 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Lunch: Non-Asymptotic Analysis of Prediction-Powered Inference
May 26, 2025Prediction-Powered Inference (PPI) is a popular strategy for combining gold-standard and possibly noisy pseudo-labels to perform statistical estimation. Prior work has shown an asymptotic "free lunch" for PPI++, an adaptive form of PPI, showing that the *asymptotic* variance of PPI++ is always less than or equal to the variance obtained from using gold-standard labels alone. Notably, this result holds *regardless of the quality of the pseudo-labels*. In this work, we demystify this result by conducting an exact finite-sample analysis of the estimation error of PPI++ on the mean estimation problem. We give a "no free lunch" result, characterizing the settings (and sample sizes) where PPI++ has provably worse estimation error than using gold-standard labels alone. Specifically, PPI++ will outperform if and only if the correlation between pseudo- and gold-standard is above a certain level that depends on the number of labeled samples ($n$). In some cases our results simplify considerably: For Gaussian data, the correlation must be at least $1/\sqrt{n - 2}$ in order to see improvement, and a similar result holds for binary labels. In experiments, we illustrate that our theoretical findings hold on real-world datasets, and give insights into trade-offs between single-sample and sample-splitting variants of PPI++.
Generate to Discriminate: Expert Routing for Continual Learning
Dec 22, 2024In many real-world settings, regulations and economic incentives permit the sharing of models but not data across institutional boundaries. In such scenarios, practitioners might hope to adapt models to new domains, without losing performance on previous domains (so-called catastrophic forgetting). While any single model may struggle to achieve this goal, learning an ensemble of domain-specific experts offers the potential to adapt more closely to each individual institution. However, a core challenge in this context is determining which expert to deploy at test time. In this paper, we propose Generate to Discriminate (G2D), a domain-incremental continual learning method that leverages synthetic data to train a domain-discriminator that routes samples at inference time to the appropriate expert. Surprisingly, we find that leveraging synthetic data in this capacity is more effective than using the samples to \textit{directly} train the downstream classifier (the more common approach to leveraging synthetic data in the lifelong learning literature). We observe that G2D outperforms competitive domain-incremental learning methods on tasks in both vision and language modalities, providing a new perspective on the use of synthetic data in the lifelong learning literature.
The Limited Impact of Medical Adaptation of Large Language and Vision-Language Models
Nov 13, 2024



Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining (DAPT) improves performance on downstream medical tasks, such as answering medical licensing exam questions. In this paper, we compare ten public "medical" LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting and supervised fine-tuning regimes for medical question-answering (QA). For instance, across all tasks and model pairs we consider in the 3-shot setting, medical LLMs only outperform their base models in 22.7% of cases, reach a (statistical) tie in 36.8% of cases, and are significantly worse than their base models in the remaining 40.5% of cases. Our conclusions are based on (i) comparing each medical model head-to-head, directly against the corresponding base model; (ii) optimizing the prompts for each model separately in zero-/few-shot prompting; and (iii) accounting for statistical uncertainty in comparisons. While these basic practices are not consistently adopted in the literature, our ablations show that they substantially impact conclusions. Meanwhile, we find that after fine-tuning on specific QA tasks, medical LLMs can show performance improvements, but the benefits do not carry over to tasks based on clinical notes. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?
Nov 06, 2024



Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining (DAPT) improves performance on downstream medical tasks, such as answering medical licensing exam questions. In this paper, we compare seven public "medical" LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting regime for medical question-answering (QA) tasks. For instance, across the tasks and model pairs we consider in the 3-shot setting, medical LLMs only outperform their base models in 12.1% of cases, reach a (statistical) tie in 49.8% of cases, and are significantly worse than their base models in the remaining 38.2% of cases. Our conclusions are based on (i) comparing each medical model head-to-head, directly against the corresponding base model; (ii) optimizing the prompts for each model separately; and (iii) accounting for statistical uncertainty in comparisons. While these basic practices are not consistently adopted in the literature, our ablations show that they substantially impact conclusions. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
Auditing Fairness under Unobserved Confounding
Mar 18, 2024



