 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Hybrid Latent Reasoning via Reinforcement Learning
May 24, 2025Recent advances in large language models (LLMs) have introduced latent reasoning as a promising alternative to autoregressive reasoning. By performing internal computation with hidden states from previous steps, latent reasoning benefit from more informative features rather than sampling a discrete chain-of-thought (CoT) path. Yet latent reasoning approaches are often incompatible with LLMs, as their continuous paradigm conflicts with the discrete nature of autoregressive generation. Moreover, these methods rely on CoT traces for training and thus fail to exploit the inherent reasoning patterns of LLMs. In this work, we explore latent reasoning by leveraging the intrinsic capabilities of LLMs via reinforcement learning (RL). To this end, we introduce hybrid reasoning policy optimization (HRPO), an RL-based hybrid latent reasoning approach that (1) integrates prior hidden states into sampled tokens with a learnable gating mechanism, and (2) initializes training with predominantly token embeddings while progressively incorporating more hidden features. This design maintains LLMs' generative capabilities and incentivizes hybrid reasoning using both discrete and continuous representations. In addition, the hybrid HRPO introduces stochasticity into latent reasoning via token sampling, thereby enabling RL-based optimization without requiring CoT trajectories. Extensive evaluations across diverse benchmarks show that HRPO outperforms prior methods in both knowledge- and reasoning-intensive tasks. Furthermore, HRPO-trained LLMs remain interpretable and exhibit intriguing behaviors like cross-lingual patterns and shorter completion lengths, highlighting the potential of our RL-based approach and offer insights for future work in latent reasoning.
Can Pre-training Indicators Reliably Predict Fine-tuning Outcomes of LLMs?
Apr 16, 2025While metrics available during pre-training, such as perplexity, correlate well with model performance at scaling-laws studies, their predictive capacities at a fixed model size remain unclear, hindering effective model selection and development. To address this gap, we formulate the task of selecting pre-training checkpoints to maximize downstream fine-tuning performance as a pairwise classification problem: predicting which of two LLMs, differing in their pre-training, will perform better after supervised fine-tuning (SFT). We construct a dataset using 50 1B parameter LLM variants with systematically varied pre-training configurations, e.g., objectives or data, and evaluate them on diverse downstream tasks after SFT. We first conduct a study and demonstrate that the conventional perplexity is a misleading indicator. As such, we introduce novel unsupervised and supervised proxy metrics derived from pre-training that successfully reduce the relative performance prediction error rate by over 50%. Despite the inherent complexity of this task, we demonstrate the practical utility of our proposed proxies in specific scenarios, paving the way for more efficient design of pre-training schemes optimized for various downstream tasks.
Integrating Planning into Single-Turn Long-Form Text Generation
Oct 08, 2024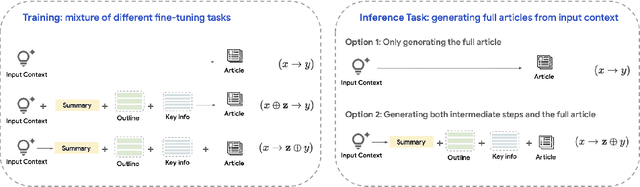

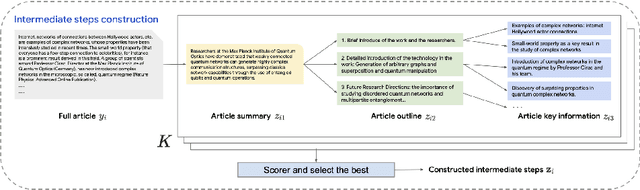
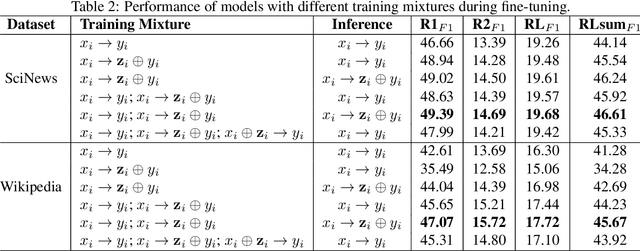
Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
Inference Scaling for Long-Context Retrieval Augmented Generation
Oct 06, 2024



