 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving speaker verification robustness with synthetic emotional utterances
Nov 30, 2024



A speaker verification (SV) system offers an authentication service designed to confirm whether a given speech sample originates from a specific speaker. This technology has paved the way for various personalized applications that cater to individual preferences. A noteworthy challenge faced by SV systems is their ability to perform consistently across a range of emotional spectra. Most existing models exhibit high error rates when dealing with emotional utterances compared to neutral ones. Consequently, this phenomenon often leads to missing out on speech of interest. This issue primarily stems from the limited availability of labeled emotional speech data, impeding the development of robust speaker representations that encompass diverse emotional states. To address this concern, we propose a novel approach employing the CycleGAN framework to serve as a data augmentation method. This technique synthesizes emotional speech segments for each specific speaker while preserving the unique vocal identity. Our experimental findings underscore the effectiveness of incorporating synthetic emotional data into the training process. The models trained using this augmented dataset consistently outperform the baseline models on the task of verifying speakers in emotional speech scenarios, reducing equal error rate by as much as 3.64% relative.
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Aug 07, 2024



Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.
Coordinated Sparse Recovery of Label Noise
Apr 07, 2024Label noise is a common issue in real-world datasets that inevitably impacts the generalization of models. This study focuses on robust classification tasks where the label noise is instance-dependent. Estimating the transition matrix accurately in this task is challenging, and methods based on sample selection often exhibit confirmation bias to varying degrees. Sparse over-parameterized training (SOP) has been theoretically effective in estimating and recovering label noise, offering a novel solution for noise-label learning. However, this study empirically observes and verifies a technical flaw of SOP: the lack of coordination between model predictions and noise recovery leads to increased generalization error. To address this, we propose a method called Coordinated Sparse Recovery (CSR). CSR introduces a collaboration matrix and confidence weights to coordinate model predictions and noise recovery, reducing error leakage. Based on CSR, this study designs a joint sample selection strategy and constructs a comprehensive and powerful learning framework called CSR+. CSR+ significantly reduces confirmation bias, especially for datasets with more classes and a high proportion of instance-specific noise. Experimental results on simulated and real-world noisy datasets demonstrate that both CSR and CSR+ achieve outstanding performance compared to methods at the same level.
Towards Unified Multi-Modal Personalization: Large Vision-Language Models for Generative Recommendation and Beyond
Mar 27, 2024



Developing a universal model that can effectively harness heterogeneous resources and respond to a wide range of personalized needs has been a longstanding community aspiration. Our daily choices, especially in domains like fashion and retail, are substantially shaped by multi-modal data, such as pictures and textual descriptions. These modalities not only offer intuitive guidance but also cater to personalized user preferences. However, the predominant personalization approaches mainly focus on the ID or text-based recommendation problem, failing to comprehend the information spanning various tasks or modalities. In this paper, our goal is to establish a Unified paradigm for Multi-modal Personalization systems (UniMP), which effectively leverages multi-modal data while eliminating the complexities associated with task- and modality-specific customization. We argue that the advancements in foundational generative modeling have provided the flexibility and effectiveness necessary to achieve the objective. In light of this, we develop a generic and extensible personalization generative framework, that can handle a wide range of personalized needs including item recommendation, product search, preference prediction, explanation generation, and further user-guided image generation. Our methodology enhances the capabilities of foundational language models for personalized tasks by seamlessly ingesting interleaved cross-modal user history information, ensuring a more precise and customized experience for users. To train and evaluate the proposed multi-modal personalized tasks, we also introduce a novel and comprehensive benchmark covering a variety of user requirements. Our experiments on the real-world benchmark showcase the model's potential, outperforming competitive methods specialized for each task.
