 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs can construct powerful representations and streamline sample-efficient supervised learning
Mar 12, 2026As real-world datasets become increasingly complex and heterogeneous, supervised learning is often bottlenecked by input representation design. Modeling multimodal data for downstream tasks, such as time-series, free text, and structured records, often requires non-trivial domain-specific engineering. We propose an agentic pipeline to streamline this process. First, an LLM analyzes a small but diverse subset of text-serialized input examples in-context to synthesize a global rubric, which acts as a programmatic specification for extracting and organizing evidence. This rubric is then used to transform naive text-serializations of inputs into a more standardized format for downstream models. We also describe local rubrics, which are task-conditioned summaries generated by an LLM. Across 15 clinical tasks from the EHRSHOT benchmark, our rubric-based approaches significantly outperform traditional count-feature models, naive text-serialization-based LLM baselines, and a clinical foundation model, which is pretrained on orders of magnitude more data. Beyond performance, rubrics offer several advantages for operational healthcare settings such as being easy to audit, cost-effectiveness to deploy at scale, and they can be converted to tabular representations that unlock a swath of machine learning techniques.
Completion $ eq$ Collaboration: Scaling Collaborative Effort with Agents
Oct 30, 2025Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals are often underspecified and evolve. We argue for a shift from building and assessing task completion agents to developing collaborative agents, assessed not only by the quality of their final outputs but by how well they engage with and enhance human effort throughout the problem-solving process. To support this shift, we introduce collaborative effort scaling, a framework that captures how an agent's utility grows with increasing user involvement. Through case studies and simulated evaluations, we show that state-of-the-art agents often underperform in multi-turn, real-world scenarios, revealing a missing ingredient in agent design: the ability to sustain engagement and scaffold user understanding. Collaborative effort scaling offers a lens for diagnosing agent behavior and guiding development toward more effective interactions.
Diagnosing our datasets: How does my language model learn clinical information?
May 21, 2025Large language models (LLMs) have performed well across various clinical natural language processing tasks, despite not being directly trained on electronic health record (EHR) data. In this work, we examine how popular open-source LLMs learn clinical information from large mined corpora through two crucial but understudied lenses: (1) their interpretation of clinical jargon, a foundational ability for understanding real-world clinical notes, and (2) their responses to unsupported medical claims. For both use cases, we investigate the frequency of relevant clinical information in their corresponding pretraining corpora, the relationship between pretraining data composition and model outputs, and the sources underlying this data. To isolate clinical jargon understanding, we evaluate LLMs on a new dataset MedLingo. Unsurprisingly, we find that the frequency of clinical jargon mentions across major pretraining corpora correlates with model performance. However, jargon frequently appearing in clinical notes often rarely appears in pretraining corpora, revealing a mismatch between available data and real-world usage. Similarly, we find that a non-negligible portion of documents support disputed claims that can then be parroted by models. Finally, we classified and analyzed the types of online sources in which clinical jargon and unsupported medical claims appear, with implications for future dataset composition.
Large Language Models are Powerful EHR Encoders
Feb 24, 2025Electronic Health Records (EHRs) offer rich potential for clinical prediction, yet their inherent complexity and heterogeneity pose significant challenges for traditional machine learning approaches. Domain-specific EHR foundation models trained on large collections of unlabeled EHR data have demonstrated promising improvements in predictive accuracy and generalization; however, their training is constrained by limited access to diverse, high-quality datasets and inconsistencies in coding standards and healthcare practices. In this study, we explore the possibility of using general-purpose Large Language Models (LLMs) based embedding methods as EHR encoders. By serializing patient records into structured Markdown text, transforming codes into human-readable descriptors, we leverage the extensive generalization capabilities of LLMs pretrained on vast public corpora, thereby bypassing the need for proprietary medical datasets. We systematically evaluate two state-of-the-art LLM-embedding models, GTE-Qwen2-7B-Instruct and LLM2Vec-Llama3.1-8B-Instruct, across 15 diverse clinical prediction tasks from the EHRSHOT benchmark, comparing their performance to an EHRspecific foundation model, CLIMBR-T-Base, and traditional machine learning baselines. Our results demonstrate that LLM-based embeddings frequently match or exceed the performance of specialized models, even in few-shot settings, and that their effectiveness scales with the size of the underlying LLM and the available context window. Overall, our findings demonstrate that repurposing LLMs for EHR encoding offers a scalable and effective approach for clinical prediction, capable of overcoming the limitations of traditional EHR modeling and facilitating more interoperable and generalizable healthcare applications.