The scaling of inference computation has unlocked the potential of long-context large language models (LLMs) across diverse settings. For knowledge-intensive tasks, the increased compute is often allocated to incorporate more external knowledge. However, without effectively utilizing such knowledge, solely expanding context does not always enhance performance. In this work, we investigate inference scaling for retrieval augmented generation (RAG), exploring strategies beyond simply increasing the quantity of knowledge. We focus on two inference scaling strategies: in-context learning and iterative prompting. These strategies provide additional flexibility to scale test-time computation (e.g., by increasing retrieved documents or generation steps), thereby enhancing LLMs' ability to effectively acquire and utilize contextual information. We address two key questions: (1) How does RAG performance benefit from the scaling of inference computation when optimally configured? (2) Can we predict the optimal test-time compute allocation for a given budget by modeling the relationship between RAG performance and inference parameters? Our observations reveal that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship we describe as the inference scaling laws for RAG. Building on this, we further develop the computation allocation model to estimate RAG performance across different inference configurations. The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. By applying these optimal configurations, we demonstrate that scaling inference compute on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.
Multimodal Reranking for Knowledge-Intensive Visual Question Answering
Jul 17, 2024



Knowledge-intensive visual question answering requires models to effectively use external knowledge to help answer visual questions. A typical pipeline includes a knowledge retriever and an answer generator. However, a retriever that utilizes local information, such as an image patch, may not provide reliable question-candidate relevance scores. Besides, the two-tower architecture also limits the relevance score modeling of a retriever to select top candidates for answer generator reasoning. In this paper, we introduce an additional module, a multi-modal reranker, to improve the ranking quality of knowledge candidates for answer generation. Our reranking module takes multi-modal information from both candidates and questions and performs cross-item interaction for better relevance score modeling. Experiments on OK-VQA and A-OKVQA show that multi-modal reranker from distant supervision provides consistent improvements. We also find a training-testing discrepancy with reranking in answer generation, where performance improves if training knowledge candidates are similar to or noisier than those used in testing.
Generating Diverse Criteria On-the-Fly to Improve Point-wise LLM Rankers
Apr 18, 2024The most recent pointwise Large Language Model (LLM) rankers have achieved remarkable ranking results. However, these rankers are hindered by two major drawbacks: (1) they fail to follow a standardized comparison guidance during the ranking process, and (2) they struggle with comprehensive considerations when dealing with complicated passages. To address these shortcomings, we propose to build a ranker that generates ranking scores based on a set of criteria from various perspectives. These criteria are intended to direct each perspective in providing a distinct yet synergistic evaluation. Our research, which examines eight datasets from the BEIR benchmark demonstrates that incorporating this multi-perspective criteria ensemble approach markedly enhanced the performance of pointwise LLM rankers.
Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
Apr 17, 2024



The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as ``How relevant is document A to query Q?", results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., ``Is document A more relevant than document B to query Q?". Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
Generate, Filter, and Fuse: Query Expansion via Multi-Step Keyword Generation for Zero-Shot Neural Rankers
Nov 15, 2023



Query expansion has been proved to be effective in improving recall and precision of first-stage retrievers, and yet its influence on a complicated, state-of-the-art cross-encoder ranker remains under-explored. We first show that directly applying the expansion techniques in the current literature to state-of-the-art neural rankers can result in deteriorated zero-shot performance. To this end, we propose GFF, a pipeline that includes a large language model and a neural ranker, to Generate, Filter, and Fuse query expansions more effectively in order to improve the zero-shot ranking metrics such as nDCG@10. Specifically, GFF first calls an instruction-following language model to generate query-related keywords through a reasoning chain. Leveraging self-consistency and reciprocal rank weighting, GFF further filters and combines the ranking results of each expanded query dynamically. By utilizing this pipeline, we show that GFF can improve the zero-shot nDCG@10 on BEIR and TREC DL 2019/2020. We also analyze different modelling choices in the GFF pipeline and shed light on the future directions in query expansion for zero-shot neural rankers.
PaRaDe: Passage Ranking using Demonstrations with Large Language Models
Oct 22, 2023



Recent studies show that large language models (LLMs) can be instructed to effectively perform zero-shot passage re-ranking, in which the results of a first stage retrieval method, such as BM25, are rated and reordered to improve relevance. In this work, we improve LLM-based re-ranking by algorithmically selecting few-shot demonstrations to include in the prompt. Our analysis investigates the conditions where demonstrations are most helpful, and shows that adding even one demonstration is significantly beneficial. We propose a novel demonstration selection strategy based on difficulty rather than the commonly used semantic similarity. Furthermore, we find that demonstrations helpful for ranking are also effective at question generation. We hope our work will spur more principled research into question generation and passage ranking.