IterAlign: Iterative Constitutional Alignment of Large Language Models
Mar 27, 2024



With the rapid development of large language models (LLMs), aligning LLMs with human values and societal norms to ensure their reliability and safety has become crucial. Reinforcement learning with human feedback (RLHF) and Constitutional AI (CAI) have been proposed for LLM alignment. However, these methods require either heavy human annotations or explicitly pre-defined constitutions, which are labor-intensive and resource-consuming. To overcome these drawbacks, we study constitution-based LLM alignment and propose a data-driven constitution discovery and self-alignment framework called IterAlign. IterAlign leverages red teaming to unveil the weaknesses of an LLM and automatically discovers new constitutions using a stronger LLM. These constitutions are then used to guide self-correction of the base LLM. Such a constitution discovery pipeline can be run iteratively and automatically to discover new constitutions that specifically target the alignment gaps in the current LLM. Empirical results on several safety benchmark datasets and multiple base LLMs show that IterAlign successfully improves truthfulness, helpfulness, harmlessness and honesty, improving the LLM alignment by up to $13.5\%$ in harmlessness.
Language Models As Semantic Indexers
Oct 11, 2023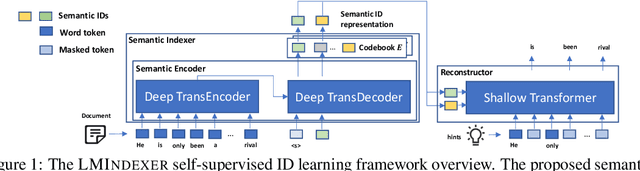
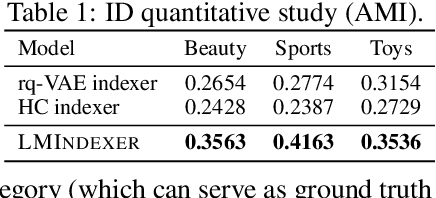
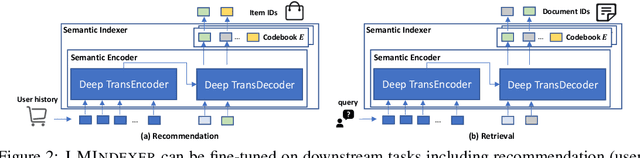

Semantic identifier (ID) is an important concept in information retrieval that aims to preserve the semantics of objects such as documents and items inside their IDs. Previous studies typically adopt a two-stage pipeline to learn semantic IDs by first procuring embeddings using off-the-shelf text encoders and then deriving IDs based on the embeddings. However, each step introduces potential information loss and there is usually an inherent mismatch between the distribution of embeddings within the latent space produced by text encoders and the anticipated distribution required for semantic indexing. Nevertheless, it is non-trivial to design a method that can learn the document's semantic representations and its hierarchical structure simultaneously, given that semantic IDs are discrete and sequentially structured, and the semantic supervision is deficient. In this paper, we introduce LMINDEXER, a self-supervised framework to learn semantic IDs with a generative language model. We tackle the challenge of sequential discrete ID by introducing a semantic indexer capable of generating neural sequential discrete representations with progressive training and contrastive learning. In response to the semantic supervision deficiency, we propose to train the model with a self-supervised document reconstruction objective. The learned semantic indexer can facilitate various downstream tasks, such as recommendation and retrieval. We conduct experiments on three tasks including recommendation, product search, and document retrieval on five datasets from various domains, where LMINDEXER outperforms competitive baselines significantly and consistently.
