 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Open-Schema Entity Structure Discovery
Jun 04, 2025Entity structure extraction, which aims to extract entities and their associated attribute-value structures from text, is an essential task for text understanding and knowledge graph construction. Existing methods based on large language models (LLMs) typically rely heavily on predefined entity attribute schemas or annotated datasets, often leading to incomplete extraction results. To address these challenges, we introduce Zero-Shot Open-schema Entity Structure Discovery (ZOES), a novel approach to entity structure extraction that does not require any schema or annotated samples. ZOES operates via a principled mechanism of enrichment, refinement, and unification, based on the insight that an entity and its associated structure are mutually reinforcing. Experiments demonstrate that ZOES consistently enhances LLMs' ability to extract more complete entity structures across three different domains, showcasing both the effectiveness and generalizability of the method. These findings suggest that such an enrichment, refinement, and unification mechanism may serve as a principled approach to improving the quality of LLM-based entity structure discovery in various scenarios.
s3: You Don't Need That Much Data to Train a Search Agent via RL
May 20, 2025Retrieval-augmented generation (RAG) systems empower large language models (LLMs) to access external knowledge during inference. Recent advances have enabled LLMs to act as search agents via reinforcement learning (RL), improving information acquisition through multi-turn interactions with retrieval engines. However, existing approaches either optimize retrieval using search-only metrics (e.g., NDCG) that ignore downstream utility or fine-tune the entire LLM to jointly reason and retrieve-entangling retrieval with generation and limiting the real search utility and compatibility with frozen or proprietary models. In this work, we propose s3, a lightweight, model-agnostic framework that decouples the searcher from the generator and trains the searcher using a Gain Beyond RAG reward: the improvement in generation accuracy over naive RAG. s3 requires only 2.4k training samples to outperform baselines trained on over 70x more data, consistently delivering stronger downstream performance across six general QA and five medical QA benchmarks.
Automated Construction of Theme-specific Knowledge Graphs
Apr 29, 2024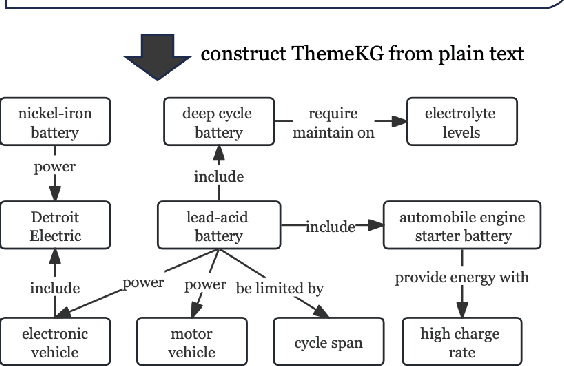
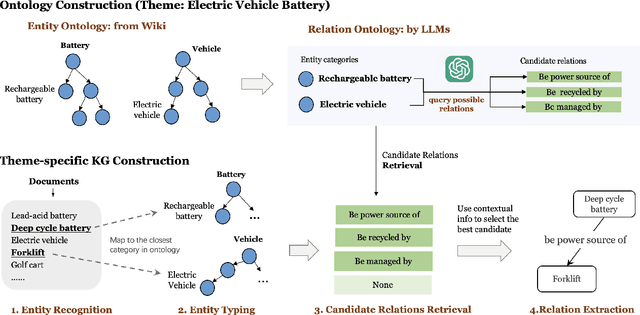
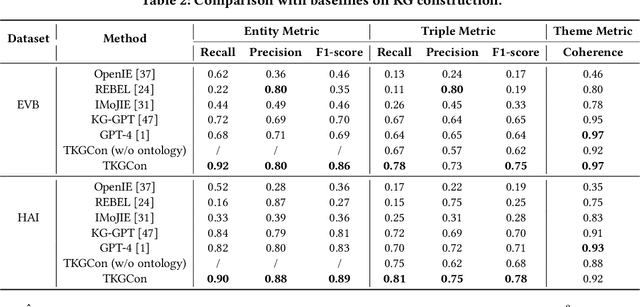
Despite widespread applications of knowledge graphs (KGs) in various tasks such as question answering and intelligent conversational systems, existing KGs face two major challenges: information granularity and deficiency in timeliness. These hinder considerably the retrieval and analysis of in-context, fine-grained, and up-to-date knowledge from KGs, particularly in highly specialized themes (e.g., specialized scientific research) and rapidly evolving contexts (e.g., breaking news or disaster tracking). To tackle such challenges, we propose a theme-specific knowledge graph (i.e., ThemeKG), a KG constructed from a theme-specific corpus, and design an unsupervised framework for ThemeKG construction (named TKGCon). The framework takes raw theme-specific corpus and generates a high-quality KG that includes salient entities and relations under the theme. Specifically, we start with an entity ontology of the theme from Wikipedia, based on which we then generate candidate relations by Large Language Models (LLMs) to construct a relation ontology. To parse the documents from the theme corpus, we first map the extracted entity pairs to the ontology and retrieve the candidate relations. Finally, we incorporate the context and ontology to consolidate the relations for entity pairs. We observe that directly prompting GPT-4 for theme-specific KG leads to inaccurate entities (such as "two main types" as one entity in the query result) and unclear (such as "is", "has") or wrong relations (such as "have due to", "to start"). In contrast, by constructing the theme-specific KG step by step, our model outperforms GPT-4 and could consistently identify accurate entities and relations. Experimental results also show that our framework excels in evaluations compared with various KG construction baselines.
