 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Large Language Model Assistance on Patients Reading Clinical Notes: A Mixed-Methods Study
Jan 17, 2024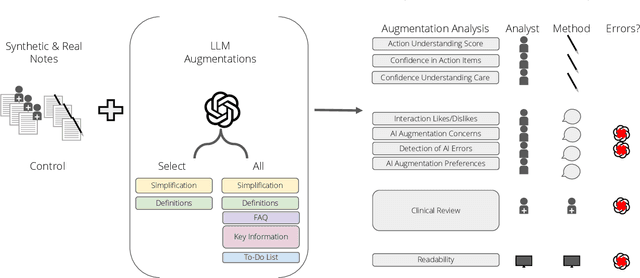
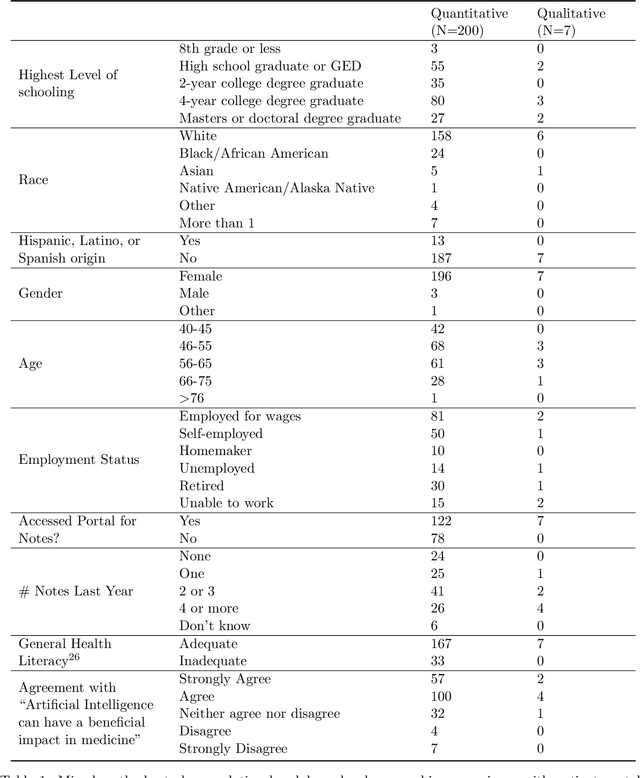
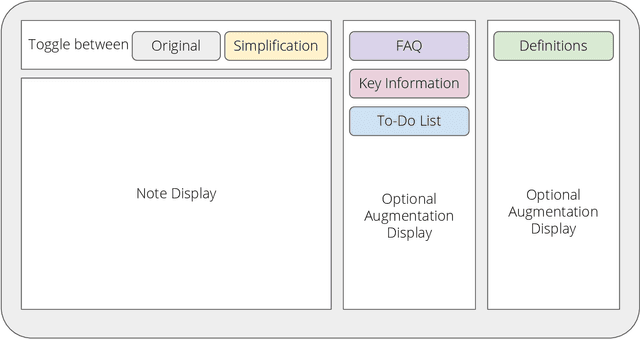
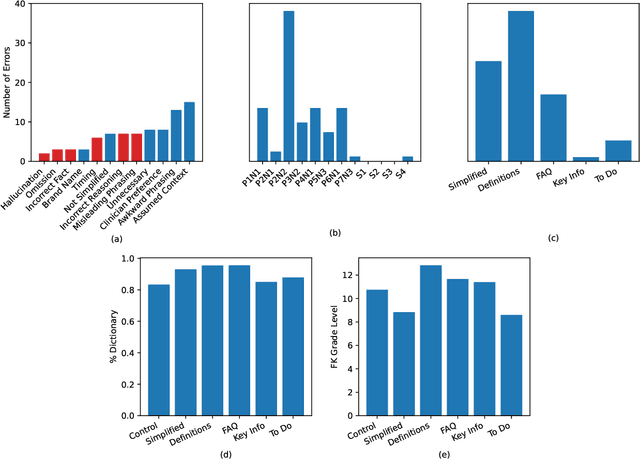
Patients derive numerous benefits from reading their clinical notes, including an increased sense of control over their health and improved understanding of their care plan. However, complex medical concepts and jargon within clinical notes hinder patient comprehension and may lead to anxiety. We developed a patient-facing tool to make clinical notes more readable, leveraging large language models (LLMs) to simplify, extract information from, and add context to notes. We prompt engineered GPT-4 to perform these augmentation tasks on real clinical notes donated by breast cancer survivors and synthetic notes generated by a clinician, a total of 12 notes with 3868 words. In June 2023, 200 female-identifying US-based participants were randomly assigned three clinical notes with varying levels of augmentations using our tool. Participants answered questions about each note, evaluating their understanding of follow-up actions and self-reported confidence. We found that augmentations were associated with a significant increase in action understanding score (0.63 $\pm$ 0.04 for select augmentations, compared to 0.54 $\pm$ 0.02 for the control) with p=0.002. In-depth interviews of self-identifying breast cancer patients (N=7) were also conducted via video conferencing. Augmentations, especially definitions, elicited positive responses among the seven participants, with some concerns about relying on LLMs. Augmentations