 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynPlanResearch-R1: Encouraging Tool Exploration for Deep Research with Synthetic Plans
Mar 09, 2026Research Agents enable models to gather information from the web using tools to answer user queries, requiring them to dynamically interleave internal reasoning with tool use. While such capabilities can in principle be learned via reinforcement learning with verifiable rewards (RLVR), we observe that agents often exhibit poor exploration behaviors, including premature termination and biased tool usage. As a result, RLVR alone yields limited improvements. We propose SynPlanResearch-R1, a framework that synthesizes tool-use trajectories that encourage deeper exploration to shape exploration during cold-start supervised fine-tuning, providing a strong initialization for subsequent RL. Across seven multi-hop and open-web benchmarks, \framework improves performance by up to 6.0% on Qwen3-8B and 5.8% on Qwen3-4B backbones respectively compared to SOTA baselines. Further analyses of tool-use patterns and training dynamics compared to baselines shed light on the factors underlying these gains. Our code is publicly available at https://github.com/HansiZeng/syn-plan-research.
TARSE: Test-Time Adaptation via Retrieval of Skills and Experience for Reasoning Agents
Mar 01, 2026Complex clinical decision making often fails not because a model lacks facts, but because it cannot reliably select and apply the right procedural knowledge and the right prior example at the right reasoning step. We frame clinical question answering as an agent problem with two explicit, retrievable resources: skills, reusable clinical procedures such as guidelines, protocols, and pharmacologic mechanisms; and experience, verified reasoning trajectories from previously solved cases (e.g., chain-of-thought solutions and their step-level decompositions). At test time, the agent retrieves both relevant skills and experiences from curated libraries and performs lightweight test-time adaptation to align the language model's intermediate reasoning with clinically valid logic. Concretely, we build (i) a skills library from guideline-style documents organized as executable decision rules, (ii) an experience library of exemplar clinical reasoning chains indexed by step-level transitions, and (iii) a step-aware retriever that selects the most useful skill and experience items for the current case. We then adapt the model on the retrieved items to reduce instance-step misalignment and to prevent reasoning from drifting toward unsupported shortcuts. Experiments on medical question-answering benchmarks show consistent gains over strong medical RAG baselines and prompting-only reasoning methods. Our results suggest that explicitly separating and retrieving clinical skills and experience, and then aligning the model at test time, is a practical approach to more reliable medical agents.
Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning
Jan 19, 2026Large Language Models (LLMs) have become a popular interface for human-AI interaction, supporting information seeking and task assistance through natural, multi-turn dialogue. To respond to users within multi-turn dialogues, the context-dependent user intent evolves across interactions, requiring contextual interpretation, query reformulation, and dynamic coordination between retrieval and generation. Existing studies usually follow static rewrite, retrieve, and generate pipelines, which optimize different procedures separately and overlook the mixed-initiative action optimization simultaneously. Although the recent developments in deep search agents demonstrate the effectiveness in jointly optimizing retrieval and generation via reasoning, these approaches focus on single-turn scenarios, which might lack the ability to handle multi-turn interactions. We introduce a conversational agent that interleaves search and reasoning across turns, enabling exploratory and adaptive behaviors learned through reinforcement learning (RL) training with tailored rewards towards evolving user goals. The experimental results across four widely used conversational benchmarks demonstrate the effectiveness of our methods by surpassing several existing strong baselines.
Can Pre-training Indicators Reliably Predict Fine-tuning Outcomes of LLMs?
Apr 16, 2025While metrics available during pre-training, such as perplexity, correlate well with model performance at scaling-laws studies, their predictive capacities at a fixed model size remain unclear, hindering effective model selection and development. To address this gap, we formulate the task of selecting pre-training checkpoints to maximize downstream fine-tuning performance as a pairwise classification problem: predicting which of two LLMs, differing in their pre-training, will perform better after supervised fine-tuning (SFT). We construct a dataset using 50 1B parameter LLM variants with systematically varied pre-training configurations, e.g., objectives or data, and evaluate them on diverse downstream tasks after SFT. We first conduct a study and demonstrate that the conventional perplexity is a misleading indicator. As such, we introduce novel unsupervised and supervised proxy metrics derived from pre-training that successfully reduce the relative performance prediction error rate by over 50%. Despite the inherent complexity of this task, we demonstrate the practical utility of our proposed proxies in specific scenarios, paving the way for more efficient design of pre-training schemes optimized for various downstream tasks.