TELEClass: Taxonomy Enrichment and LLM-Enhanced Hierarchical Text Classification with Minimal Supervision
Feb 29, 2024



Hierarchical text classification aims to categorize each document into a set of classes in a label taxonomy. Most earlier works focus on fully or semi-supervised methods that require a large amount of human annotated data which is costly and time-consuming to acquire. To alleviate human efforts, in this paper, we work on hierarchical text classification with the minimal amount of supervision: using the sole class name of each node as the only supervision. Recently, large language models (LLM) show competitive performance on various tasks through zero-shot prompting, but this method performs poorly in the hierarchical setting, because it is ineffective to include the large and structured label space in a prompt. On the other hand, previous weakly-supervised hierarchical text classification methods only utilize the raw taxonomy skeleton and ignore the rich information hidden in the text corpus that can serve as additional class-indicative features. To tackle the above challenges, we propose TELEClass, Taxonomy Enrichment and LLM-Enhanced weakly-supervised hierarchical text classification, which (1) automatically enriches the label taxonomy with class-indicative topical terms mined from the corpus to facilitate classifier training and (2) utilizes LLMs for both data annotation and creation tailored for the hierarchical label space. Experiments show that TELEClass can outperform previous weakly-supervised hierarchical text classification methods and LLM-based zero-shot prompting methods on two public datasets.
Knowledge-Rich Self-Supervised Entity Linking
Dec 15, 2021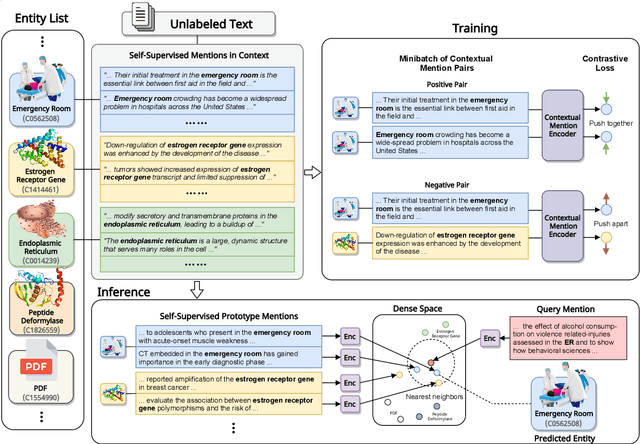
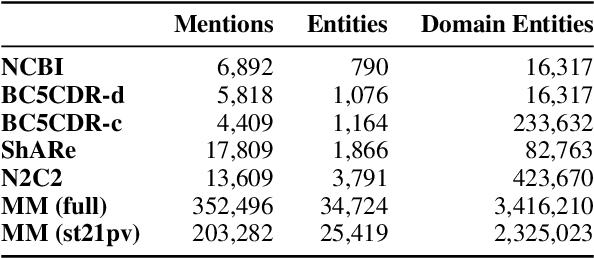
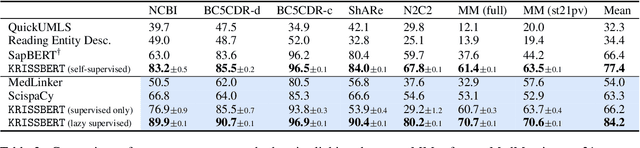
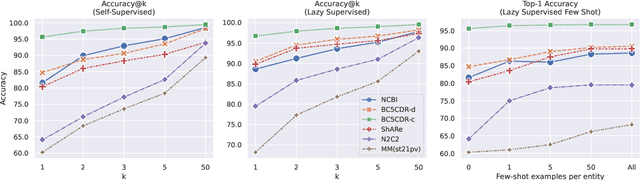
Entity linking faces significant challenges, such as prolific variations and prevalent ambiguities, especially in high-value domains with myriad entities. Standard classification approaches suffer from the annotation bottleneck and cannot effectively handle unseen entities. Zero-shot entity linking has emerged as a promising direction for generalizing to new entities, but it still requires example gold entity mentions during training and canonical descriptions