 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAB: Speech Tokenizer Assessment Benchmark
Sep 04, 2024
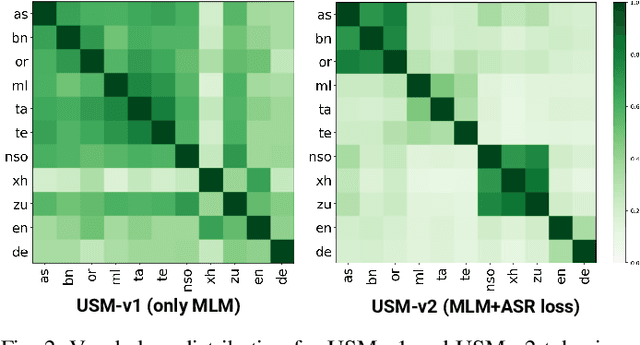
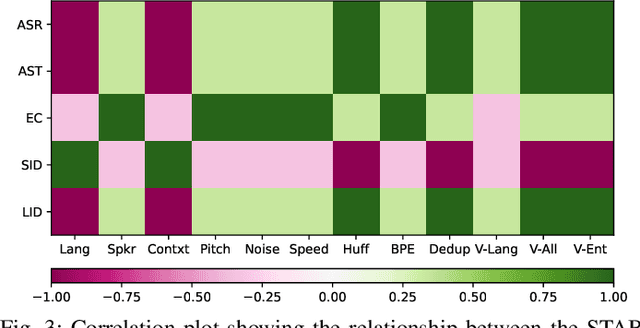
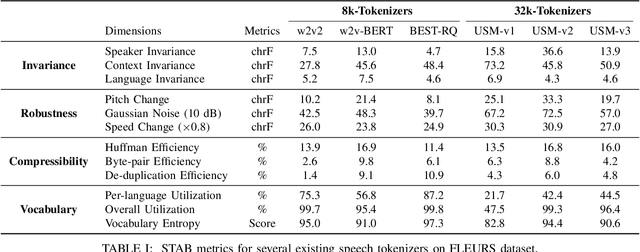
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
A Morphology-Based Investigation of Positional Encodings
Apr 06, 2024



How does the importance of positional encoding in pre-trained language models (PLMs) vary across languages with different morphological complexity? In this paper, we offer the first study addressing this question, encompassing 23 morphologically diverse languages and 5 different downstream tasks. We choose two categories of tasks: syntactic tasks (part-of-speech tagging, named entity recognition, dependency parsing) and semantic tasks (natural language inference, paraphrasing). We consider language-specific BERT models trained on monolingual corpus for our investigation. The main experiment consists of nullifying the effect of positional encoding during fine-tuning and investigating its impact across various tasks and languages. Our findings demonstrate that the significance of positional encoding diminishes as the morphological complexity of a language increases. Across all experiments, we observe clustering of languages according to their morphological typology - with analytic languages at one end and synthetic languages at the opposite end.
LLM Augmented LLMs: Expanding Capabilities through Composition
Jan 04, 2024



Foundational models with billions of parameters which have been trained on large corpora of data have demonstrated non-trivial skills in a variety of domains. However, due to their monolithic structure, it is challenging and expensive to augment them or impart new skills. On the other hand, due to their adaptation abilities, several new instances of these models are being trained towards new domains and tasks. In this work, we study the problem of efficient and practical composition of existing foundation models with more specific models to enable newer capabilities. To this end, we propose CALM -- Composition to Augment Language Models -- which introduces cross-attention between models to compose their representations and enable new capabilities. Salient features of CALM are: (i) Scales up LLMs on new tasks by 're-using' existing LLMs along with a few additional parameters and data, (ii) Existing model weights are kept intact, and hence preserves existing capabilities, and (iii) Applies to diverse domains and settings. We illustrate that augmenting PaLM2-S with a smaller model trained on low-resource languages results in an absolute improvement of up to 13\% on tasks like translation into English and arithmetic reasoning for low-resource languages. Similarly, when PaLM2-S is augmented with a code-specific model, we see a relative improvement of 40\% over the base model for code generation and explanation tasks -- on-par with fully fine-tuned counterparts.
