 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Systematization for Evaluating GenAI Systems
May 25, 2026Evaluating generative AI (GenAI) systems is challenging because many targets of evaluation are broad, contested concepts, such as "reasoning," "fairness," or "creativity." When these concepts are left underspecified, it becomes unclear what should be measured or how evaluation results should be interpreted. This problem reflects a missing step: systematization, that is, moving from a broad background concept to an explicit, structured account of the concept in measurable terms. To help address the fact that systematization is cognitively demanding and resource-intensive, we investigate whether AI assistance can support this process. To enable AI-assisted systematization and assess its quality, we introduce a structured representation of a systematized concept, a concept spec, and a validation worksheet. We then develop two AI-assisted systematizers: a direct, zero-shot approach and a multi-agent approach that more closely mirrors manual systematization approaches from existing literature. We use these systematizers to produce concept specs for two concepts -- hate-based rhetoric and digital empathy -- and evaluate resulting concept specs on content validity and information recoverability.
Overseeing Agents Without Constant Oversight: Challenges and Opportunities
Feb 18, 2026To enable human oversight, agentic AI systems often provide a trace of reasoning and action steps. Designing traces to have an informative, but not overwhelming, level of detail remains a critical challenge. In three user studies on a Computer User Agent, we investigate the utility of basic action traces for verification, explore three alternatives via design probes, and test a novel interface's impact on error finding in question-answering tasks. As expected, we find that current practices are cumbersome, limiting their efficacy. Conversely, our proposed design reduced the time participants spent finding errors. However, although participants reported higher levels of confidence in their decisions, their final accuracy was not meaningfully improved. To this end, our study surfaces challenges for human verification of agentic systems, including managing built-in assumptions, users' subjective and changing correctness criteria, and the shortcomings, yet importance, of communicating the agent's process.
Magentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Navigating Rifts in Human-LLM Grounding: Study and Benchmark