for all entities, both of which are rarely available outside of Wikipedia. In this paper, we explore Knowledge-RIch Self-Supervision ($\tt KRISS$) for entity linking, by leveraging readily available domain knowledge. In training, it generates self-supervised mention examples on unlabeled text using a domain ontology and trains a contextual encoder using contrastive learning. For inference, it samples self-supervised mentions as prototypes for each entity and conducts linking by mapping the test mention to the most similar prototype. Our approach subsumes zero-shot and few-shot methods, and can easily incorporate entity descriptions and gold mention labels if available. Using biomedicine as a case study, we conducted extensive experiments on seven standard datasets spanning biomedical literature and clinical notes. Without using any labeled information, our method produces $\tt KRISSBERT$, a universal entity linker for four million UMLS entities, which attains new state of the art, outperforming prior self-supervised methods by as much as over 20 absolute points in accuracy.
Fine-Grained Chemical Entity Typing with Multimodal Knowledge Representation
Aug 29, 2021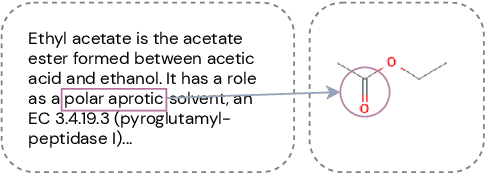
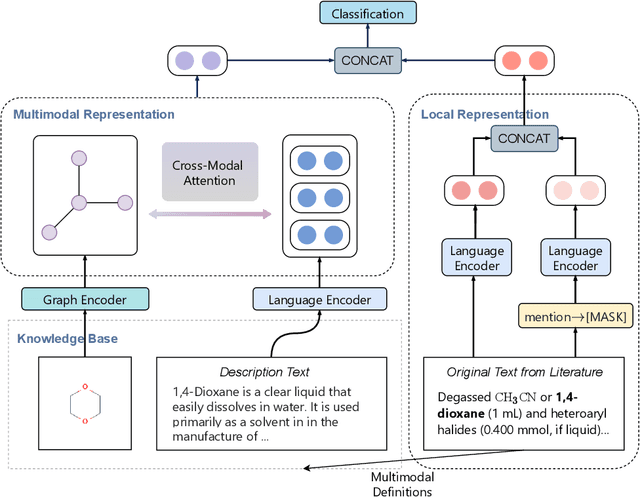
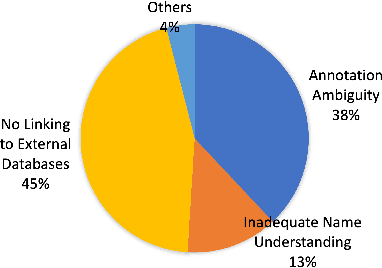
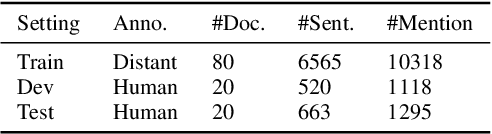
Automated knowledge discovery from trending chemical literature is essential for more efficient biomedical research. How to extract detailed knowledge about chemical reactions from the core chemistry literature is a new emerging challenge that has not been well studied. In this paper, we study the new problem of fine-grained chemical entity typing, which poses interesting new challenges especially because of the complex name mentions frequently occurring in chemistry literature and graphic representation of entities. We introduce a new benchmark data set (CHEMET) to facilitate the study of the new task and propose a novel multi-modal representation learning framework to solve the problem of fine-grained chemical entity typing by leveraging external resources with chemical structures and using cross-modal attention to learn effective representation of text in the chemistry domain. Experiment results show that the proposed framework outperforms multiple state-of-the-art methods.
