 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Visual Representations via Spatial-Semantic Factorization
Feb 02, 2026Self-supervised learning (SSL) faces a fundamental conflict between semantic understanding and image reconstruction. High-level semantic SSL (e.g., DINO) relies on global tokens that are forced to be location-invariant for augmentation alignment, a process that inherently discards the spatial coordinates required for reconstruction. Conversely, generative SSL (e.g., MAE) preserves dense feature grids for reconstruction but fails to produce high-level abstractions. We introduce STELLAR, a framework that resolves this tension by factorizing visual features into a low-rank product of semantic concepts and their spatial distributions. This disentanglement allows us to perform DINO-style augmentation alignment on the semantic tokens while maintaining the precise spatial mapping in the localization matrix necessary for pixel-level reconstruction. We demonstrate that as few as 16 sparse tokens under this factorized form are sufficient to simultaneously support high-quality reconstruction (2.60 FID) and match the semantic performance of dense backbones (79.10% ImageNet accuracy). Our results highlight STELLAR as a versatile sparse representation that bridges the gap between discriminative and generative vision by strategically separating semantic identity from spatial geometry. Code available at https://aka.ms/stellar.
Scaling medical imaging report generation with multimodal reinforcement learning
Jan 23, 2026Frontier models have demonstrated remarkable capabilities in understanding and reasoning with natural-language text, but they still exhibit major competency gaps in multimodal understanding and reasoning especially in high-value verticals such as biomedicine. Medical imaging report generation is a prominent example. Supervised fine-tuning can substantially improve performance, but they are prone to overfitting to superficial boilerplate patterns. In this paper, we introduce Universal Report Generation (UniRG) as a general framework for medical imaging report generation. By leveraging reinforcement learning as a unifying mechanism to directly optimize for evaluation metrics designed for end applications, UniRG can significantly improve upon supervised fine-tuning and attain durable generalization across diverse institutions and clinical practices. We trained UniRG-CXR on publicly available chest X-ray (CXR) data and conducted a thorough evaluation in CXR report generation with rigorous evaluation scenarios. On the authoritative ReXrank benchmark, UniRG-CXR sets new overall SOTA, outperforming prior state of the art by a wide margin.
BioClinical ModernBERT: A State-of-the-Art Long-Context Encoder for Biomedical and Clinical NLP
Jun 12, 2025Encoder-based transformer models are central to biomedical and clinical Natural Language Processing (NLP), as their bidirectional self-attention makes them well-suited for efficiently extracting structured information from unstructured text through discriminative tasks. However, encoders have seen slower development compared to decoder models, leading to limited domain adaptation in biomedical and clinical settings. We introduce BioClinical ModernBERT, a domain-adapted encoder that builds on the recent ModernBERT release, incorporating long-context processing and substantial improvements in speed and performance for biomedical and clinical NLP. BioClinical ModernBERT is developed through continued pretraining on the largest biomedical and clinical corpus to date, with over 53.5 billion tokens, and addresses a key limitation of prior clinical encoders by leveraging 20 datasets from diverse institutions, domains, and geographic regions, rather than relying on data from a single source. It outperforms existing biomedical and clinical encoders on four downstream tasks spanning a broad range of use cases. We release both base (150M parameters) and large (396M parameters) versions of BioClinical ModernBERT, along with training checkpoints to support further research.