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Mar 12, 2025Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Retrieval augmentation and tool-use training approaches where a search engine is treated as a tool lack complex multi-turn retrieval flexibility or require large-scale supervised data. Prompting advanced LLMs with reasoning capabilities during inference to use search engines is not optimal, since the LLM does not learn how to optimally interact with the search engine. This paper introduces Search-R1, an extension of the DeepSeek-R1 model where the LLM learns -- solely through reinforcement learning (RL) -- to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. Search-R1 optimizes LLM rollouts with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that Search-R1 improves performance by 26% (Qwen2.5-7B), 21% (Qwen2.5-3B), and 10% (LLaMA3.2-3B) over SOTA baselines. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/PeterGriffinJin/Search-R1.
ATEB: Evaluating and Improving Advanced NLP Tasks for Text Embedding Models
Feb 24, 2025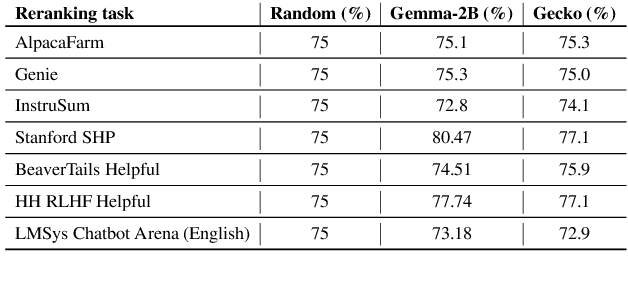
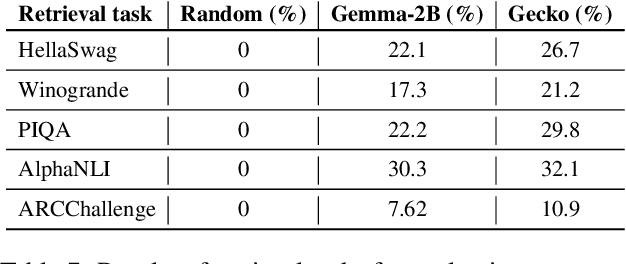
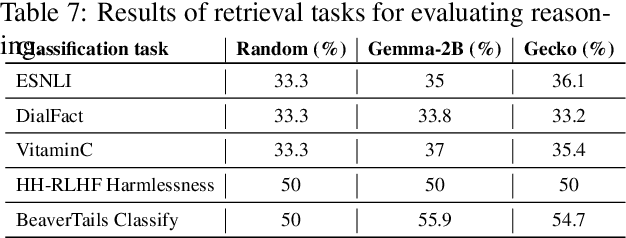

Traditional text embedding benchmarks primarily evaluate embedding models' capabilities to capture semantic similarity. However, more advanced NLP tasks require a deeper understanding of text, such as safety and factuality. These tasks demand an ability to comprehend and process complex information, often involving the handling of sensitive content, or the verification of factual statements against reliable sources. We introduce a new benchmark designed to assess and highlight the limitations of embedding models trained on existing information retrieval data mixtures on advanced capabilities, which include factuality, safety, instruction following, reasoning and document-level understanding. This benchmark includes a diverse set of tasks that simulate real-world scenarios where these capabilities are critical and leads to identification of the gaps of the currently advanced embedding models. Furthermore, we propose a novel method that reformulates these various tasks as retrieval tasks. By framing tasks like safety or factuality classification as retrieval problems, we leverage the strengths of retrieval models in capturing semantic relationships while also pushing them to develop a deeper understanding of context and content. Using this approach with single-task fine-tuning, we achieved performance gains of 8\% on factuality classification and 13\% on safety classification. Our code and data will be publicly available.
