 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbRes: Volatility Learning for Probabilistic Time-Series Forecasting
Jun 01, 2026Probabilistic time series forecasting has attracted increasing attention in financial applications due to the need to quantify risk and uncertainty in future observations. We propose ProbRes, a post-hoc probabilistic calibration method that explicitly learns and incorporates volatility dynamics into probabilistic forecasting, enabling effective handling of heteroskedastic data. During training, ProbRes employs two architecture-agnostic modules to separately model the conditional mean and conditional volatility. At the inference stage, it generates predictive distributions by resampling normalized residuals. ProbRes is applicable to both univariate and multivariate time series and remains robust under a wide range of error distributions, including non-Gaussian innovations with conditional heteroskedasticity. Theoretical results demonstrate ProbRes's validity and experiments on both synthetic and real-world datasets show that ProbRes accurately captures predictive distributions and produces well-calibrated prediction intervals.
Scalable Prompt Routing via Fine-Grained Latent Task Discovery
Mar 23, 2026Prompt routing dynamically selects the most appropriate large language model from a pool of candidates for each query, optimizing performance while managing costs. As model pools scale to include dozens of frontier models with narrow performance gaps, existing approaches face significant challenges: manually defined task taxonomies cannot capture fine-grained capability distinctions, while monolithic routers struggle to differentiate subtle differences across diverse tasks. We propose a two-stage routing architecture that addresses these limitations through automated fine-grained task discovery and task-aware quality estimation. Our first stage employs graph-based clustering to discover latent task types and trains a classifier to assign prompts to discovered tasks. The second stage uses a mixture-of-experts architecture with task-specific prediction heads for specialized quality estimates. At inference, we aggregate predictions from both stages to balance task-level stability with prompt-specific adaptability. Evaluated on 10 benchmarks with 11 frontier models, our method consistently outperforms existing baselines and surpasses the strongest individual model while incurring less than half its cost.
Train Less, Learn More: Adaptive Efficient Rollout Optimization for Group-Based Reinforcement Learning
Feb 15, 2026Reinforcement learning (RL) plays a central role in large language model (LLM) post-training. Among existing approaches, Group Relative Policy Optimization (GRPO) is widely used, especially for RL with verifiable rewards (RLVR) fine-tuning. In GRPO, each query prompts the LLM to generate a group of rollouts with a fixed group size $N$. When all rollouts in a group share the same outcome, either all correct or all incorrect, the group-normalized advantages become zero, yielding no gradient signal and wasting fine-tuning compute. We introduce Adaptive Efficient Rollout Optimization (AERO), an enhancement of GRPO. AERO uses an adaptive rollout strategy, applies selective rejection to strategically prune rollouts, and maintains a Bayesian posterior to prevent zero-advantage dead zones. Across three model configurations (Qwen2.5-Math-1.5B, Qwen2.5-7B, and Qwen2.5-7B-Instruct), AERO improves compute efficiency without sacrificing performance. Under the same total rollout budget, AERO reduces total training compute by about 48% while shortening wall-clock time per step by about 45% on average. Despite the substantial reduction in compute, AERO matches or improves Pass@8 and Avg@8 over GRPO, demonstrating a practical, scalable, and compute-efficient strategy for RL-based LLM alignment.
Grounding Agent Memory in Contextual Intent
Jan 15, 2026Deploying large language models in long-horizon, goal-oriented interactions remains challenging because similar entities and facts recur under different latent goals and constraints, causing memory systems to retrieve context-mismatched evidence. We propose STITCH (Structured Intent Tracking in Contextual History), an agentic memory system that indexes each trajectory step with a structured retrieval cue, contextual intent, and retrieves history by matching the current step's intent. Contextual intent provides compact signals that disambiguate repeated mentions and reduce interference: (1) the current latent goal defining a thematic segment, (2) the action type, and (3) the salient entity types anchoring which attributes matter. During inference, STITCH filters and prioritizes memory snippets by intent compatibility, suppressing semantically similar but context-incompatible history. For evaluation, we introduce CAME-Bench, a benchmark for context-aware retrieval in realistic, dynamic, goal-oriented trajectories. Across CAME-Bench and LongMemEval, STITCH achieves state-of-the-art performance, outperforming the strongest baseline by 35.6%, with the largest gains as trajectory length increases. Our analysis shows that intent indexing substantially reduces retrieval noise, supporting intent-aware memory for robust long-horizon reasoning.
TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora
Jun 12, 2025The rapid evolution of scientific fields introduces challenges in organizing and retrieving scientific literature. While expert-curated taxonomies have traditionally addressed this need, the process is time-consuming and expensive. Furthermore, recent automatic taxonomy construction methods either (1) over-rely on a specific corpus, sacrificing generalizability, or (2) depend heavily on the general knowledge of large language models (LLMs) contained within their pre-training datasets, often overlooking the dynamic nature of evolving scientific domains. Additionally, these approaches fail to account for the multi-faceted nature of scientific literature, where a single research paper may contribute to multiple dimensions (e.g., methodology, new tasks, evaluation metrics, benchmarks). To address these gaps, we propose TaxoAdapt, a framework that dynamically adapts an LLM-generated taxonomy to a given corpus across multiple dimensions. TaxoAdapt performs iterative hierarchical classification, expanding both the taxonomy width and depth based on corpus' topical distribution. We demonstrate its state-of-the-art performance across a diverse set of computer science conferences over the years to showcase its ability to structure and capture the evolution of scientific fields. As a multidimensional method, TaxoAdapt generates taxonomies that are 26.51% more granularity-preserving and 50.41% more coherent than the most competitive baselines judged by LLMs.
Zero-Shot Open-Schema Entity Structure Discovery
Jun 04, 2025Entity structure extraction, which aims to extract entities and their associated attribute-value structures from text, is an essential task for text understanding and knowledge graph construction. Existing methods based on large language models (LLMs) typically rely heavily on predefined entity attribute schemas or annotated datasets, often leading to incomplete extraction results. To address these challenges, we introduce Zero-Shot Open-schema Entity Structure Discovery (ZOES), a novel approach to entity structure extraction that does not require any schema or annotated samples. ZOES operates via a principled mechanism of enrichment, refinement, and unification, based on the insight that an entity and its associated structure are mutually reinforcing. Experiments demonstrate that ZOES consistently enhances LLMs' ability to extract more complete entity structures across three different domains, showcasing both the effectiveness and generalizability of the method. These findings suggest that such an enrichment, refinement, and unification mechanism may serve as a principled approach to improving the quality of LLM-based entity structure discovery in various scenarios.
Scientific Paper Retrieval with LLM-Guided Semantic-Based Ranking
May 27, 2025Scientific paper retrieval is essential for supporting literature discovery and research. While dense retrieval methods demonstrate effectiveness in general-purpose tasks, they often fail to capture fine-grained scientific concepts that are essential for accurate understanding of scientific queries. Recent studies also use large language models (LLMs) for query understanding; however, these methods often lack grounding in corpus-specific knowledge and may generate unreliable or unfaithful content. To overcome these limitations, we propose SemRank, an effective and efficient paper retrieval framework that combines LLM-guided query understanding with a concept-based semantic index. Each paper is indexed using multi-granular scientific concepts, including general research topics and detailed key phrases. At query time, an LLM identifies core concepts derived from the corpus to explicitly capture the query's information need. These identified concepts enable precise semantic matching, significantly enhancing retrieval accuracy. Experiments show that SemRank consistently improves the performance of various base retrievers, surpasses strong existing LLM-based baselines, and remains highly efficient.
LogiCoL: Logically-Informed Contrastive Learning for Set-based Dense Retrieval
May 26, 2025While significant progress has been made with dual- and bi-encoder dense retrievers, they often struggle on queries with logical connectives, a use case that is often overlooked yet important in downstream applications. Current dense retrievers struggle with such queries, such that the retrieved results do not respect the logical constraints implied in the queries. To address this challenge, we introduce LogiCoL, a logically-informed contrastive learning objective for dense retrievers. LogiCoL builds upon in-batch supervised contrastive learning, and learns dense retrievers to respect the subset and mutually-exclusive set relation between query results via two sets of soft constraints expressed via t-norm in the learning objective. We evaluate the effectiveness of LogiCoL on the task of entity retrieval, where the model is expected to retrieve a set of entities in Wikipedia that satisfy the implicit logical constraints in the query. We show that models trained with LogiCoL yield improvement both in terms of retrieval performance and logical consistency in the results. We provide detailed analysis and insights to uncover why queries with logical connectives are challenging for dense retrievers and why LogiCoL is most effective.
