-based neural solvers, showcasing strong generalization capabilities on synthetic and real-world benchmark instances.
END: Early Noise Dropping for Efficient and Effective Context Denoising
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, they are often distracted by irrelevant or noisy context in input sequences that degrades output quality. This problem affects both long- and short-context scenarios, such as retrieval-augmented generation, table question-answering, and in-context learning. We reveal that LLMs can implicitly identify whether input sequences contain useful information at early layers, prior to token generation. Leveraging this insight, we introduce Early Noise Dropping (\textsc{END}), a novel approach to mitigate this issue without requiring fine-tuning the LLMs. \textsc{END} segments input sequences into chunks and employs a linear prober on the early layers of LLMs to differentiate between informative and noisy chunks. By discarding noisy chunks early in the process, \textsc{END} preserves critical information, reduces distraction, and lowers computational overhead. Extensive experiments demonstrate that \textsc{END} significantly improves both performance and efficiency across different LLMs on multiple evaluation datasets. Furthermore, by investigating LLMs' implicit understanding to the input with the prober, this work also deepens understanding of how LLMs do reasoning with contexts internally.
Thinking Preference Optimization
Feb 17, 2025Supervised Fine-Tuning (SFT) has been a go-to and effective method for enhancing long chain-of-thought (CoT) reasoning in relatively small LLMs by fine-tuning them with long CoT responses from larger LLMs. To continually improve reasoning abilities, we can either collect new high-quality long CoT reasoning SFT data or repeatedly train on existing SFT datasets. However, acquiring new long CoT SFT data is costly and limited, while repeated training often results in a performance plateau or decline. To further boost the performance with the SFT data, we propose Thinking Preference Optimization (ThinkPO), a simple yet effective post-SFT method that enhances long CoT reasoning without requiring new long CoT responses. Instead, ThinkPO utilizes readily available or easily obtainable short CoT reasoning responses as rejected answers and long CoT responses as chosen answers for the same question. It then applies direct preference optimization to encourage the model to favor longer reasoning outputs. Experiments show that ThinkPO further improves the reasoning performance of SFT-ed models, e.g. it increases math reasoning accuracy of SFT-ed models by 8.6% and output length by 25.9%. Notably, ThinkPO is capable of continually boosting the performance of the publicly distilled SFT model, e.g., increasing the official DeepSeek-R1-Distill-Qwen-7B's performance on MATH500 from 87.4% to 91.2%.
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Scaling Laws for Predicting Downstream Performance in LLMs
Oct 11, 2024



Precise estimation of downstream performance in large language models (LLMs) prior to training is essential for guiding their development process. Scaling laws analysis utilizes the statistics of a series of significantly smaller sampling language models (LMs) to predict the performance of the target LLM. For downstream performance prediction, the critical challenge lies in the emergent abilities in LLMs that occur beyond task-specific computational thresholds. In this work, we focus on the pre-training loss as a more computation-efficient metric for performance estimation. Our two-stage approach consists of first estimating a function that maps computational resources (e.g., FLOPs) to the pre-training Loss using a series of sampling models, followed by mapping the pre-training loss to downstream task Performance after the critical "emergent phase". In preliminary experiments, this FLP solution accurately predicts the performance of LLMs with 7B and 13B parameters using a series of sampling LMs up to 3B, achieving error margins of 5% and 10%, respectively, and significantly outperforming the FLOPs-to-Performance approach. This motivates FLP-M, a fundamental approach for performance prediction that addresses the practical need to integrate datasets from multiple sources during pre-training, specifically blending general corpora with code data to accurately represent the common necessity. FLP-M extends the power law analytical function to predict domain-specific pre-training loss based on FLOPs across data sources, and employs a two-layer neural network to model the non-linear relationship between multiple domain-specific loss and downstream performance. By utilizing a 3B LLM trained on a specific ratio and a series of smaller sampling LMs, FLP-M can effectively forecast the performance of 3B and 7B LLMs across various data mixtures for most benchmarks within 10% error margins.
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Aug 07, 2024



Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.