A fundamental problem in decision-making systems is the presence of inequity across demographic lines. However, inequity can be difficult to quantify, particularly if our notion of equity relies on hard-to-measure notions like risk (e.g., equal access to treatment for those who would die without it). Auditing such inequity requires accurate measurements of individual risk, which is difficult to estimate in the realistic setting of unobserved confounding. In the case that these unobservables "explain" an apparent disparity, we may understate or overstate inequity. In this paper, we show that one can still give informative bounds on allocation rates among high-risk individuals, even while relaxing or (surprisingly) even when eliminating the assumption that all relevant risk factors are observed. We utilize the fact that in many real-world settings (e.g., the introduction of a novel treatment) we have data from a period prior to any allocation, to derive unbiased estimates of risk. We demonstrate the effectiveness of our framework on a real-world study of Paxlovid allocation to COVID-19 patients, finding that observed racial inequity cannot be explained by unobserved confounders of the same strength as important observed covariates.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Benchmarking Observational Studies with Experimental Data under Right-Censoring
Feb 23, 2024



Drawing causal inferences from observational studies (OS) requires unverifiable validity assumptions; however, one can falsify those assumptions by benchmarking the OS with experimental data from a randomized controlled trial (RCT). A major limitation of existing procedures is not accounting for censoring, despite the abundance of RCTs and OSes that report right-censored time-to-event outcomes. We consider two cases where censoring time (1) is independent of time-to-event and (2) depends on time-to-event the same way in OS and RCT. For the former, we adopt a censoring-doubly-robust signal for the conditional average treatment effect (CATE) to facilitate an equivalence test of CATEs in OS and RCT, which serves as a proxy for testing if the validity assumptions hold. For the latter, we show that the same test can still be used even though unbiased CATE estimation may not be possible. We verify the effectiveness of our censoring-aware tests via semi-synthetic experiments and analyze RCT and OS data from the Women's Health Initiative study.
Falsification of Internal and External Validity in Observational Studies via Conditional Moment Restrictions
Jan 30, 2023



Randomized Controlled Trials (RCT)s are relied upon to assess new treatments, but suffer from limited power to guide personalized treatment decisions. On the other hand, observational (i.e., non-experimental) studies have large and diverse populations, but are prone to various biases (e.g. residual confounding). To safely leverage the strengths of observational studies, we focus on the problem of falsification, whereby RCTs are used to validate causal effect estimates learned from observational data. In particular, we show that, given data from both an RCT and an observational study, assumptions on internal and external validity have an observable, testable implication in the form of a set of Conditional Moment Restrictions (CMRs). Further, we show that expressing these CMRs with respect to the causal effect, or "causal contrast", as opposed to individual counterfactual means, provides a more reliable falsification test. In addition to giving guarantees on the asymptotic properties of our test, we demonstrate superior power and type I error of our approach on semi-synthetic and real world datasets. Our approach is interpretable, allowing a practitioner to visualize which subgroups in the population lead to falsification of an observational study.
Falsification before Extrapolation in Causal Effect Estimation
Sep 29, 2022
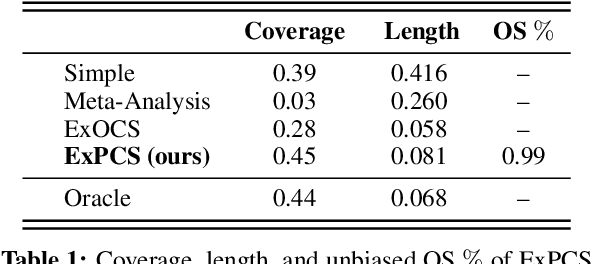
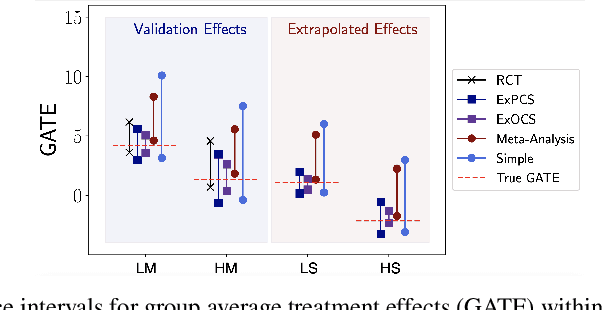