Exploring Scaling Laws for EHR Foundation Models
May 29, 2025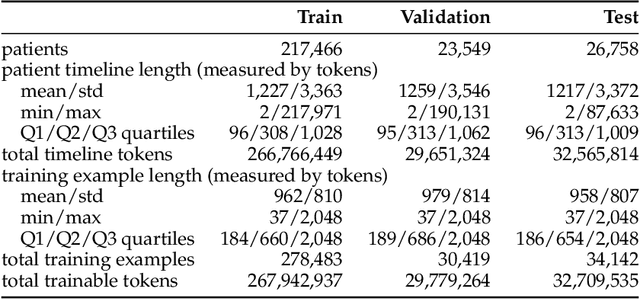
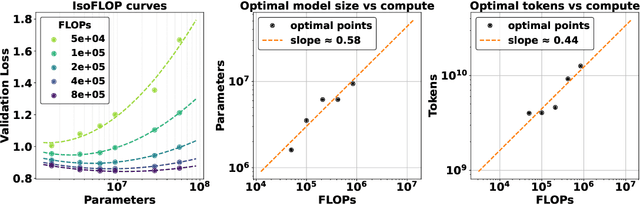
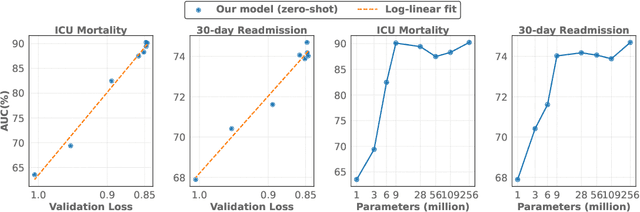
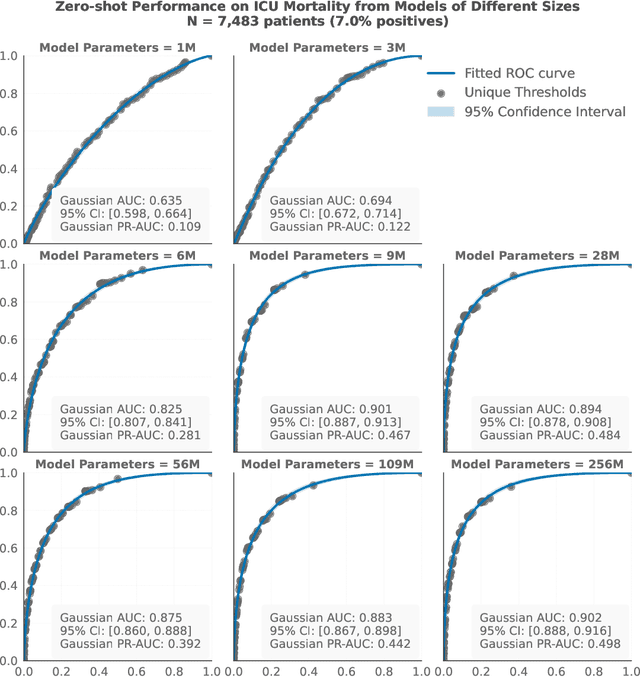
The emergence of scaling laws has profoundly shaped the development of large language models (LLMs), enabling predictable performance gains through systematic increases in model size, dataset volume, and compute. Yet, these principles remain largely unexplored in the context of electronic health records (EHRs) -- a rich, sequential, and globally abundant data source that differs structurally from natural language. In this work, we present the first empirical investigation of scaling laws for EHR foundation models. By training transformer architectures on patient timeline data from the MIMIC-IV database across varying model sizes and compute budgets, we identify consistent scaling patterns, including parabolic IsoFLOPs curves and power-law relationships between compute, model parameters, data size, and clinical utility. These findings demonstrate that EHR models exhibit scaling behavior analogous to LLMs, offering predictive insights into resource-efficient training strategies. Our results lay the groundwork for developing powerful EHR foundation models capable of transforming clinical prediction tasks and advancing personalized healthcare.
X-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains
May 06, 2025Recent proprietary models (e.g., o3) have begun to demonstrate strong multimodal reasoning capabilities. Yet, most existing open-source research concentrates on training text-only reasoning models, with evaluations limited to mainly mathematical and general-domain tasks. Therefore, it remains unclear how to effectively extend reasoning capabilities beyond text input and general domains. This paper explores a fundamental research question: Is reasoning generalizable across modalities and domains? Our findings support an affirmative answer: General-domain text-based post-training can enable such strong generalizable reasoning. Leveraging this finding, we introduce X-Reasoner, a vision-language model post-trained solely on general-domain text for generalizable reasoning, using a two-stage approach: an initial supervised fine-tuning phase with distilled long chain-of-thoughts, followed by reinforcement learning with verifiable rewards. Experiments show that X-Reasoner successfully transfers reasoning capabilities to both multimodal and out-of-domain settings, outperforming existing state-of-the-art models trained with in-domain and multimodal data across various general and medical benchmarks (Figure 1). Additionally, we find that X-Reasoner's performance in specialized domains can be further enhanced through continued training on domain-specific text-only data. Building upon this, we introduce X-Reasoner-Med, a medical-specialized variant that achieves new state of the art on numerous text-only and multimodal medical benchmarks.