Mar 18, 2025Language models excel at following instructions but often struggle with the collaborative aspects of conversation that humans naturally employ. This limitation in grounding -- the process by which conversation participants establish mutual understanding -- can lead to outcomes ranging from frustrated users to serious consequences in high-stakes scenarios. To systematically study grounding challenges in human-LLM interactions, we analyze logs from three human-assistant datasets: WildChat, MultiWOZ, and Bing Chat. We develop a taxonomy of grounding acts and build models to annotate and forecast grounding behavior. Our findings reveal significant differences in human-human and human-LLM grounding: LLMs were three times less likely to initiate clarification and sixteen times less likely to provide follow-up requests than humans. Additionally, early grounding failures predicted later interaction breakdowns. Building on these insights, we introduce RIFTS: a benchmark derived from publicly available LLM interaction data containing situations where LLMs fail to initiate grounding. We note that current frontier models perform poorly on RIFTS, highlighting the need to reconsider how we train and prompt LLMs for human interaction. To this end, we develop a preliminary intervention that mitigates grounding failures.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024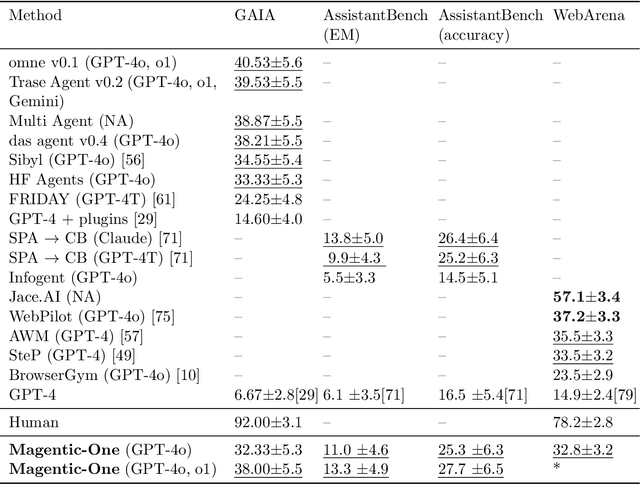
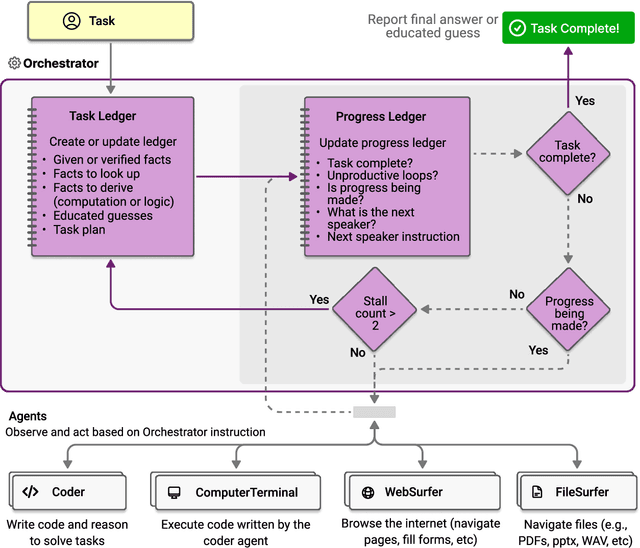
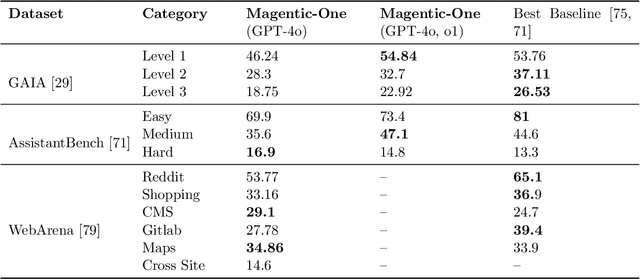
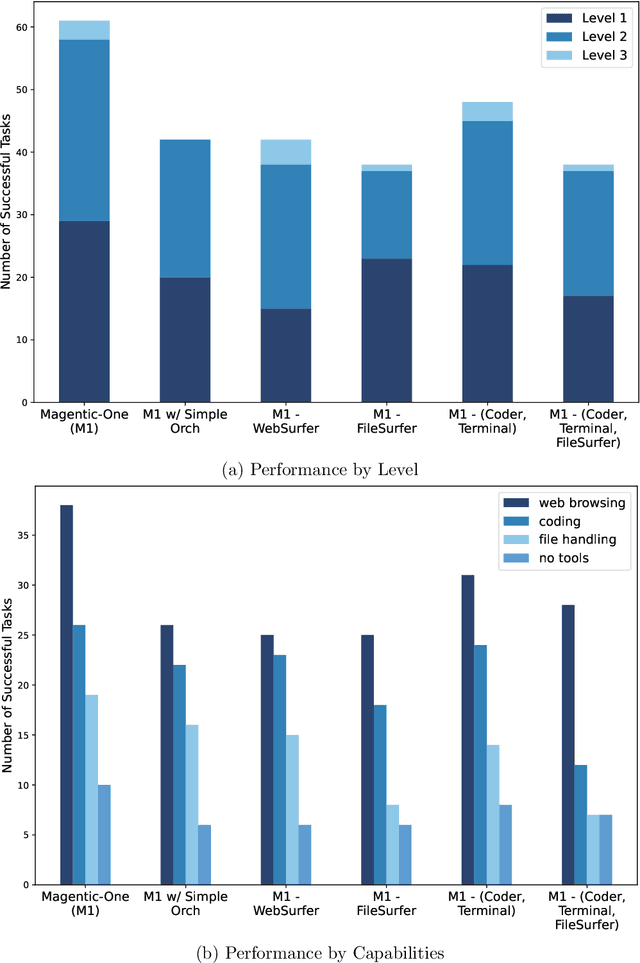
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Apr 03, 2024



Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Impact of Large Language Model Assistance on Patients Reading Clinical Notes: A Mixed-Methods Study
Jan 17, 2024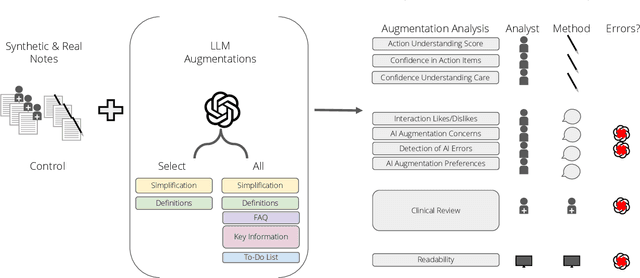
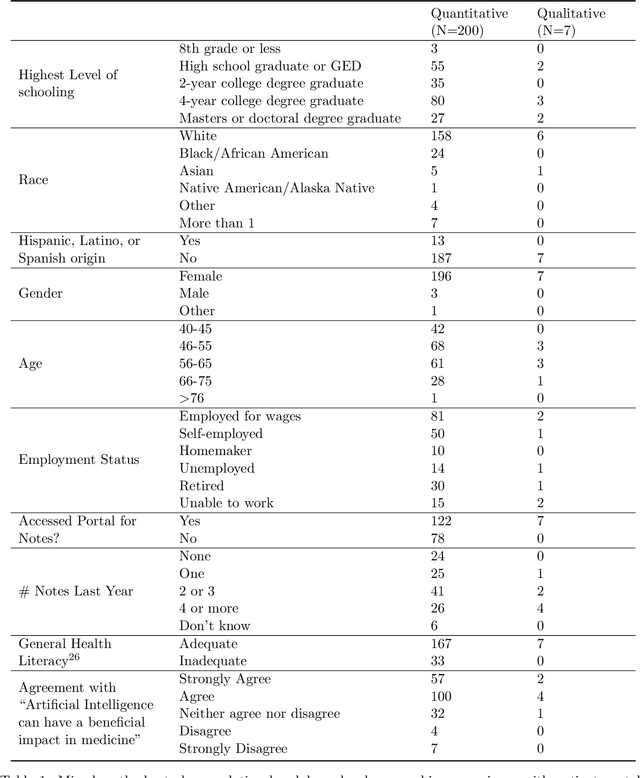
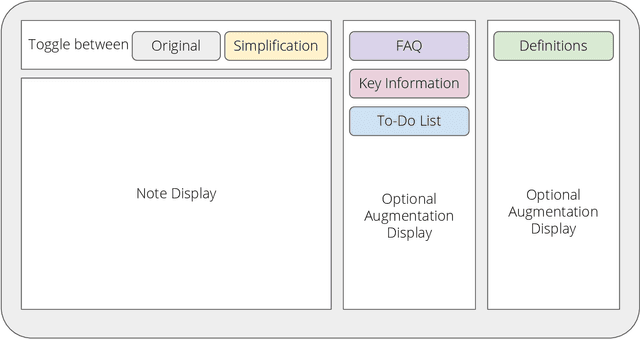
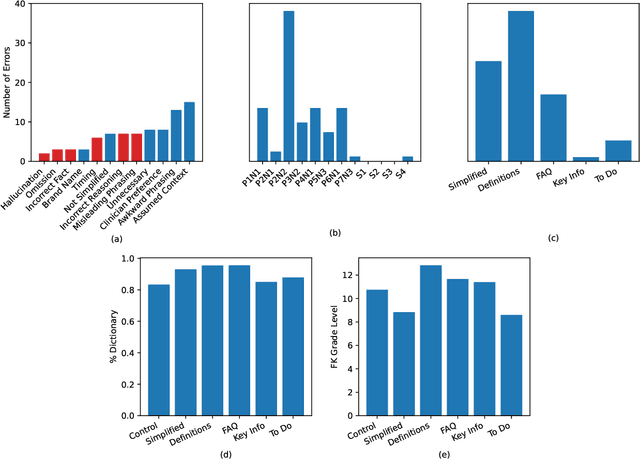
Patients derive numerous benefits from reading their clinical notes, including an increased sense of control over their health and improved understanding of their care plan. However, complex medical concepts and jargon within clinical notes hinder patient comprehension and may lead to anxiety. We developed a patient-facing tool to make clinical notes more readable, leveraging large language models (LLMs) to simplify, extract information from, and add context to notes. We prompt engineered GPT-4 to perform these augmentation tasks on real clinical notes donated by breast cancer survivors and synthetic notes generated by a clinician, a total of 12 notes with 3868 words. In June 2023, 200 female-identifying US-based participants were randomly assigned three clinical notes with varying levels of augmentations using our tool. Participants answered questions about each note, evaluating their understanding of follow-up actions and self-reported confidence. We found that augmentations were associated with a significant increase in action understanding score (0.63 $\pm$ 0.04 for select augmentations, compared to 0.54 $\pm$ 0.02 for the control) with p=0.002. In-depth interviews of self-identifying breast cancer patients (N=7) were also conducted via video conferencing. Augmentations, especially