were evaluated for errors by clinicians, and we found misleading errors occur, with errors more common in real donated notes than synthetic notes, illustrating the importance of carefully written clinical notes. Augmentations improve some but not all readability metrics. This work demonstrates the potential of LLMs to improve patients' experience with clinical notes at a lower burden to clinicians. However, having a human in the loop is important to correct potential model errors.
TabLLM: Few-shot Classification of Tabular Data with Large Language Models
Oct 19, 2022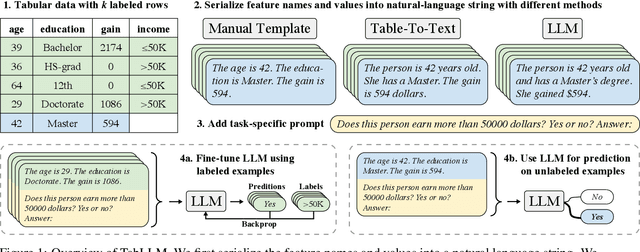
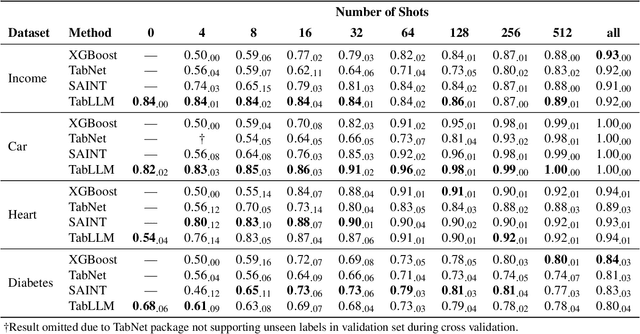
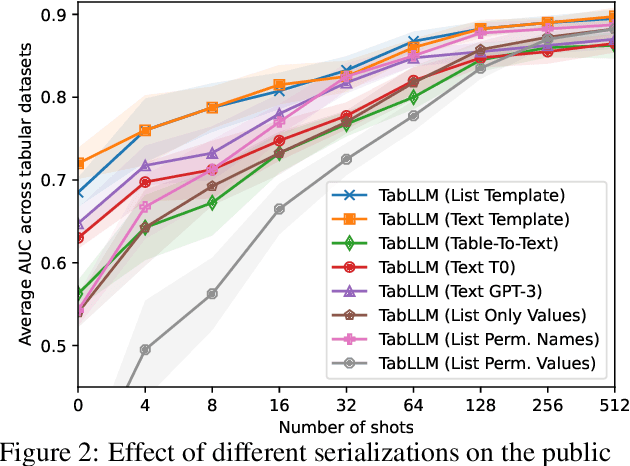
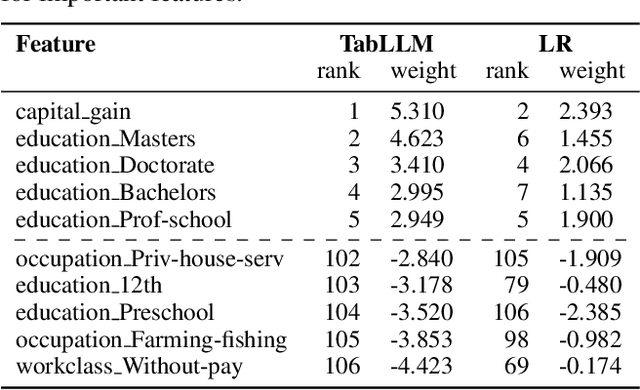
We study the application of large language models to zero-shot and few-shot classification of tabular data. We prompt the large language model with a serialization of the tabular data to a natural-language string, together with a short description of the classification problem. In the few-shot setting, we fine-tune the large language model using some labeled examples. We evaluate several serialization methods including templates, table-to-text models, and large language models. Despite its simplicity, we find that this technique outperforms prior deep-learning-based tabular classification methods on several benchmark datasets. In most cases, even zero-shot classification obtains non-trivial performance, illustrating the method's ability to exploit prior knowledge encoded in large language models. Unlike many deep learning methods for tabular datasets, this approach is also competitive with strong traditional baselines like gradient-boosted trees, especially in the very-few-shot setting.
