 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCollab: A Self-Evaluation-Driven Collaboration Paradigm for Efficient LLM Agents
Mar 27, 2026Autonomous agents powered by large language models (LLMs) perform complex tasks through long-horizon reasoning and tool interaction, where a fundamental trade-off arises between execution efficiency and reasoning robustness. Models at different capability-cost levels offer complementary advantages: lower-cost models enable fast execution but may struggle on difficult reasoning segments, while stronger models provide more robust reasoning at higher computational cost. We present AgentCollab, a self-driven collaborative inference framework that dynamically coordinates models with different reasoning capacities during agent execution. Instead of relying on external routing modules, the framework uses the agent's own self-reflection signal to determine whether the current reasoning trajectory is making meaningful progress, and escalates control to a stronger reasoning tier only when necessary. To further stabilize long-horizon execution, we introduce a difficulty-aware cumulative escalation strategy that allocates additional reasoning budget based on recent failure signals. In our experiments, we instantiate this framework using a two-level small-large model setting. Experiments on diverse multi-step agent benchmarks show that AgentCollab consistently improves the accuracy-efficiency Pareto frontier of LLM agents.
VERA: Identifying and Leveraging Visual Evidence Retrieval Heads in Long-Context Understanding
Feb 09, 2026While Vision-Language Models (VLMs) have shown promise in textual understanding, they face significant challenges when handling long context and complex reasoning tasks. In this paper, we dissect the internal mechanisms governing long-context processing in VLMs to understand their performance bottlenecks. Through the lens of attention analysis, we identify specific Visual Evidence Retrieval (VER) Heads - a sparse, dynamic set of attention heads critical for locating visual cues during reasoning, distinct from static OCR heads. We demonstrate that these heads are causal to model performance; masking them leads to significant degradation. Leveraging this discovery, we propose VERA (Visual Evidence Retrieval Augmentation), a training-free framework that detects model uncertainty (i.e., entropy) to trigger the explicit verbalization of visual evidence attended by VER heads. Comprehensive experiments demonstrate that VERA significantly improves long-context understanding of open-source VLMs: it yields an average relative improvement of 21.3% on Qwen3-VL-8B-Instruct and 20.1% on GLM-4.1V-Thinking across five benchmarks.
PerSphere: A Comprehensive Framework for Multi-Faceted Perspective Retrieval and Summarization
Dec 17, 2024



As online platforms and recommendation algorithms evolve, people are increasingly trapped in echo chambers, leading to biased understandings of various issues. To combat this issue, we have introduced PerSphere, a benchmark designed to facilitate multi-faceted perspective retrieval and summarization, thus breaking free from these information silos. For each query within PerSphere, there are two opposing claims, each supported by distinct, non-overlapping perspectives drawn from one or more documents. Our goal is to accurately summarize these documents, aligning the summaries with the respective claims and their underlying perspectives. This task is structured as a two-step end-to-end pipeline that includes comprehensive document retrieval and multi-faceted summarization. Furthermore, we propose a set of metrics to evaluate the comprehensiveness of the retrieval and summarization content. Experimental results on various counterparts for the pipeline show that recent models struggle with such a complex task. Analysis shows that the main challenge lies in long context and perspective extraction, and we propose a simple but effective multi-agent summarization system, offering a promising solution to enhance performance on PerSphere.
Mediating Modes of Thought: LLM's for design scripting
Nov 20, 2024


Here is an updated version of your abstract, cleaned for submission to arXiv with potential "bad characters" corrected to conform to ASCII standards: Architects adopt visual scripting and parametric design tools to explore more expansive design spaces (Coates, 2010), refine their thinking about the geometric logic of their design (Woodbury, 2010), and overcome conventional software limitations (Burry, 2011). Despite two decades of effort to make design scripting more accessible, a disconnect between a designer's free ways of thinking and the rigidity of algorithms remains (Burry, 2011). Recent developments in Large Language Models (LLMs) suggest this might soon change, as LLMs encode a general understanding of human context and exhibit the capacity to produce geometric logic. This project speculates that if LLMs can effectively mediate between user intent and algorithms, they become a powerful tool to make scripting in design more widespread and fun. We explore if such systems can interpret natural language prompts to assemble geometric operations relevant to computational design scripting. In the system, multiple layers of LLM agents are configured with specific context to infer the user intent and construct a sequential logic. Given a user's high-level text prompt, a geometric description is created, distilled into a sequence of logic operations, and mapped to software-specific commands. The completed script is constructed in the user's visual programming interface. The system succeeds in generating complete visual scripts up to a certain complexity but fails beyond this complexity threshold. It shows how LLMs can make design scripting much more aligned with human creativity and thought. Future research should explore conversational interactions, expand to multimodal inputs and outputs, and assess the performance of these tools.
Generating Diverse Criteria On-the-Fly to Improve Point-wise LLM Rankers
Apr 18, 2024



