 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComBench: A Benchmark for Rigorous Proof Reasoning and Constructive Realization in Olympiad-Level Combinatorics
Jun 09, 2026Combinatorics is central to Olympiad-level mathematical problem solving, requiring deep discrete reasoning, creative constructions, and rigorous structural insight. Recent evidence suggests that even today's strongest frontier models remain uneven on Olympiad combinatorics, revealing a gap in creative mathematical reasoning. We introduce ComBench, an Olympiad-level combinatorics benchmark for evaluating and diagnosing the combinatorial reasoning capabilities of large language models. ComBench contains 100 human-annotated competition-level problems organized around two complementary settings: analysis-centric problems, which primarily require rigorous mathematical arguments, and construction-centric problems, which require explicit constructions in addition to correctness justifications. The evaluation protocol combines rubric-guided proof grading with deterministic construction verification, exposing cases where proof quality and construction validity diverge. Experiments on frontier open- and closed-source models show that ComBench is far from saturated: the strongest model reaches 65.4% overall Avg. and 75.3% overall Best@4. We further find that Rigorous Proof Reasoning and Constructive Realization are distinct capabilities: Kimi-K2.6 trails GPT-5.5 on analysis-centric proof grading but surpasses it on construction-centric Best@4, while Existence and Construction problems remain consistently hardest across representative frontier models.
Draft-OPD: On-Policy Distillation for Speculative Draft Models
May 28, 2026Speculative decoding accelerates large language model inference by pairing a target model with a lightweight draft model whose proposed tokens are verified in parallel. A common way to build draft models, like EAGLE3 or DFlash is supervised fine-tuning (SFT) on target-generated trajectories. However, we observe that SFT quickly plateaus: the draft model's acceptance length on test data stops improving. The reason is an offline-to-inference mismatch: In SFT, the drafter learns from fixed target-generated trajectories, whereas during speculative decoding it is evaluated on blocks proposed under its own policy. This motivates on-policy distillation (OPD), where the target model supervises the drafter on draft-induced states. Yet OPD remains difficult for draft models, as they cannot reliably roll out complete sequences independently, whereas target-assisted generation makes the collected sequences follow the target distribution and thus eliminates the on-policy signal. We therefore propose Draft-OPD, which uses target-assisted rollout for stable continuations and replays drafting from the verification-exposed error positions. This allows the drafter to learn from target feedback on both accepted and rejected proposals, focusing training on the draft-induced errors that limit speculative acceptance. Experiments show that Draft-OPD achieves over $5\times$ lossless acceleration for thinking models across diverse tasks, improving over EAGLE-3 and DFlash by 23\% and 13\%.
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
May 13, 2026Recent progress in reasoning models has substantially advanced long-horizon mathematical and scientific problem solving, with several systems now reaching gold-medal-level performance on International Mathematical Olympiad (IMO) and International Physics Olympiad (IPhO) problems. In this paper, we introduce a simple and unified recipe for converting a post-trained reasoning backbone into a rigorous olympiad-level solver. The recipe first uses a reverse-perplexity curriculum for SFT to instill rigorous proof-search and self-checking behaviors, then scales these behaviors through a two-stage RL pipeline that progresses from RL with verifiable rewards to more delicate proof-level RL, and finally boosts solving performance with test-time scaling. Applying this recipe, we train a 30B-A3B backbone with SFT on around 340K sub-8K-token trajectories followed by 200 RL steps. The resulting model, SU-01, supports stable reasoning on difficult problems with trajectories exceeding 100K tokens, while achieving gold-medal-level performance on mathematical and physical olympiad competitions, including IMO 2025/USAMO 2026 and IPhO 2024/2025. It also demonstrates strong generalization of scientific reasoning to domains beyond mathematics and physics.
Teaching Thinking Models to Reason with Tools: A Full-Pipeline Recipe for Tool-Integrated Reasoning
May 07, 2026Tool-integrated reasoning (TIR) offers a direct way to extend thinking models beyond the limits of text-only reasoning. Paradoxically, we observe that tool-enabled evaluation can degrade reasoning performance even when the strong thinking models make almost no actual tool calls. In this paper, we investigate how to inject natural tool-use behavior into a strong thinking model without sacrificing its no-tool reasoning ability, and present a comprehensive TIR recipe. We highlight that (i) the effectiveness of TIR supervised fine-tuning (SFT) hinges on the learnability of teacher trajectories, which should prioritize problems inherently suited for tool-augmented solutions; (ii) controlling the proportion of tool-use trajectories could mitigate the catastrophic forgetting of text-only reasoning capacity; (iii) optimizing for pass@k and response length instead of training loss could maximize TIR SFT gains while preserving headroom for reinforcement learning (RL) exploration; (iv) a stable RL with verifiable rewards (RLVR) stage, built upon suitable SFT initialization and explicit safeguards against mode collapse, provides a simple yet remarkably effective solution. When applied to Qwen3 thinking models at 4B and 30B scales, our recipe yields models that achieve state-of-the-art performance in a wide range of benchmarks among open-source models, such as 96.7% and 99.2% on AIME 2025 for 4B and 30B, respectively.