Scaling Sparse and Dense Retrieval in Decoder-Only LLMs
Feb 21, 2025Scaling large language models (LLMs) has shown great potential for improving retrieval model performance; however, previous studies have mainly focused on dense retrieval trained with contrastive loss (CL), neglecting the scaling behavior of other retrieval paradigms and optimization techniques, such as sparse retrieval and knowledge distillation (KD). In this work, we conduct a systematic comparative study on how different retrieval paradigms (sparse vs. dense) and fine-tuning objectives (CL vs. KD vs. their combination) affect retrieval performance across different model scales. Using MSMARCO passages as the training dataset, decoder-only LLMs (Llama-3 series: 1B, 3B, 8B), and a fixed compute budget, we evaluate various training configurations on both in-domain (MSMARCO, TREC DL) and out-of-domain (BEIR) benchmarks. Our key findings reveal that: (1) Scaling behaviors emerge clearly only with CL, where larger models achieve significant performance gains, whereas KD-trained models show minimal improvement, performing similarly across the 1B, 3B, and 8B scales. (2) Sparse retrieval models consistently outperform dense retrieval across both in-domain (MSMARCO, TREC DL) and out-of-domain (BEIR) benchmarks, and they demonstrate greater robustness to imperfect supervised signals. (3) We successfully scale sparse retrieval models with the combination of CL and KD losses at 8B scale, achieving state-of-the-art (SOTA) results in all evaluation sets.
Hypencoder: Hypernetworks for Information Retrieval
Feb 07, 2025



The vast majority of retrieval models depend on vector inner products to produce a relevance score between a query and a document. This naturally limits the expressiveness of the relevance score that can be employed. We propose a new paradigm, instead of producing a vector to represent the query we produce a small neural network which acts as a learned relevance function. This small neural network takes in a representation of the document, in this paper we use a single vector, and produces a scalar relevance score. To produce the little neural network we use a hypernetwork, a network that produce the weights of other networks, as our query encoder or as we call it a Hypencoder. Experiments on in-domain search tasks show that Hypencoder is able to significantly outperform strong dense retrieval models and has higher metrics then reranking models and models an order of magnitude larger. Hypencoder is also shown to generalize well to out-of-domain search tasks. To assess the extent of Hypencoder's capabilities, we evaluate on a set of hard retrieval tasks including tip-of-the-tongue retrieval and instruction-following retrieval tasks and find that the performance gap widens substantially compared to standard retrieval tasks. Furthermore, to demonstrate the practicality of our method we implement an approximate search algorithm and show that our model is able to search 8.8M documents in under 60ms.
Inference Scaling for Long-Context Retrieval Augmented Generation
Oct 06, 2024



The scaling of inference computation has unlocked the potential of long-context large language models (LLMs) across diverse settings. For knowledge-intensive tasks, the increased compute is often allocated to incorporate more external knowledge. However, without effectively utilizing such knowledge, solely expanding context does not always enhance performance. In this work, we investigate inference scaling for retrieval augmented generation (RAG), exploring strategies beyond simply increasing the quantity of knowledge. We focus on two inference scaling strategies: in-context learning and iterative prompting. These strategies provide additional flexibility to scale test-time computation (e.g., by increasing retrieved documents or generation steps), thereby enhancing LLMs' ability to effectively acquire and utilize contextual information. We address two key questions: (1) How does RAG performance benefit from the scaling of inference computation when optimally configured? (2) Can we predict the optimal test-time compute allocation for a given budget by modeling the relationship between RAG performance and inference parameters? Our observations reveal that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship we describe as the inference scaling laws for RAG. Building on this, we further develop the computation allocation model to estimate RAG performance across different inference configurations. The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. By applying these optimal configurations, we demonstrate that scaling inference compute on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.
Simulating Task-Oriented Dialogues with State Transition Graphs and Large Language Models
Apr 23, 2024This paper explores SynTOD, a new synthetic data generation approach for developing end-to-end Task-Oriented Dialogue (TOD) Systems capable of handling complex tasks such as intent classification, slot filling, conversational question-answering, and retrieval-augmented response generation, without relying on crowdsourcing or real-world data. SynTOD utilizes a state transition graph to define the desired behavior of a TOD system and generates diverse, structured conversations through random walks and response simulation using large language models (LLMs). In our experiments, using graph-guided response simulations leads to significant improvements in intent classification, slot filling and response relevance compared to naive single-prompt simulated conversations. We also investigate the end-to-end TOD effectiveness of different base and instruction-tuned LLMs, with and without the constructed synthetic conversations. Finally, we explore how various LLMs can evaluate responses in a TOD system and how well they are correlated with human judgments. Our findings pave the path towards quick development and evaluation of domain-specific TOD systems. We release our datasets, models, and code for research purposes.