The most recent pointwise Large Language Model (LLM) rankers have achieved remarkable ranking results. However, these rankers are hindered by two major drawbacks: (1) they fail to follow a standardized comparison guidance during the ranking process, and (2) they struggle with comprehensive considerations when dealing with complicated passages. To address these shortcomings, we propose to build a ranker that generates ranking scores based on a set of criteria from various perspectives. These criteria are intended to direct each perspective in providing a distinct yet synergistic evaluation. Our research, which examines eight datasets from the BEIR benchmark demonstrates that incorporating this multi-perspective criteria ensemble approach markedly enhanced the performance of pointwise LLM rankers.
XAL: EXplainable Active Learning Makes Classifiers Better Low-resource Learners
Oct 09, 2023Active learning aims to construct an effective training set by iteratively curating the most informative unlabeled data for annotation, which is practical in low-resource tasks. Most active learning techniques in classification rely on the model's uncertainty or disagreement to choose unlabeled data. However, previous work indicates that existing models are poor at quantifying predictive uncertainty, which can lead to over-confidence in superficial patterns and a lack of exploration. Inspired by the cognitive processes in which humans deduce and predict through causal information, we propose a novel Explainable Active Learning framework (XAL) for low-resource text classification, which aims to encourage classifiers to justify their inferences and delve into unlabeled data for which they cannot provide reasonable explanations. Specifically, besides using a pre-trained bi-directional encoder for classification, we employ a pre-trained uni-directional decoder to generate and score the explanation. A ranking loss is proposed to enhance the decoder's capability in scoring explanations. During the selection of unlabeled data, we combine the predictive uncertainty of the encoder and the explanation score of the decoder to acquire informative data for annotation. As XAL is a general framework for text classification, we test our methods on six different classification tasks. Extensive experiments show that XAL achieves substantial improvement on all six tasks over previous AL methods. Ablation studies demonstrate the effectiveness of each component, and human evaluation shows that the model trained in XAL performs surprisingly well in explaining its prediction.
Mere Contrastive Learning for Cross-Domain Sentiment Analysis
Aug 18, 2022

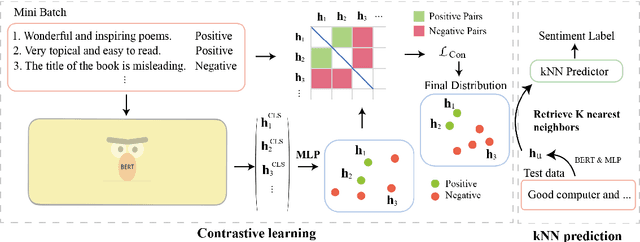

Cross-domain sentiment analysis aims to predict the sentiment of texts in the target domain using the model trained on the source domain to cope with the scarcity of labeled data. Previous studies are mostly cross-entropy-based methods for the task, which suffer from instability and poor generalization. In this paper, we explore contrastive learning on the cross-domain sentiment analysis task. We propose a modified contrastive objective with in-batch negative samples so that the sentence representations from the same class will be pushed close while those from the different classes become further apart in the latent space. Experiments on two widely used datasets show that our model can achieve state-of-the-art performance in both cross-domain and multi-domain sentiment analysis tasks. Meanwhile, visualizations demonstrate the effectiveness of transferring knowledge learned in the source domain to the target domain and the adversarial test verifies the robustness of our model.
Unsupervised Key Event Detection from Massive Text Corpora
Jun 08, 2022