TEMPO: Scaling Test-time Training for Large Reasoning Models
Apr 21, 2026Test-time training (TTT) adapts model parameters on unlabeled test instances during inference time, which continuously extends capabilities beyond the reach of offline training. Despite initial gains, existing TTT methods for LRMs plateau quickly and do not benefit from additional test-time compute. Without external calibration, the self-generated reward signal increasingly drifts as the policy model evolves, leading to both performance plateaus and diversity collapse. We propose TEMPO, a TTT framework that interleaves policy refinement on unlabeled questions with periodic critic recalibration on a labeled dataset. By formalizing this alternating procedure through the Expectation-Maximization (EM) algorithm, we reveal that prior methods can be interpreted as incomplete variants that omit the crucial recalibration step. Reintroducing this step tightens the evidence lower bound (ELBO) and enables sustained improvement. Across diverse model families (Qwen3 and OLMO3) and reasoning tasks, TEMPO improves OLMO3-7B on AIME 2024 from 33.0% to 51.1% and Qwen3-14B from 42.3% to 65.8%, while maintaining high diversity.
Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning
Feb 12, 2026Achieving effective test-time scaling requires models to engage in In-Context Exploration -- the intrinsic ability to generate, verify, and refine multiple reasoning hypotheses within a single continuous context. Grounded in State Coverage theory, our analysis identifies a critical bottleneck to enabling this capability: while broader state coverage requires longer reasoning trajectories, the probability of sampling such sequences decays exponentially during autoregressive generation, a phenomenon we term the ``Shallow Exploration Trap''. To bridge this gap, we propose Length-Incentivized Exploration(\method). This simple yet effective recipe explicitly encourages models to explore more via a length-based reward coupled with a redundancy penalty, thereby maximizing state coverage in two-step manner. Comprehensive experiments across different models (Qwen3, Llama) demonstrate that \method effectively incentivize in-context exploration. As a result, our method achieves an average improvement of 4.4\% on in-domain tasks and a 2.7\% gain on out-of-domain benchmarks.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
HiPhO: How Far Are (M)LLMs from Humans in the Latest High School Physics Olympiad Benchmark?
Sep 10, 2025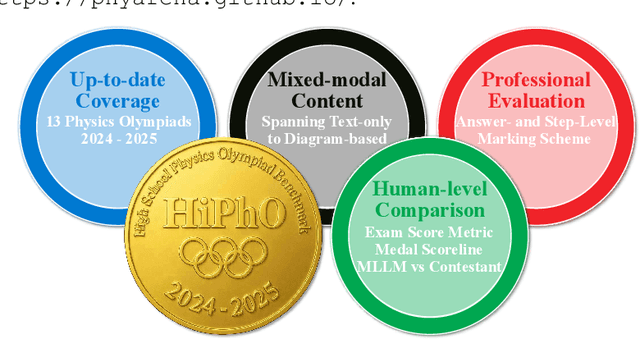

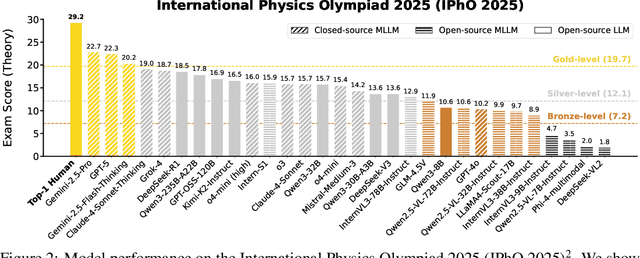

Recently, the physical capabilities of (M)LLMs have garnered increasing attention. However, existing benchmarks for physics suffer from two major gaps: they neither provide systematic and up-to-date coverage of real-world physics competitions such as physics Olympiads, nor enable direct performance comparison with humans. To bridge these gaps, we present HiPhO, the first benchmark dedicated to high school physics Olympiads with human-aligned evaluation. Specifically, HiPhO highlights three key innovations. (1) Comprehensive Data: It compiles 13 latest Olympiad exams from 2024-2025, spanning both international and regional competitions, and covering mixed modalities that encompass problems spanning text-only to diagram-based. (2) Professional Evaluation: We adopt official marking schemes to perform fine-grained grading at both the answer and step level, fully aligned with human examiners to ensure high-quality and domain-specific evaluation. (3) Comparison with Human Contestants: We assign gold, silver, and bronze medals to models based on official medal thresholds, thereby enabling direct comparison between (M)LLMs and human contestants. Our large-scale evaluation of 30 state-of-the-art (M)LLMs shows that: across 13 exams, open-source MLLMs mostly remain at or below the bronze level; open-source LLMs show promising progress with occasional golds; closed-source reasoning MLLMs can achieve 6 to 12 gold medals; and most models still have a significant gap from full marks. These results highlight a substantial performance gap between open-source models and top students, the strong physical reasoning capabilities of closed-source reasoning models, and the fact that there is still significant room for improvement. HiPhO, as a rigorous, human-aligned, and Olympiad-focused benchmark for advancing multimodal physical reasoning, is open-source and available at https://github.com/SciYu/HiPhO.