Self-Influence Guided Data Reweighting for Language Model Pre-training
Nov 02, 2023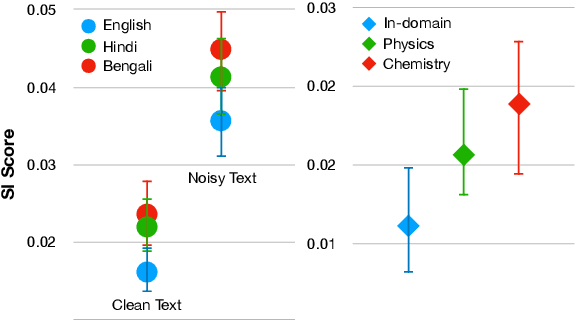
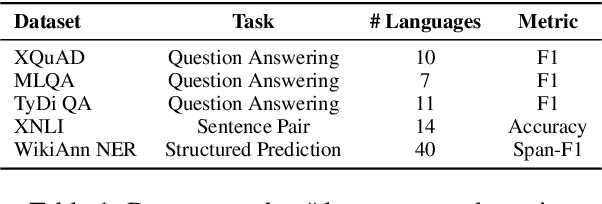
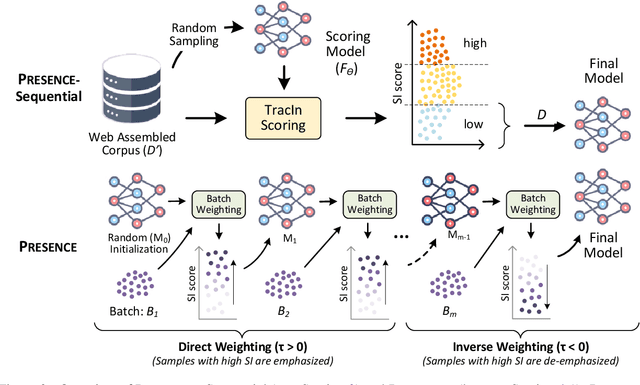
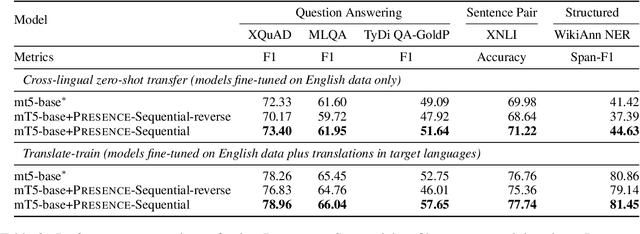
Language Models (LMs) pre-trained with self-supervision on large text corpora have become the default starting point for developing models for various NLP tasks. Once the pre-training corpus has been assembled, all data samples in the corpus are treated with equal importance during LM pre-training. However, due to varying levels of relevance and quality of data, equal importance to all the data samples may not be the optimal choice. While data reweighting has been explored in the context of task-specific supervised learning and LM fine-tuning, model-driven reweighting for pre-training data has not been explored. We fill this important gap and propose PRESENCE, a method for jointly reweighting samples by leveraging self-influence (SI) scores as an indicator of sample importance and pre-training. PRESENCE promotes novelty and stability for model pre-training. Through extensive analysis spanning multiple model sizes, datasets, and tasks, we present PRESENCE as an important first step in the research direction of sample reweighting for pre-training language models.