Amazon-M2: A Multilingual Multi-locale Shopping Session Dataset for Recommendation and Text Generation
Jul 19, 2023
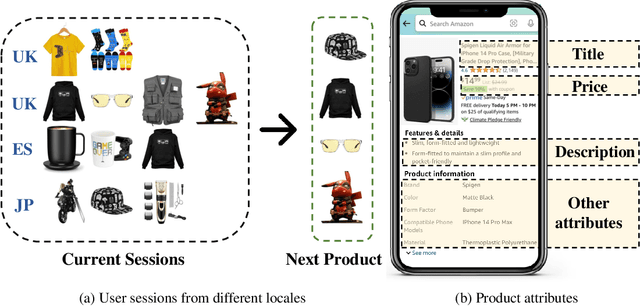
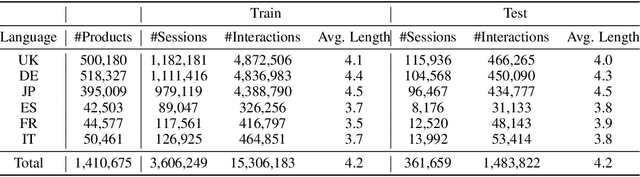
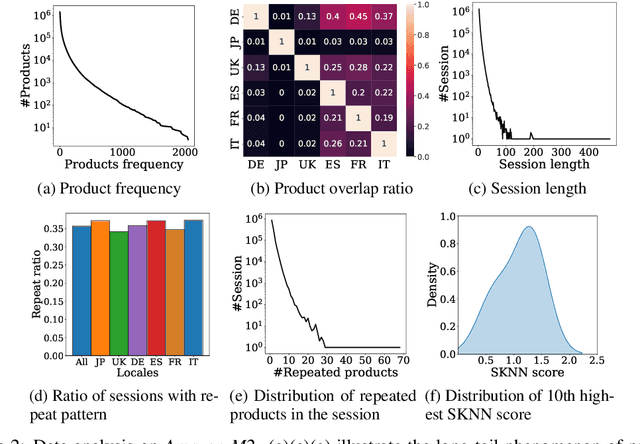
Modeling customer shopping intentions is a crucial task for e-commerce, as it directly impacts user experience and engagement. Thus, accurately understanding customer preferences is essential for providing personalized recommendations. Session-based recommendation, which utilizes customer session data to predict their next interaction, has become increasingly popular. However, existing session datasets have limitations in terms of item attributes, user diversity, and dataset scale. As a result, they cannot comprehensively capture the spectrum of user behaviors and preferences. To bridge this gap, we present the Amazon Multilingual Multi-locale Shopping Session Dataset, namely Amazon-M2. It is the first multilingual dataset consisting of millions of user sessions from six different locales, where the major languages of products are English, German, Japanese, French, Italian, and Spanish. Remarkably, the dataset can help us enhance personalization and understanding of user preferences, which can benefit various existing tasks as well as enable new tasks. To test the potential of the dataset, we introduce three tasks in this work: (1) next-product recommendation, (2) next-product recommendation with domain shifts, and (3) next-product title generation. With the above tasks, we benchmark a range of algorithms on our proposed dataset, drawing new insights for further research and practice. In addition, based on the proposed dataset and tasks, we hosted a competition in the KDD CUP 2023 and have attracted thousands of users and submissions. The winning solutions and the associated workshop can be accessed at our website https://kddcup23.github.io/.
Tucker Bilinear Attention Network for Multi-scale Remote Sensing Object Detection
Mar 09, 2023Object detection on VHR remote sensing images plays a vital role in applications such as urban planning, land resource management, and rescue missions. The large-scale variation of the remote-sensing targets is one of the main challenges in VHR remote-sensing object detection. Existing methods improve the detection accuracy of high-resolution remote sensing objects by improving the structure of feature pyramids and adopting different attention modules. However, for small targets, there still be seriously missed detections due to the loss of key detail features. There is still room for improvement in the way of multiscale feature fusion and balance. To address this issue, this paper proposes two novel modules: Guided Attention and Tucker Bilinear Attention, which are applied to the stages of early fusion and late fusion respectively. The former can effectively retain clean key detail features, and the latter can better balance features through semantic-level correlation mining. Based on two modules, we build a new multi-scale remote sensing object detection framework. No bells and whistles. The proposed method largely improves the average precisions of small objects and achieves the highest mean average precisions compared with 9 state-of-the-art methods on DOTA, DIOR, and NWPU VHR-10.Code and models are available at https://github.com/Shinichict/GTNet.