Med-RLVR: Emerging Medical Reasoning from a 3B base model via reinforcement Learning
Feb 27, 2025



Reinforcement learning from verifiable rewards (RLVR) has recently gained attention for its ability to elicit self-evolved reasoning capabilitie from base language models without explicit reasoning supervisions, as demonstrated by DeepSeek-R1. While prior work on RLVR has primarily focused on mathematical and coding domains, its applicability to other tasks and domains remains unexplored. In this work, we investigate whether medical reasoning can emerge from RLVR. We introduce Med-RLVR as an initial study of RLVR in the medical domain leveraging medical multiple-choice question answering (MCQA) data as verifiable labels. Our results demonstrate that RLVR is not only effective for math and coding but also extends successfully to medical question answering. Notably, Med-RLVR achieves performance comparable to traditional supervised fine-tuning (SFT) on in-distribution tasks while significantly improving out-of-distribution generalization, with an 8-point accuracy gain. Further analysis of training dynamics reveals that, with no explicit reasoning supervision, reasoning emerges from the 3B-parameter base model. These findings underscore the potential of RLVR in domains beyond math and coding, opening new avenues for its application in knowledge-intensive fields such as medicine.
Universal Abstraction: Harnessing Frontier Models to Structure Real-World Data at Scale
Feb 02, 2025



The vast majority of real-world patient information resides in unstructured clinical text, and the process of medical abstraction seeks to extract and normalize structured information from this unstructured input. However, traditional medical abstraction methods can require significant manual efforts that can include crafting rules or annotating training labels, limiting scalability. In this paper, we propose UniMedAbstractor (UMA), a zero-shot medical abstraction framework leveraging Large Language Models (LLMs) through a modular and customizable prompt template. We refer to our approach as universal abstraction as it can quickly scale to new attributes through its universal prompt template without curating attribute-specific training labels or rules. We evaluate UMA for oncology applications, focusing on fifteen key attributes representing the cancer patient journey, from short-context attributes (e.g., performance status, treatment) to complex long-context attributes requiring longitudinal reasoning (e.g., tumor site, histology, TNM staging). Experiments on real-world data show UMA's strong performance and generalizability. Compared to supervised and