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023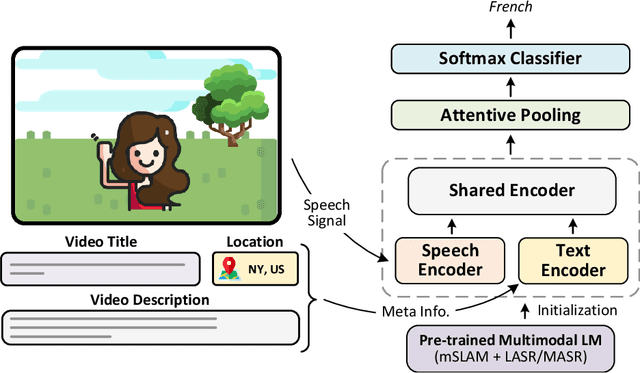
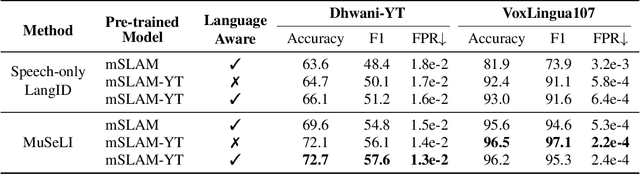
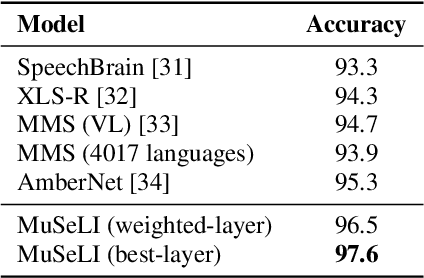
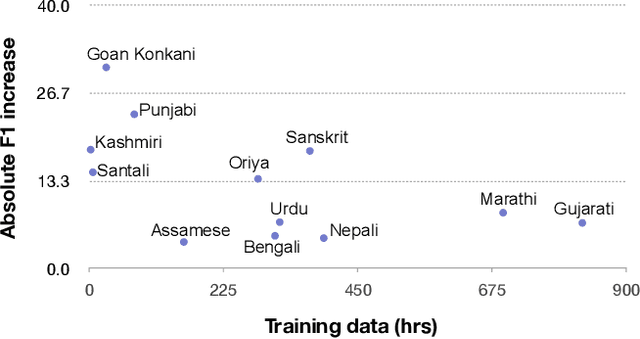
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
MASR: Metadata Aware Speech Representation
Jul 20, 2023In the recent years, speech representation learning is constructed primarily as a self-supervised learning (SSL) task, using the raw audio signal alone, while ignoring the side-information that is often available for a given speech recording. In this paper, we propose MASR, a Metadata Aware Speech Representation learning framework, which addresses the aforementioned limitations. MASR enables the inclusion of multiple external knowledge sources to enhance the utilization of meta-data information. The external knowledge sources are incorporated in the form of sample-level pair-wise similarity matrices that are useful in a hard-mining loss. A key advantage of the MASR framework is that it can be combined with any choice of SSL method. Using MASR representations, we perform evaluations on several downstream tasks such as language identification, speech recognition and other non-semantic tasks such as speaker and emotion recognition. In these experiments, we illustrate significant performance improvements for the MASR over other established benchmarks. We perform a detailed analysis on the language identification task to provide insights on how the proposed loss function enables the representations to separate closely related languages.
Label Aware Speech Representation Learning For Language Identification
Jun 07, 2023

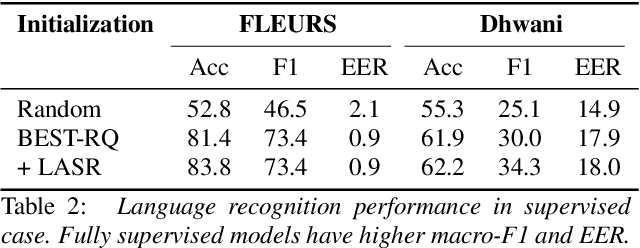

Speech representation learning approaches for non-semantic tasks such as language recognition have either explored supervised embedding extraction methods using a classifier model or self-supervised representation learning approaches using raw data. In this paper, we propose a novel framework of combining self-supervised representation learning with the language label information for the pre-training task. This framework, termed as Label Aware Speech Representation (LASR) learning, uses a triplet based objective function to incorporate language labels along with the self-supervised loss function. The speech representations are further fine-tuned for the downstream task. The language recognition experiments are performed on two public datasets - FLEURS and Dhwani. In these experiments, we illustrate that the proposed LASR framework improves over the state-of-the-art systems on language identification. We also report an analysis of the robustness of LASR approach to noisy/missing labels as well as its application to multi-lingual speech recognition tasks.