Examination and Extension of Strategies for Improving Personalized Language Modeling via Interpolation
Jun 09, 2020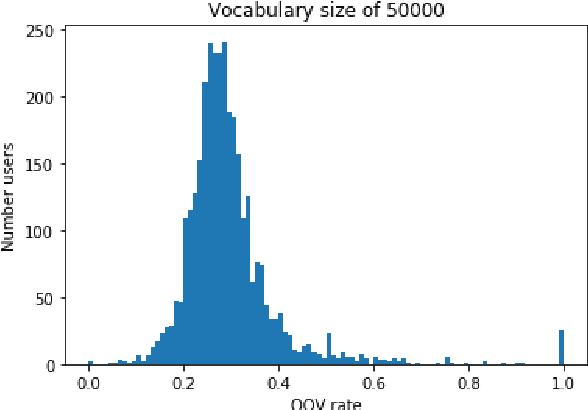
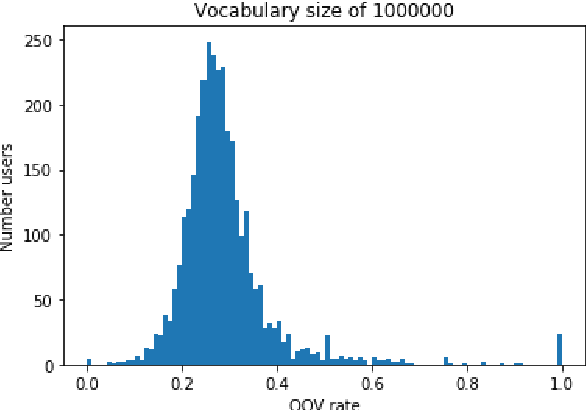

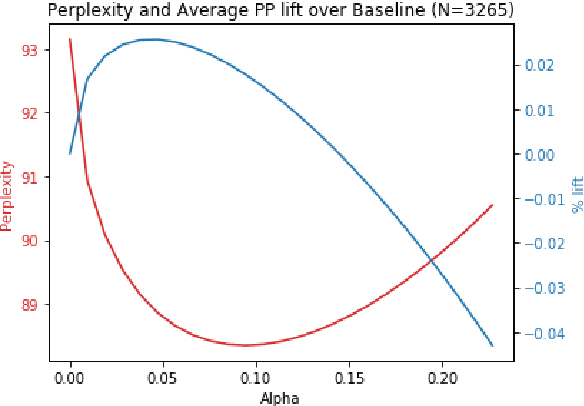
In this paper, we detail novel strategies for interpolating personalized language models and methods to handle out-of-vocabulary (OOV) tokens to improve personalized language models. Using publicly available data from Reddit, we demonstrate improvements in offline metrics at the user level by interpolating a global LSTM-based authoring model with a user-personalized n-gram model. By optimizing this approach with a back-off to uniform OOV penalty and the interpolation coefficient, we observe that over 80% of users receive a lift in perplexity, with an average of 5.2% in perplexity lift per user. In doing this research we extend previous work in building NLIs and improve the robustness of metrics for downstream tasks.