Randomized Controlled Trials (RCTs) represent a gold standard when developing policy guidelines. However, RCTs are often narrow, and lack data on broader populations of interest. Causal effects in these populations are often estimated using observational datasets, which may suffer from unobserved confounding and selection bias. Given a set of observational estimates (e.g. from multiple studies), we propose a meta-algorithm that attempts to reject observational estimates that are biased. We do so using validation effects, causal effects that can be inferred from both RCT and observational data. After rejecting estimators that do not pass this test, we generate conservative confidence intervals on the extrapolated causal effects for subgroups not observed in the RCT. Under the assumption that at least one observational estimator is asymptotically normal and consistent for both the validation and extrapolated effects, we provide guarantees on the coverage probability of the intervals output by our algorithm. To facilitate hypothesis testing in settings where causal effect transportation across datasets is necessary, we give conditions under which a doubly-robust estimator of group average treatment effects is asymptotically normal, even when flexible machine learning methods are used for estimation of nuisance parameters. We illustrate the properties of our approach on semi-synthetic and real world datasets, and show that it compares favorably to standard meta-analysis techniques.
Evaluating Robustness to Dataset Shift via Parametric Robustness Sets
May 31, 2022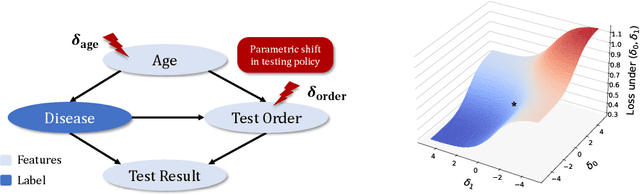


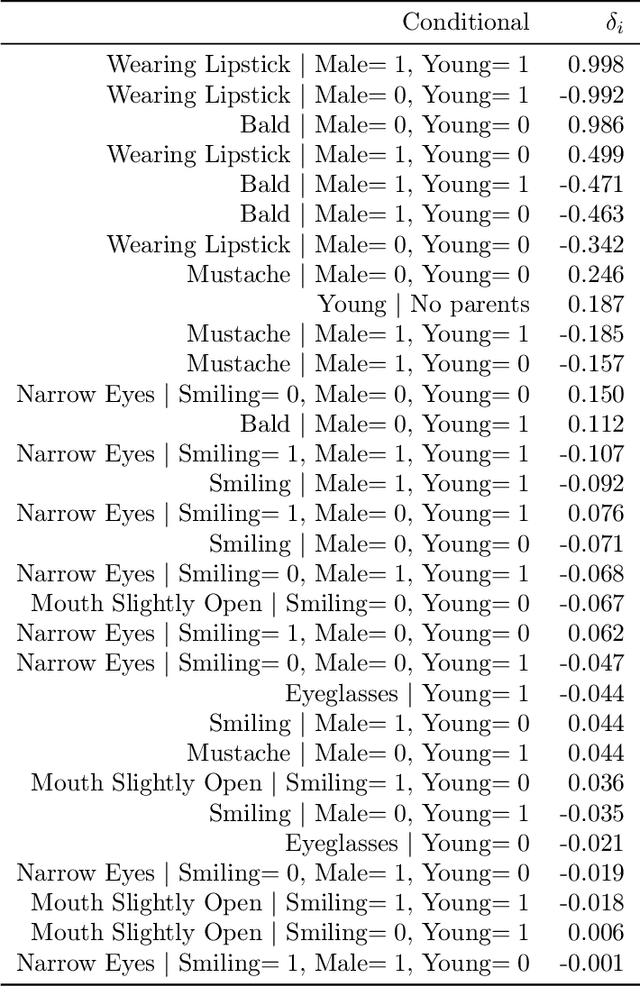
We give a method for proactively identifying small, plausible shifts in distribution which lead to large differences in model performance. To ensure that these shifts are plausible, we parameterize them in terms of interpretable changes in causal mechanisms of observed variables. This defines a parametric robustness set of plausible distributions and a corresponding worst-case loss. While the loss under an individual parametric shift can be estimated via reweighting techniques such as importance sampling, the resulting worst-case optimization problem is non-convex, and the estimate may suffer from large variance. For small shifts, however, we can construct a local second-order approximation to the loss under shift and cast the problem of finding a worst-case shift as a particular non-convex quadratic optimization problem, for which efficient algorithms are available. We demonstrate that this second-order approximation can be estimated directly for shifts in conditional exponential family models, and we bound the approximation error. We apply our approach to a computer vision task (classifying gender from images), revealing sensitivity to shifts in non-causal attributes.