Taxonomy-guided Semantic Indexing for Academic Paper Search
Oct 25, 2024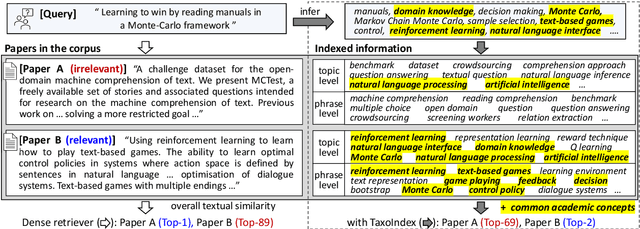
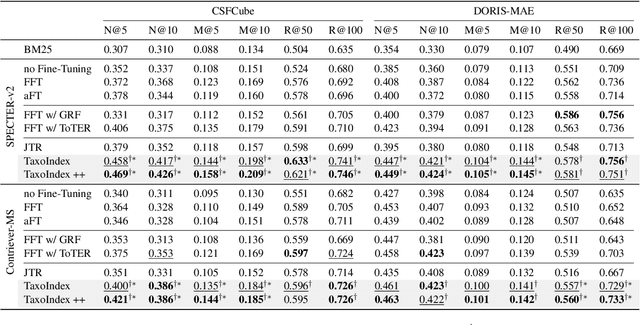
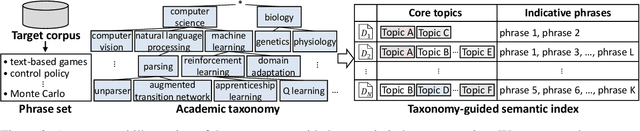
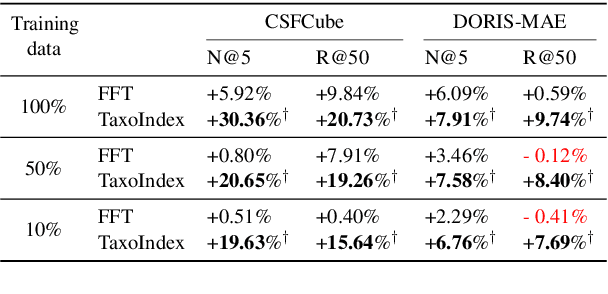
Academic paper search is an essential task for efficient literature discovery and scientific advancement. While dense retrieval has advanced various ad-hoc searches, it often struggles to match the underlying academic concepts between queries and documents, which is critical for paper search. To enable effective academic concept matching for paper search, we propose Taxonomy-guided Semantic Indexing (TaxoIndex) framework. TaxoIndex extracts key concepts from papers and organizes them as a semantic index guided by an academic taxonomy, and then leverages this index as foundational knowledge to identify academic concepts and link queries and documents. As a plug-and-play framework, TaxoIndex can be flexibly employed to enhance existing dense retrievers. Extensive experiments show that TaxoIndex brings significant improvements, even with highly limited training data, and greatly enhances interpretability.
ACER: Automatic Language Model Context Extension via Retrieval
Oct 11, 2024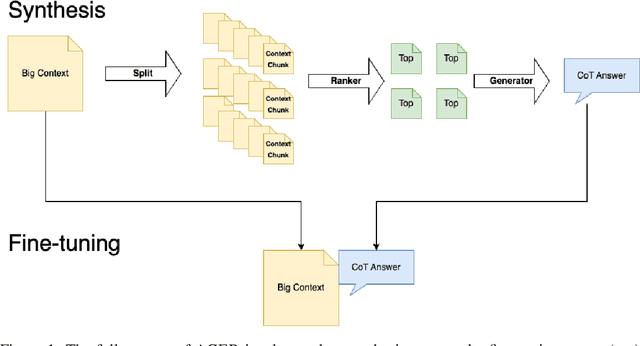
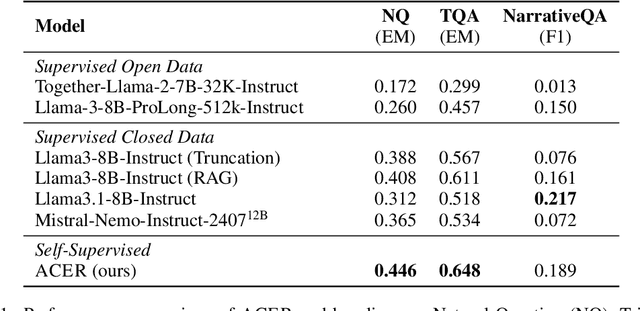

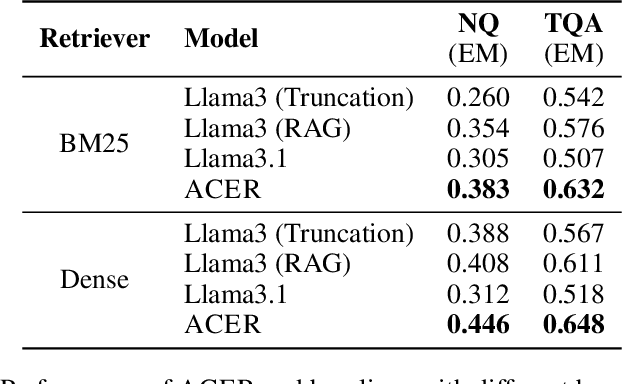
Long-context modeling is one of the critical capabilities of language AI for digesting and reasoning over complex information pieces. In practice, long-context capabilities are typically built into a pre-trained language model~(LM) through a carefully designed context extension stage, with the goal of producing generalist long-context capabilities. In our preliminary experiments, however, we discovered that the current open-weight generalist long-context models are still lacking in practical long-context processing tasks. While this means perfectly effective long-context modeling demands task-specific data, the cost can be prohibitive. In this paper, we draw inspiration from how humans process a large body of information: a lossy \textbf{retrieval} stage ranks a large set of documents while the reader ends up reading deeply only the top candidates. We build an \textbf{automatic} data synthesis pipeline that mimics this process using short-context LMs. The short-context LMs are further tuned using these self-generated data to obtain task-specific long-context capabilities. Similar to how pre-training learns from imperfect data, we hypothesize and further demonstrate that the short-context model can bootstrap over the synthetic data, outperforming not only long-context generalist models but also the retrieval and read pipeline used to synthesize the training data in real-world tasks such as long-context retrieval augmented generation.