definitions, elicited positive responses among the seven participants, with some concerns about relying on LLMs. Augmentations were evaluated for errors by clinicians, and we found misleading errors occur, with errors more common in real donated notes than synthetic notes, illustrating the importance of carefully written clinical notes. Augmentations improve some but not all readability metrics. This work demonstrates the potential of LLMs to improve patients' experience with clinical notes at a lower burden to clinicians. However, having a human in the loop is important to correct potential model errors.
Effective Human-AI Teams via Learned Natural Language Rules and Onboarding
Nov 07, 2023People are relying on AI agents to assist them with various tasks. The human must know when to rely on the agent, collaborate with the agent, or ignore its suggestions. In this work, we propose to learn rules, grounded in data regions and described in natural language, that illustrate how the human should collaborate with the AI. Our novel region discovery algorithm finds local regions in the data as neighborhoods in an embedding space where prior human behavior should be corrected. Each region is then described using a large language model in an iterative and contrastive procedure. We then teach these rules to the human via an onboarding stage. Through user studies on object detection and question-answering tasks, we show that our method can lead to more accurate human-AI teams. We also evaluate our region discovery and description algorithms separately.
In Defense of Softmax Parametrization for Calibrated and Consistent Learning to Defer
Nov 02, 2023Enabling machine learning classifiers to defer their decision to a downstream expert when the expert is more accurate will ensure improved safety and performance. This objective can be achieved with the learning-to-defer framework which aims to jointly learn how to classify and how to defer to the expert. In recent studies, it has been theoretically shown that popular estimators for learning to defer parameterized with softmax provide unbounded estimates for the likelihood of deferring which makes them uncalibrated. However, it remains unknown whether this is due to the widely used softmax parameterization and if we can find a softmax-based estimator that is both statistically consistent and possesses a valid probability estimator. In this work, we first show that the cause of the miscalibrated and unbounded estimator in prior literature is due to the symmetric nature of the surrogate losses used and not due to softmax. We then propose a novel statistically consistent asymmetric softmax-based surrogate loss that can produce valid estimates without the issue of unboundedness. We further analyze the non-asymptotic properties of our method and empirically validate its performance and calibration on benchmark datasets.