Probably approximately correct high-dimensional causal effect estimation given a valid adjustment set
Nov 12, 2024Accurate estimates of causal effects play a key role in decision-making across applications such as healthcare, economics, and operations. In the absence of randomized experiments, a common approach to estimating causal effects uses \textit{covariate adjustment}. In this paper, we study covariate adjustment for discrete distributions from the PAC learning perspective, assuming knowledge of a valid adjustment set $\bZ$, which might be high-dimensional. Our first main result PAC-bounds the estimation error of covariate adjustment by a term that is exponential in the size of the adjustment set; it is known that such a dependency is unavoidable even if one only aims to minimize the mean squared error. Motivated by this result, we introduce the notion of an \emph{$\eps$-Markov blanket}, give bounds on the misspecification error of using such a set for covariate adjustment, and provide an algorithm for $\eps$-Markov blanket discovery; our second main result upper bounds the sample complexity of this algorithm. Furthermore, we provide a misspecification error bound and a constraint-based algorithm that allow us to go beyond $\eps$-Markov blankets to even smaller adjustment sets. Our third main result upper bounds the sample complexity of this algorithm, and our final result combines the first three into an overall PAC bound. Altogether, our results highlight that one does not need to perfectly recover causal structure in order to ensure accurate estimates of causal effects.
Seq-to-Final: A Benchmark for Tuning from Sequential Distributions to a Final Time Point
Jul 12, 2024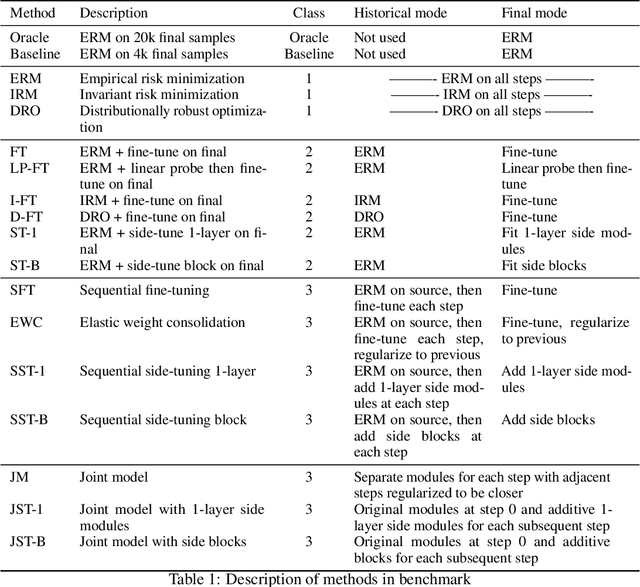



Distribution shift over time occurs in many settings. Leveraging historical data is necessary to learn a model for the last time point when limited data is available in the final period, yet few methods have been developed specifically for this purpose. In this work, we construct a benchmark with different sequences of synthetic shifts to evaluate the effectiveness of 3 classes of methods that 1) learn from all data without adapting to the final period, 2) learn from historical data with no regard to the sequential nature and then adapt to the final period, and 3) leverage the sequential nature of historical data when tailoring a model to the final period. We call this benchmark Seq-to-Final to highlight the focus on using a sequence of time periods to learn a model for the final time point. Our synthetic benchmark allows users to construct sequences with different types of shift and compare different methods. We focus on image classification tasks using CIFAR-10 and CIFAR-100 as the base images for the synthetic sequences. We also evaluate the same methods on the Portraits dataset to explore the relevance to real-world shifts over time. Finally, we create a visualization to contrast the initializations and updates from different methods at the final time step. Our results suggest that, for the sequences in our benchmark, methods that disregard the sequential structure and adapt to the final time point tend to perform well. The approaches we evaluate that leverage the sequential nature do not offer any improvement. We hope that this benchmark will inspire the development of new algorithms that are better at leveraging sequential historical data or a deeper understanding of why methods that disregard the sequential nature are able to perform well.