Knowledge-Rich Self-Supervised Entity Linking
Dec 15, 2021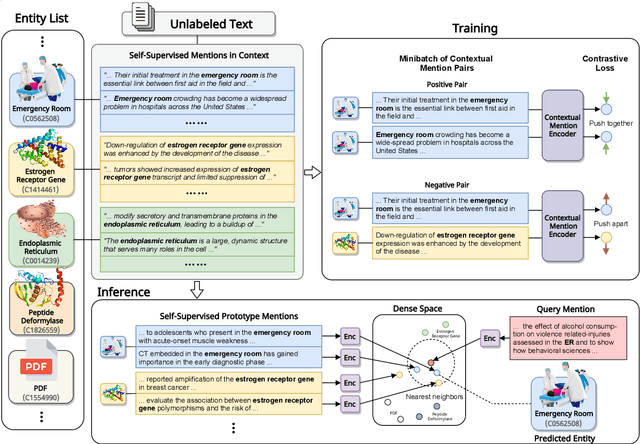
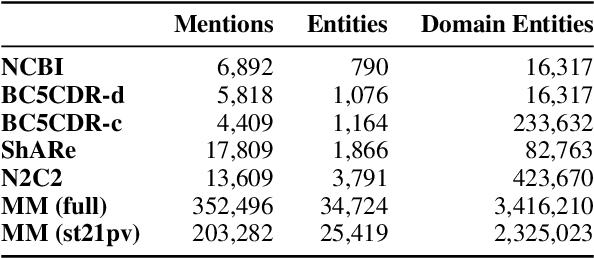
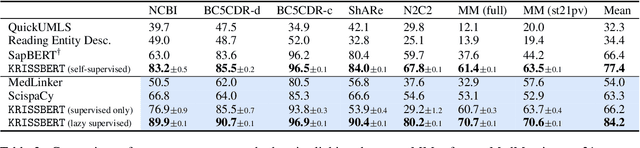
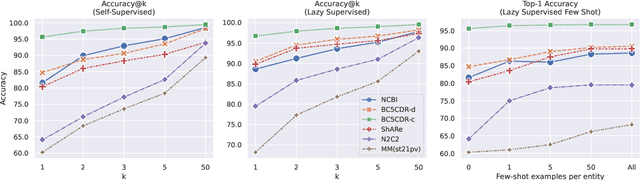
Entity linking faces significant challenges, such as prolific variations and prevalent ambiguities, especially in high-value domains with myriad entities. Standard classification approaches suffer from the annotation bottleneck and cannot effectively handle unseen entities. Zero-shot entity linking has emerged as a promising direction for generalizing to new entities, but it still requires example gold entity mentions during training and canonical descriptions for all entities, both of which are rarely available outside of Wikipedia. In this paper, we explore Knowledge-RIch Self-Supervision ($\tt KRISS$) for entity linking, by leveraging readily available domain knowledge. In training, it generates self-supervised mention examples on unlabeled text using a domain ontology and trains a contextual encoder using contrastive learning. For inference, it samples self-supervised mentions as prototypes for each entity and conducts linking by mapping the test mention to the most similar prototype. Our approach subsumes zero-shot and few-shot methods, and can easily incorporate entity descriptions and gold mention labels if available. Using biomedicine as a case study, we conducted extensive experiments on seven standard datasets spanning biomedical literature and clinical notes. Without using any labeled information, our method produces $\tt KRISSBERT$, a universal entity linker for four million UMLS entities, which attains new state of the art, outperforming prior self-supervised methods by as much as over 20 absolute points in accuracy.
