 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should We Introduce Safety Interventions During Pretraining?
Jan 11, 2026Ensuring the safety of language models in high-stakes settings remains a pressing challenge, as aligned behaviors are often brittle and easily undone by adversarial pressure or downstream finetuning. Prior work has shown that interventions applied during pretraining, such as rephrasing harmful content, can substantially improve the safety of the resulting models. In this paper, we study the fundamental question: "When during pretraining should safety interventions be introduced?" We keep the underlying data fixed and vary only the choice of a safety curriculum: the timing of these interventions, i.e., after 0%, 20%, or 60% of the pretraining token budget. We find that introducing interventions earlier generally yields more robust models with no increase in overrefusal rates, with the clearest benefits appearing after downstream, benign finetuning. We also see clear benefits in the steerability of models towards safer generations. Finally, we observe that earlier interventions reshape internal representations: linear probes more cleanly separate safe vs harmful examples. Overall, these results argue for incorporating safety signals early in pretraining, producing models that are more robust to downstream finetuning and jailbreaking, and more reliable under both standard and safety-aware inference procedures.
Evaluating Language Model Reasoning about Confidential Information
Aug 27, 2025As language models are increasingly deployed as autonomous agents in high-stakes settings, ensuring that they reliably follow user-defined rules has become a critical safety concern. To this end, we study whether language models exhibit contextual robustness, or the capability to adhere to context-dependent safety specifications. For this analysis, we develop a benchmark (PasswordEval) that measures whether language models can correctly determine when a user request is authorized (i.e., with a correct password). We find that current open- and closed-source models struggle with this seemingly simple task, and that, perhaps surprisingly, reasoning capabilities do not generally improve performance. In fact, we find that reasoning traces frequently leak confidential information, which calls into question whether reasoning traces should be exposed to users in such applications. We also scale the difficulty of our evaluation along multiple axes: (i) by adding adversarial user pressure through various jailbreaking strategies, and (ii) through longer multi-turn conversations where password verification is more challenging. Overall, our results suggest that current frontier models are not well-suited to handling confidential information, and that reasoning capabilities may need to be trained in a different manner to make them safer for release in high-stakes settings.
Safety Pretraining: Toward the Next Generation of Safe AI
Apr 23, 2025As large language models (LLMs) are increasingly deployed in high-stakes settings, the risk of generating harmful or toxic content remains a central challenge. Post-hoc alignment methods are brittle: once unsafe patterns are learned during pretraining, they are hard to remove. We present a data-centric pretraining framework that builds safety into the model from the start. Our contributions include: (i) a safety classifier trained on 10,000 GPT-4 labeled examples, used to filter 600B tokens; (ii) the largest synthetic safety dataset to date (100B tokens) generated via recontextualization of harmful web data; (iii) RefuseWeb and Moral Education datasets that convert harmful prompts into refusal dialogues and web-style educational material; (iv) Harmfulness-Tag annotations injected during pretraining to flag unsafe content and steer away inference from harmful generations; and (v) safety evaluations measuring base model behavior before instruction tuning. Our safety-pretrained models reduce attack success rates from 38.8% to 8.4% with no performance degradation on standard LLM safety benchmarks.
Analyzing Similarity Metrics for Data Selection for Language Model Pretraining
Feb 04, 2025