Prediction-powered Generalization of Causal Inferences
Jun 05, 2024Causal inferences from a randomized controlled trial (RCT) may not pertain to a target population where some effect modifiers have a different distribution. Prior work studies generalizing the results of a trial to a target population with no outcome but covariate data available. We show how the limited size of trials makes generalization a statistically infeasible task, as it requires estimating complex nuisance functions. We develop generalization algorithms that supplement the trial data with a prediction model learned from an additional observational study (OS), without making any assumptions on the OS. We theoretically and empirically show that our methods facilitate better generalization when the OS is high-quality, and remain robust when it is not, and e.g., have unmeasured confounding.
Theoretical Analysis of Weak-to-Strong Generalization
May 25, 2024Strong student models can learn from weaker teachers: when trained on the predictions of a weaker model, a strong pretrained student can learn to correct the weak model's errors and generalize to examples where the teacher is not confident, even when these examples are excluded from training. This enables learning from cheap, incomplete, and possibly incorrect label information, such as coarse logical rules or the generations of a language model. We show that existing weak supervision theory fails to account for both of these effects, which we call pseudolabel correction and coverage expansion, respectively. We give a new bound based on expansion properties of the data distribution and student hypothesis class that directly accounts for pseudolabel correction and coverage expansion. Our bounds capture the intuition that weak-to-strong generalization occurs when the strong model is unable to fit the mistakes of the weak teacher without incurring additional error. We show that these expansion properties can be checked from finite data and give empirical evidence that they hold in practice.
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Apr 03, 2024



Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
Learning to Decode Collaboratively with Multiple Language Models
Mar 06, 2024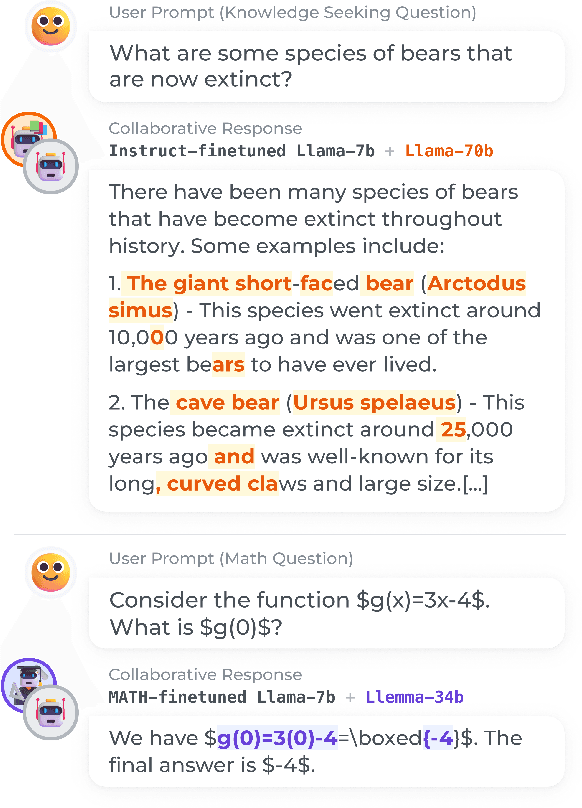
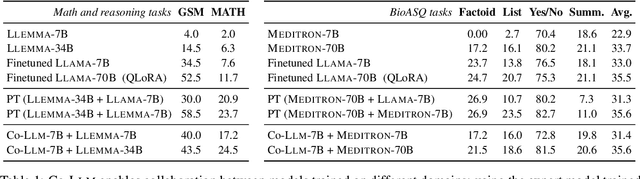


We propose a method to teach multiple large language models (LLM) to collaborate by interleaving their generations at the token level. We model the decision of which LLM generates the next token as a latent variable. By optimizing the marginal likelihood of a training set under our latent variable model, the base LLM automatically learns when to generate itself and when to call on one of the ``assistant'' language models to generate, all without direct supervision. Token-level collaboration during decoding allows for a fusion of each model's expertise in a manner tailored to the specific task at hand. Our collaborative decoding is especially useful in cross-domain settings where a generalist base LLM learns to invoke domain expert models. On instruction-following, domain-specific QA, and reasoning tasks, we show that the performance of the joint system exceeds that of the individual models. Through qualitative analysis of the learned latent decisions, we show models trained with our method exhibit several interesting collaboration patterns, e.g., template-filling. Our code is available at https://github.com/clinicalml/co-llm.