Automated event detection from news corpora is a crucial task towards mining fast-evolving structured knowledge. As real-world events have different granularities, from the top-level themes to key events and then to event mentions corresponding to concrete actions, there are generally two lines of research: (1) theme detection identifies from a news corpus major themes (e.g., "2019 Hong Kong Protests" vs. "2020 U.S. Presidential Election") that have very distinct semantics; and (2) action extraction extracts from one document mention-level actions (e.g., "the police hit the left arm of the protester") that are too fine-grained for comprehending the event. In this paper, we propose a new task, key event detection at the intermediate level, aiming to detect from a news corpus key events (e.g., "HK Airport Protest on Aug. 12-14"), each happening at a particular time/location and focusing on the same topic. This task can bridge event understanding and structuring and is inherently challenging because of the thematic and temporal closeness of key events and the scarcity of labeled data due to the fast-evolving nature of news articles. To address these challenges, we develop an unsupervised key event detection framework, EvMine, that (1) extracts temporally frequent peak phrases using a novel ttf-itf score, (2) merges peak phrases into event-indicative feature sets by detecting communities from our designed peak phrase graph that captures document co-occurrences, semantic similarities, and temporal closeness signals, and (3) iteratively retrieves documents related to each key event by training a classifier with automatically generated pseudo labels from the event-indicative feature sets and refining the detected key events using the retrieved documents. Extensive experiments and case studies show EvMine outperforms all the baseline methods and its ablations on two real-world news corpora.
Weakly-Supervised Aspect-Based Sentiment Analysis via Joint Aspect-Sentiment Topic Embedding
Oct 13, 2020



Aspect-based sentiment analysis of review texts is of great value for understanding user feedback in a fine-grained manner. It has in general two sub-tasks: (i) extracting aspects from each review, and (ii) classifying aspect-based reviews by sentiment polarity. In this paper, we propose a weakly-supervised approach for aspect-based sentiment analysis, which uses only a few keywords describing each aspect/sentiment without using any labeled examples. Existing methods are either designed only for one of the sub-tasks, neglecting the benefit of coupling both, or are based on topic models that may contain overlapping concepts. We propose to first learn <sentiment, aspect> joint topic embeddings in the word embedding space by imposing regularizations to encourage topic distinctiveness, and then use neural models to generalize the word-level discriminative information by pre-training the classifiers with embedding-based predictions and self-training them on unlabeled data. Our comprehensive performance analysis shows that our method generates quality joint topics and outperforms the baselines significantly (7.4% and 5.1% F1-score gain on average for aspect and sentiment classification respectively) on benchmark datasets. Our code and data are available at https://github.com/teapot123/JASen.
User-Guided Aspect Classification for Domain-Specific Texts
Apr 30, 2020


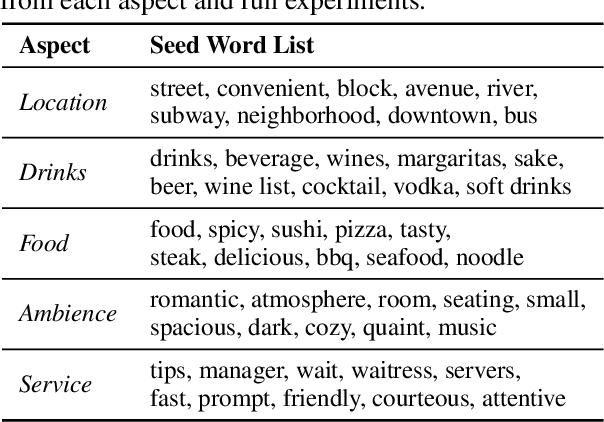
Aspect classification, identifying aspects of text segments, facilitates numerous applications, such as sentiment analysis and review summarization. To alleviate the human effort on annotating massive texts, in this paper, we study the problem of classifying aspects based on only a few user-provided seed words for pre-defined aspects. The major challenge lies in how to handle the noisy misc aspect, which is designed for texts without any pre-defined aspects. Even domain experts have difficulties to nominate seed words for the misc aspect, making existing seed-driven text classification methods not applicable. We propose a novel framework, ARYA, which enables mutual enhancements between pre-defined aspects and the misc aspect via iterative classifier training and seed updating. Specifically, it trains a classifier for pre-defined aspects and then leverages it to induce the supervision for the misc aspect. The prediction results of the misc aspect are later utilized to filter out noisy seed words for pre-defined aspects. Experiments in two domains demonstrate the superior performance of our proposed framework, as well as the necessity and importance of properly modeling the misc aspect.