Robust Knowledge Graph Completion with Stacked Convolutions and a Student Re-Ranking Network
Jun 11, 2021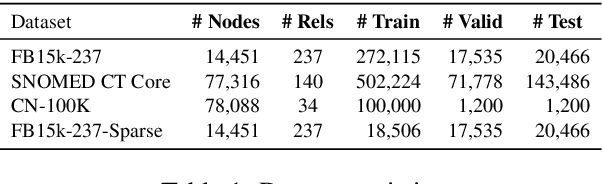
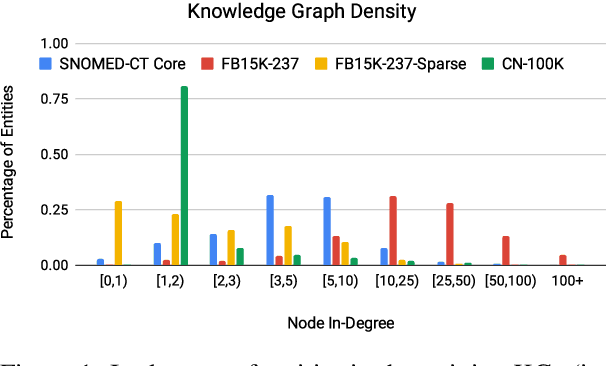
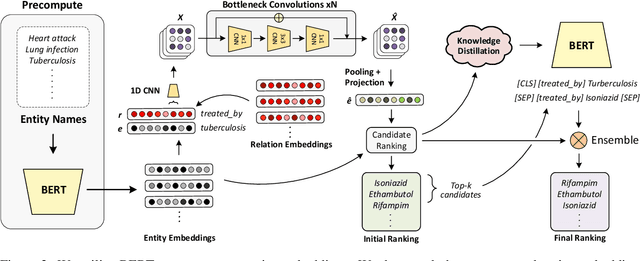

Knowledge Graph (KG) completion research usually focuses on densely connected benchmark datasets that are not representative of real KGs. We curate two KG datasets that include biomedical and encyclopedic knowledge and use an existing commonsense KG dataset to explore KG completion in the more realistic setting where dense connectivity is not guaranteed. We develop a deep convolutional network that utilizes textual entity representations and demonstrate that our model outperforms recent KG completion methods in this challenging setting. We find that our model's performance improvements stem primarily from its robustness to sparsity. We then distill the knowledge from the convolutional network into a student network that re-ranks promising candidate entities. This re-ranking stage leads to further improvements in performance and demonstrates the effectiveness of entity re-ranking for KG completion.
DialoGraph: Incorporating Interpretable Strategy-Graph Networks into Negotiation Dialogues
Jun 02, 2021


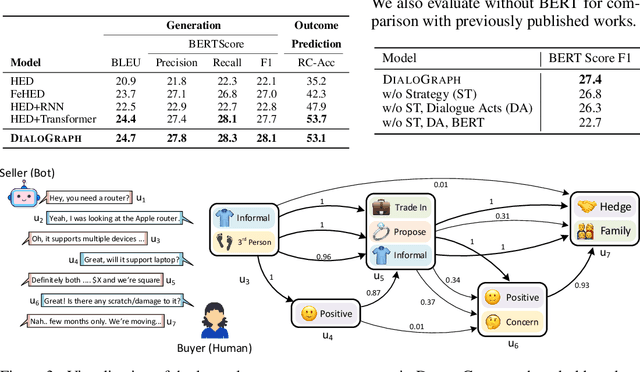
To successfully negotiate a deal, it is not enough to communicate fluently: pragmatic planning of persuasive negotiation strategies is essential. While modern dialogue agents excel at generating fluent sentences, they still lack pragmatic grounding and cannot reason strategically. We present DialoGraph, a negotiation system that incorporates pragmatic strategies in a negotiation dialogue using graph neural networks. DialoGraph explicitly incorporates dependencies between sequences of strategies to enable improved and interpretable prediction of next optimal strategies, given the dialogue context. Our graph-based method outperforms prior state-of-the-art negotiation models both in the accuracy of strategy/dialogue act prediction and in the quality of downstream dialogue response generation. We qualitatively show further benefits of learned strategy-graphs in providing explicit associations between effective negotiation strategies over the course of the dialogue, leading to interpretable and strategic dialogues.