Recent Progress in Conversational AI
Apr 08, 2022Conversational artificial intelligence (AI) is becoming an increasingly popular topic among industry and academia. With the fast development of neural network-based models, a lot of neural-based conversational AI system are developed. We will provide a brief review of the recent progress in the Conversational AI, including the commonly adopted techniques, notable works, famous competitions from academia and industry and widely used datasets.
Agreement or Disagreement in Noise-tolerant Mutual Learning?
Mar 29, 2022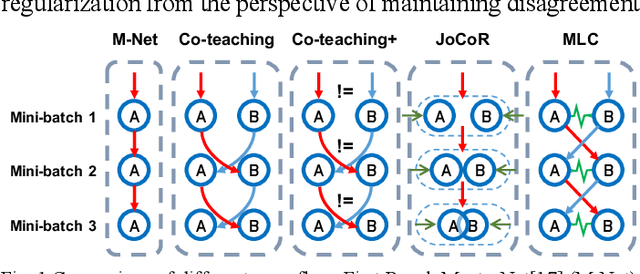
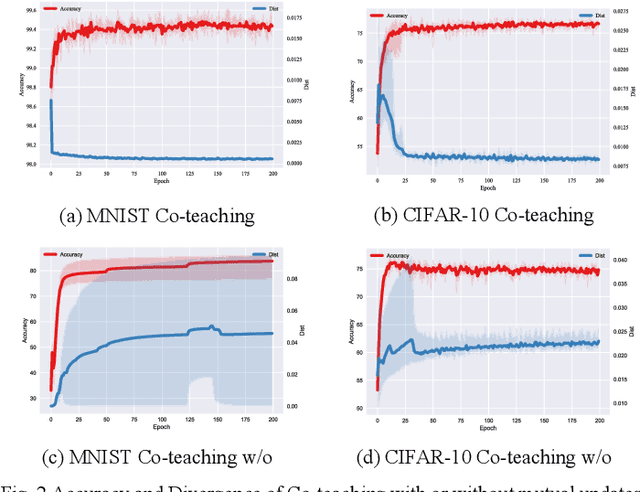
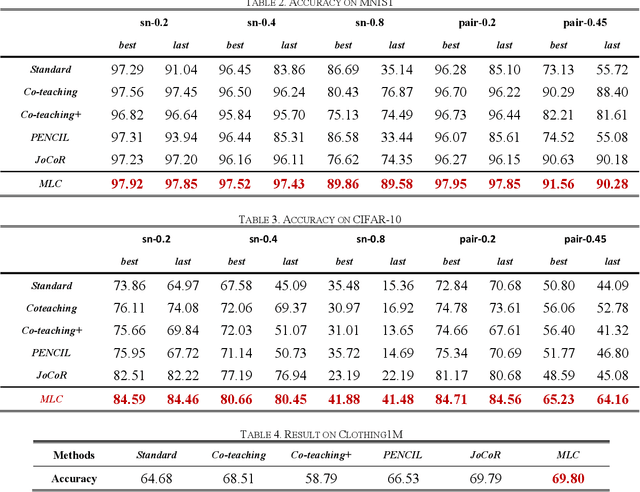
Deep learning has made many remarkable achievements in many fields but suffers from noisy labels in datasets. The state-of-the-art learning with noisy label method Co-teaching and Co-teaching+ confronts the noisy label by mutual-information between dual-network. However, the dual network always tends to convergent which would weaken the dual-network mechanism to resist the noisy labels. In this paper, we proposed a noise-tolerant framework named MLC in an end-to-end manner. It adjusts the dual-network with divergent regularization to ensure the effectiveness of the mechanism. In addition, we correct the label distribution according to the agreement between dual-networks. The proposed method can utilize the noisy data to improve the accuracy, generalization, and robustness of the network. We test the proposed method on the simulate noisy dataset MNIST, CIFAR-10, and the real-world noisy dataset Clothing1M. The experimental result shows that our method outperforms the previous state-of-the-art method. Besides, our method is network-free thus it is applicable to many tasks.