heuristic baselines, UMA with GPT-4o achieves on average an absolute 2-point F1/accuracy improvement for both short-context and long-context attribute abstraction. For pathologic T staging, UMA even outperforms the supervised model by 20 points in accuracy.
BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once
May 21, 2024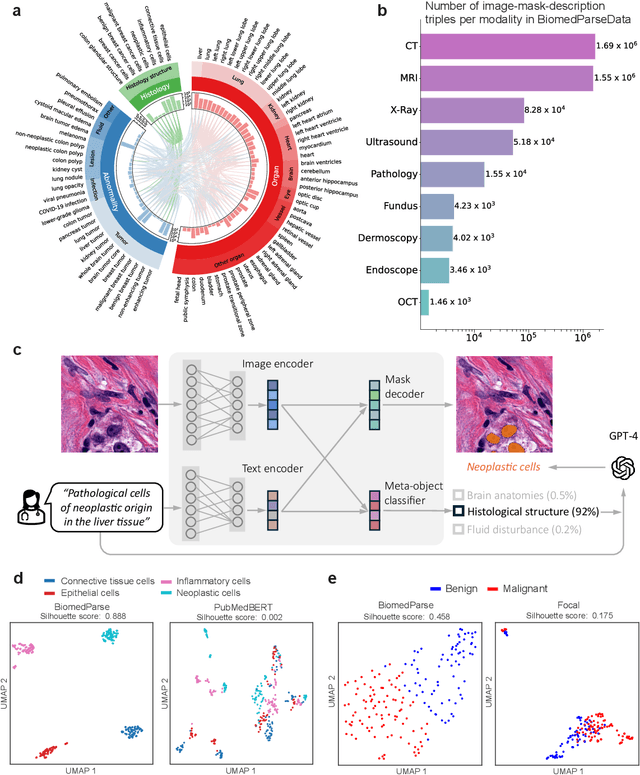
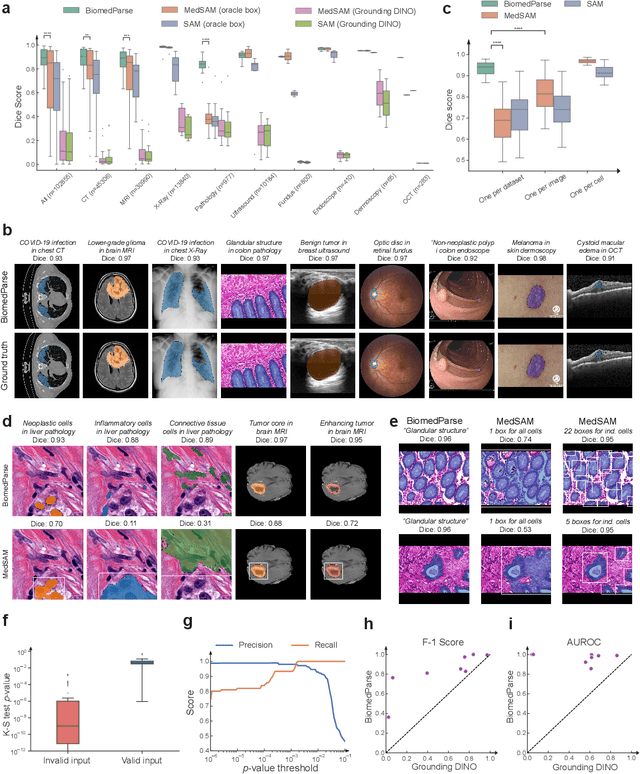
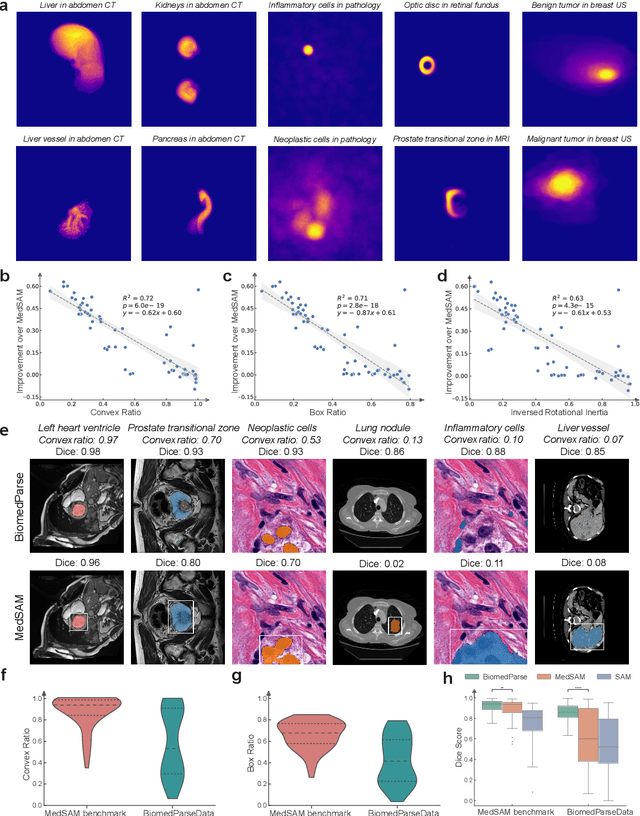
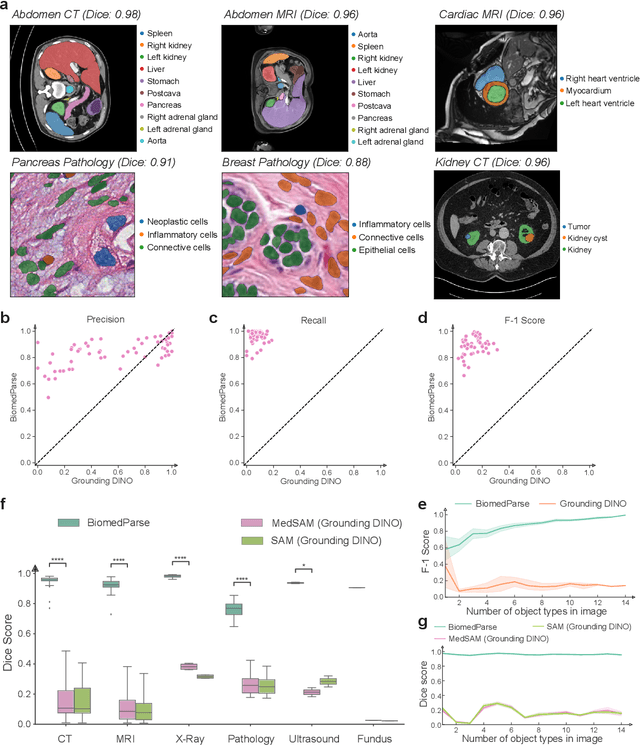
Biomedical image analysis is fundamental for biomedical discovery in cell biology, pathology, radiology, and many other biomedical domains. Holistic image analysis comprises interdependent subtasks such as segmentation, detection, and recognition of relevant objects. Here, we propose BiomedParse, a biomedical foundation model for imaging parsing that can jointly conduct segmentation, detection, and recognition for 82 object types across 9 imaging modalities. Through joint learning, we can improve accuracy for individual tasks and enable novel applications such as segmenting all relevant objects in an image through a text prompt, rather than requiring users to laboriously specify the bounding box for each object. We leveraged readily available natural-language labels or descriptions accompanying those datasets and use GPT-4 to harmonize