Open-Domain Question Answering with Pre-Constructed Question Spaces
Jun 02, 2020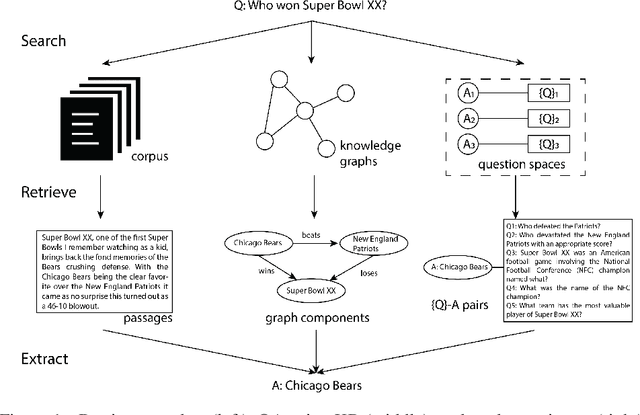

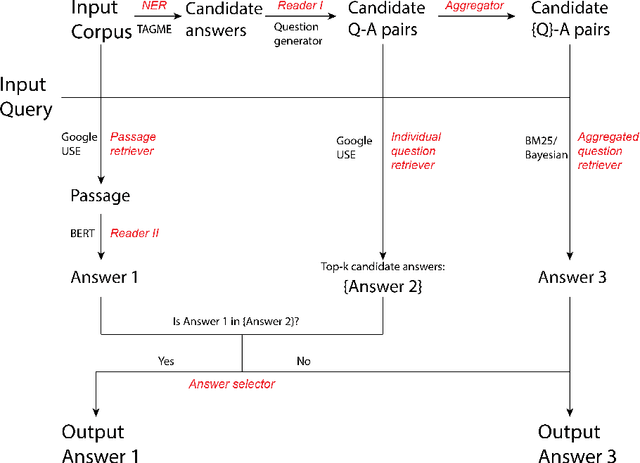
Open-domain question answering aims at solving the task of locating the answers to user-generated questions in large collections of documents. There are two families of solutions to this challenge. One family of algorithms, namely retriever-readers, first retrieves some pieces of text that are probably relevant to the question, and then feeds the retrieved text to a neural network to get the answer. Another line of work first constructs some knowledge graphs from the corpus, and queries the graph for the answer. We propose a novel algorithm with a reader-retriever structure that differs from both families. Our algorithm first reads off-line the corpus to generate collections of all answerable questions associated with their answers, and then queries the pre-constructed question spaces online to find answers that are most likely to be asked in the given way. The final answer returned to the user is decided with an accept-or-reject mechanism that combines multiple candidate answers by comparing the level of agreement between the retriever-reader and reader-retriever results. We claim that our algorithm solves some bottlenecks in existing work, and demonstrate that it achieves superior accuracy on a public dataset.
Query-Specific Knowledge Summarization with Entity Evolutionary Networks
Sep 29, 2019
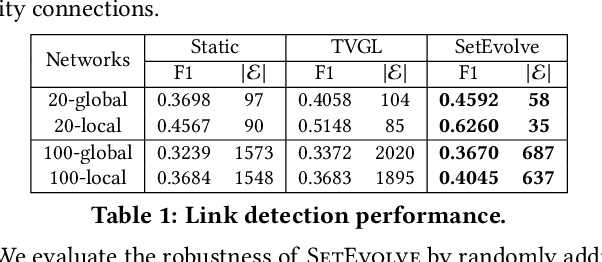
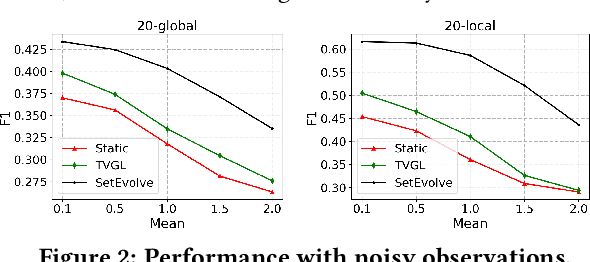
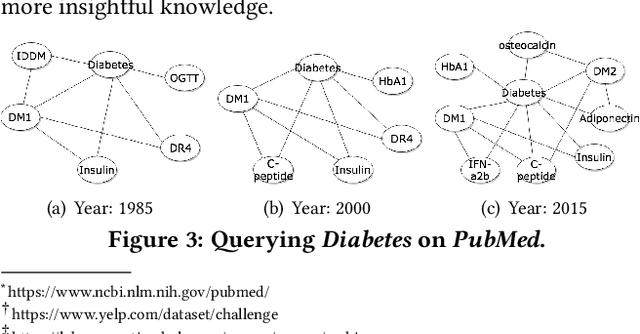
Given a query, unlike traditional IR that finds relevant documents or entities, in this work, we focus on retrieving both entities and their connections for insightful knowledge summarization. For example, given a query "computer vision" on a CS literature corpus, rather than returning a list of relevant entities like "cnn", "imagenet" and "svm", we are interested in the connections among them, and furthermore, the evolution patterns of such connections along particular ordinal dimensions such as time. Particularly, we hope to provide structural knowledge relevant to the query, such as "svm" is related to "imagenet" but not "cnn". Moreover, we aim to model the changing trends of the connections, such as "cnn" becomes highly related to "imagenet" after 2010, which enables the tracking of knowledge evolutions. In this work, to facilitate such a novel insightful search system, we propose \textsc{SetEvolve}, which is a unified framework based on nonparanomal graphical models for evolutionary network construction from large text corpora. Systematic experiments on synthetic data and insightful case studies on real-world corpora demonstrate the utility of \textsc{SetEvolve}.