Synthesizing Sheet Music Problems for Evaluation and Reinforcement Learning
Sep 04, 2025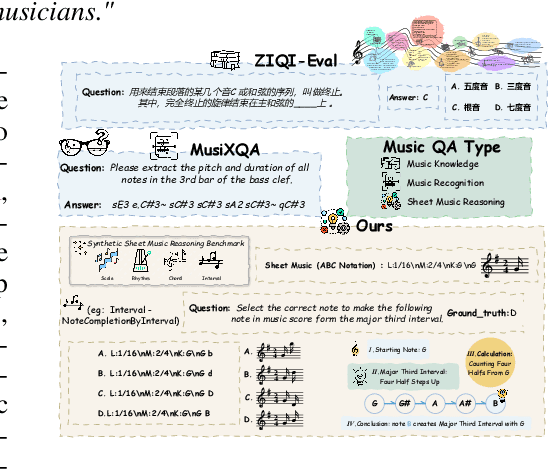

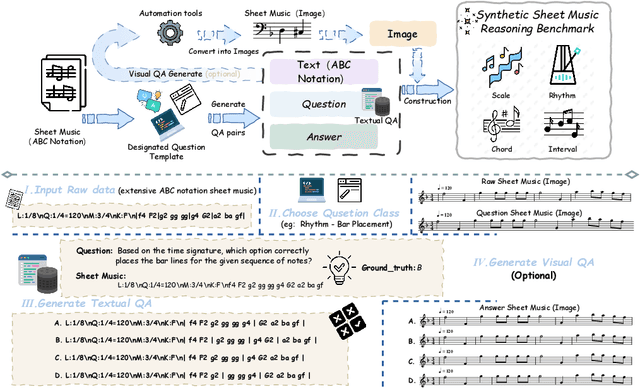
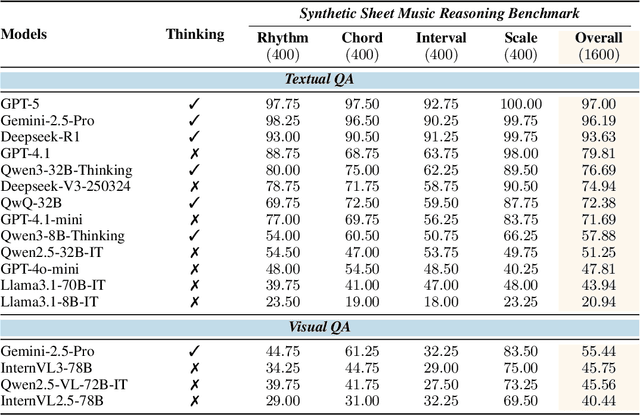
Enhancing the ability of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) to interpret sheet music is a crucial step toward building AI musicians. However, current research lacks both evaluation benchmarks and training data for sheet music reasoning. To address this, we propose the idea of synthesizing sheet music problems grounded in music theory, which can serve both as evaluation benchmarks and as training data for reinforcement learning with verifiable rewards (RLVR). We introduce a data synthesis framework that generates verifiable sheet music questions in both textual and visual modalities, leading to the Synthetic Sheet Music Reasoning Benchmark (SSMR-Bench) and a complementary training set. Evaluation results on SSMR-Bench show the importance of models' reasoning abilities in interpreting sheet music. At the same time, the poor performance of Gemini 2.5-Pro highlights the challenges that MLLMs still face in interpreting sheet music in a visual format. By leveraging synthetic data for RLVR, Qwen3-8B-Base and Qwen2.5-VL-Instruct achieve improvements on the SSMR-Bench. Besides, the trained Qwen3-8B-Base surpasses GPT-4 in overall performance on MusicTheoryBench and achieves reasoning performance comparable to GPT-4 with the strategies of Role play and Chain-of-Thought. Notably, its performance on math problems also improves relative to the original Qwen3-8B-Base. Furthermore, our results show that the enhanced reasoning ability can also facilitate music composition. In conclusion, we are the first to propose the idea of synthesizing sheet music problems based on music theory rules, and demonstrate its effectiveness not only in advancing model reasoning for sheet music understanding but also in unlocking new possibilities for AI-assisted music creation.