the noisy, unstructured text information with established biomedical object ontologies. We created a large dataset comprising over six million triples of image, segmentation mask, and textual description. On image segmentation, we showed that BiomedParse is broadly applicable, outperforming state-of-the-art methods on 102,855 test image-mask-label triples across 9 imaging modalities (everything). On object detection, which aims to locate a specific object of interest, BiomedParse again attained state-of-the-art performance, especially on objects with irregular shapes (everywhere). On object recognition, which aims to identify all objects in a given image along with their semantic types, we showed that BiomedParse can simultaneously segment and label all biomedical objects in an image (all at once). In summary, BiomedParse is an all-in-one tool for biomedical image analysis by jointly solving segmentation, detection, and recognition for all major biomedical image modalities, paving the path for efficient and accurate image-based biomedical discovery.
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024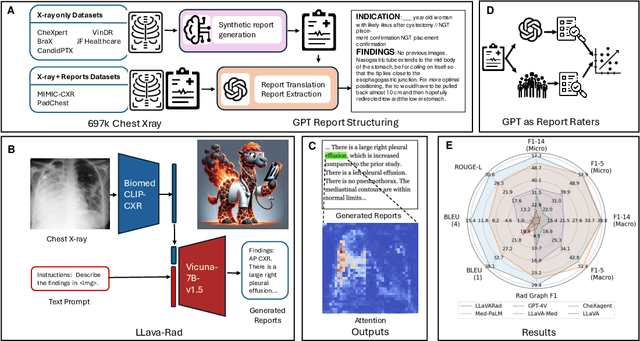
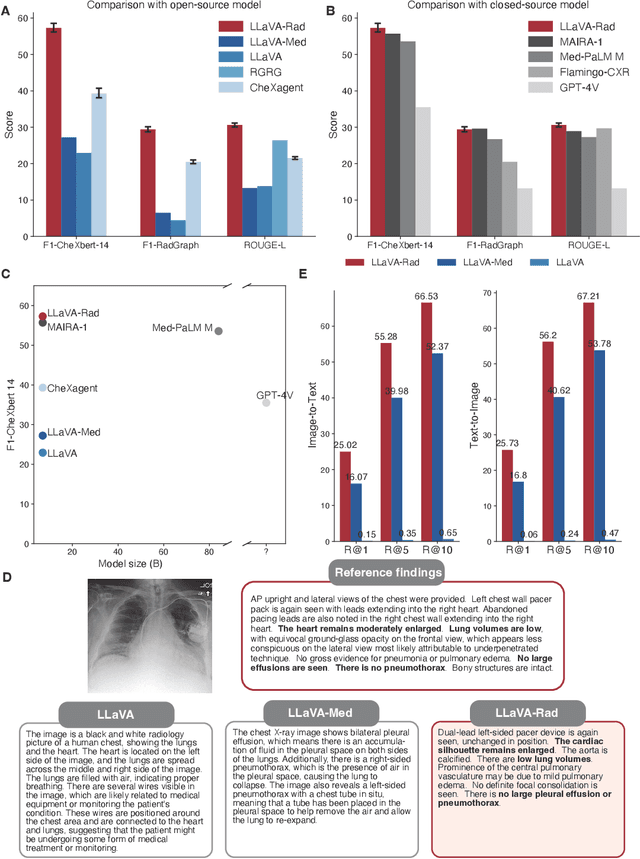
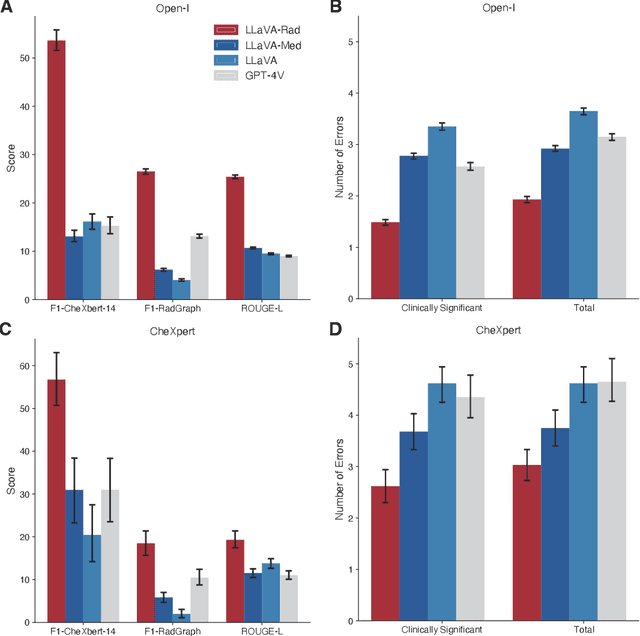
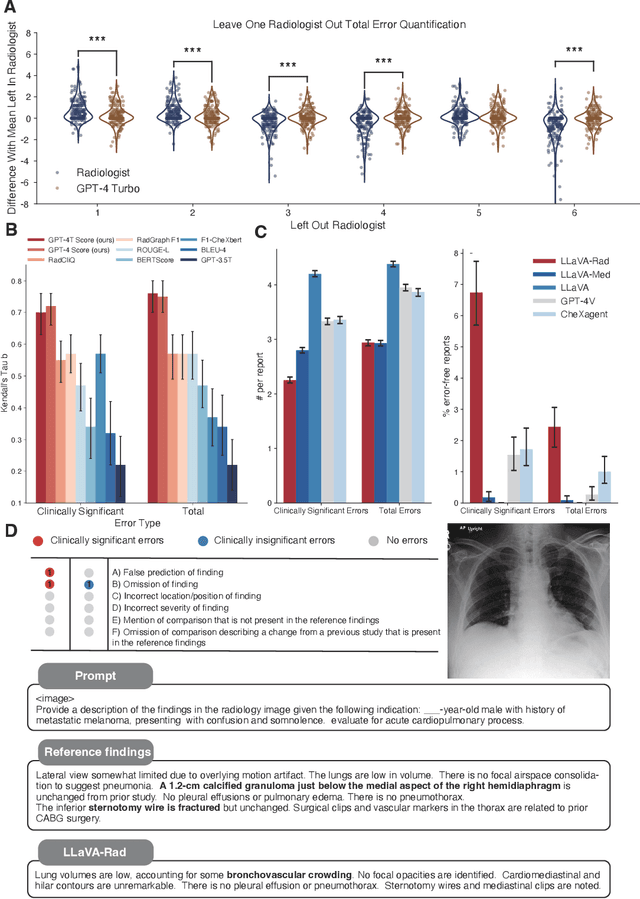
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.