DPPred: An Effective Prediction Framework with Concise Discriminative Patterns
Oct 31, 2016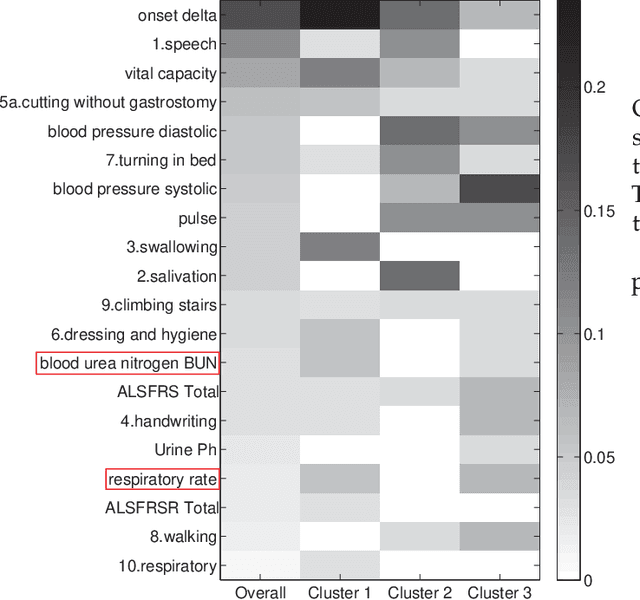
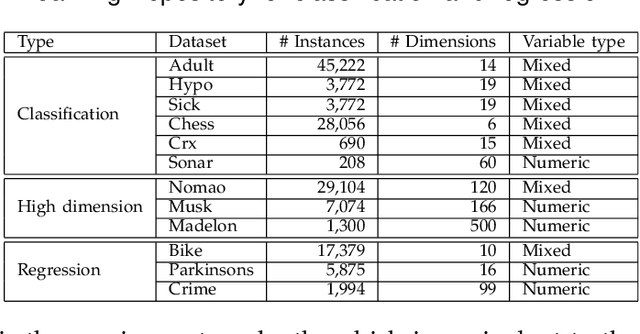
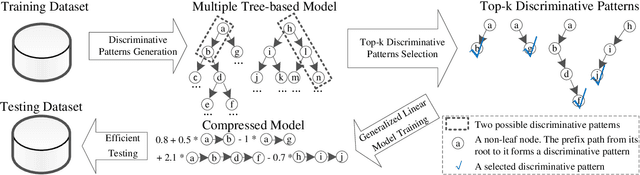

In the literature, two series of models have been proposed to address prediction problems including classification and regression. Simple models, such as generalized linear models, have ordinary performance but strong interpretability on a set of simple features. The other series, including tree-based models, organize numerical, categorical and high dimensional features into a comprehensive structure with rich interpretable information in the data. In this paper, we propose a novel Discriminative Pattern-based Prediction framework (DPPred) to accomplish the prediction tasks by taking their advantages of both effectiveness and interpretability. Specifically, DPPred adopts the concise discriminative patterns that are on the prefix paths from the root to leaf nodes in the tree-based models. DPPred selects a limited number of the useful discriminative patterns by searching for the most effective pattern combination to fit generalized linear models. Extensive experiments show that in many scenarios, DPPred provides competitive accuracy with the state-of-the-art as well as the valuable interpretability for developers and experts. In particular, taking a clinical application dataset as a case study, our DPPred outperforms the baselines by using only 40 concise discriminative patterns out of a potentially exponentially large set of patterns.