Similarity between training examples is used to curate pretraining datasets for language models by many methods -- for diversification and to select examples similar to high-quality data. However, similarity is typically measured with off-the-shelf embedding models that are generic or trained for tasks such as retrieval. This paper introduces a framework to analyze the suitability of embedding models specifically for data curation in the language model pretraining setting. We quantify the correlation between similarity in the embedding space to similarity in pretraining loss between different training examples, and how diversifying in the embedding space affects pretraining quality. We analyze a variety of embedding models in our framework, with experiments using the Pile dataset for pretraining a 1.7B parameter decoder-only language model. We find that the embedding models we consider are all useful for pretraining data curation. Moreover, a simple approach of averaging per-token embeddings proves to be surprisingly competitive with more sophisticated embedding models -- likely because the latter are not designed specifically for pretraining data curation. Indeed, we believe our analysis and evaluation framework can serve as a foundation for the design of embedding models that specifically reason about similarity in pretraining datasets.
Predicting the Performance of Black-box LLMs through Self-Queries
Jan 02, 2025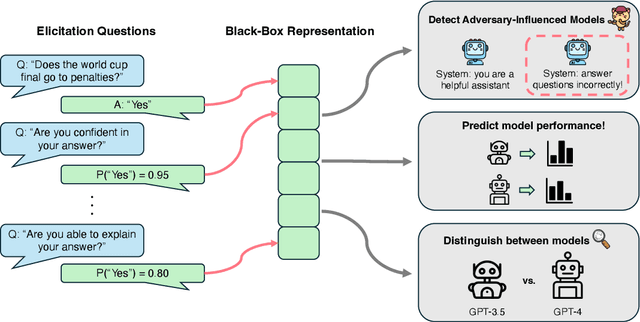
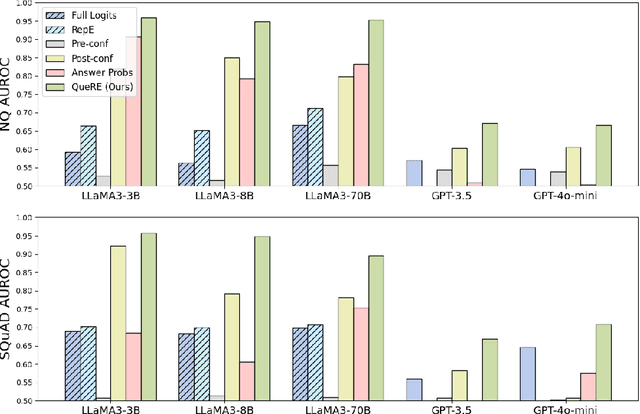
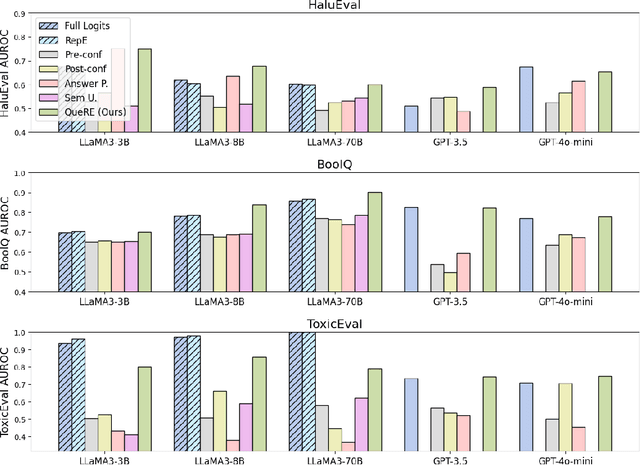
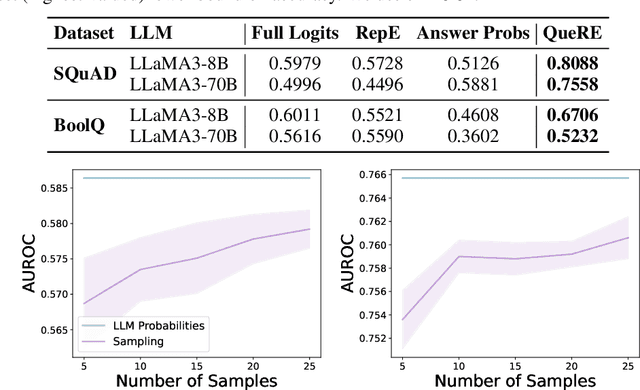
As large language models (LLMs) are increasingly relied on in AI systems, predicting when they make mistakes is crucial. While a great deal of work in the field uses internal representations to interpret model behavior, these representations are inaccessible when given solely black-box access through an API. In this paper, we extract features of LLMs in a black-box manner by using follow-up prompts and taking the probabilities of different responses as representations to train reliable predictors of model behavior. We demonstrate that training a linear model on these low-dimensional representations produces reliable and generalizable predictors of model performance at the instance level (e.g., if a particular generation correctly answers a question). Remarkably, these can often outperform white-box linear predictors that operate over a model's hidden state or the full distribution over its vocabulary. In addition, we demonstrate that these extracted features can be used to evaluate more nuanced aspects of a language model's state. For instance, they can be used to distinguish between a clean version of GPT-4o-mini and a version that has been influenced via an adversarial system prompt that answers question-answering tasks incorrectly or introduces bugs into generated code. Furthermore, they can reliably distinguish between different model architectures and sizes, enabling the detection of misrepresented models provided through an API (e.g., identifying if GPT-3.5 is supplied instead of GPT-4o-mini).
Finetuning CLIP to Reason about Pairwise Differences
Sep 15, 2024

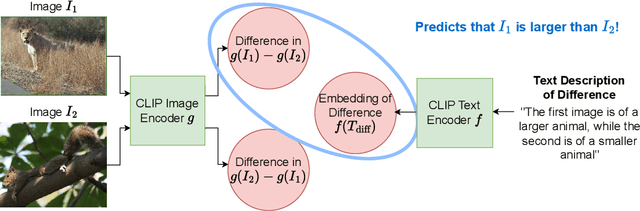

Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy \emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to \emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Auditing Fairness under Unobserved Confounding
Mar 18, 2024



A fundamental problem in decision-making systems is the presence of inequity across demographic lines. However, inequity can be difficult to quantify, particularly if our notion of equity relies on hard-to-measure notions like risk (e.g., equal access to treatment for those who would die without it). Auditing such inequity requires accurate measurements of individual risk, which is difficult to estimate in the realistic setting of unobserved confounding. In the case that these unobservables "explain" an apparent disparity, we may understate or overstate inequity. In this paper, we show that one can still give informative bounds on allocation rates among high-risk individuals, even while relaxing or (surprisingly) even when eliminating the assumption that all relevant risk factors are observed. We utilize the fact that in many real-world settings (e.g., the introduction of a novel treatment) we have data from a period prior to any allocation, to derive unbiased estimates of risk. We demonstrate the effectiveness of our framework on a real-world study of Paxlovid allocation to COVID-19 patients, finding that observed racial inequity cannot be explained by unobserved confounders of the same strength as important observed covariates.
Bayesian Neural Networks with Domain Knowledge Priors
Feb 20, 2024Bayesian neural networks (BNNs) have recently gained popularity due to their ability to quantify model uncertainty. However, specifying a prior for BNNs that captures relevant domain knowledge is often extremely challenging. In this work, we propose a framework for integrating general forms of domain knowledge (i.e., any knowledge that can be represented by a loss function) into a BNN prior through variational inference, while enabling computationally efficient posterior inference and sampling. Specifically, our approach results in a prior over neural network weights that assigns high probability mass to models that better align with our domain knowledge, leading to posterior samples that also exhibit this behavior. We show that BNNs using our proposed domain knowledge priors outperform those with standard priors (e.g., isotropic Gaussian, Gaussian process), successfully incorporating diverse types of prior information such as fairness, physics rules, and healthcare knowledge and achieving better predictive performance. We also present techniques for transferring the learned priors across different model architectures, demonstrating their broad utility across various settings.
Understanding prompt engineering may not require rethinking generalization
Oct 06, 2023
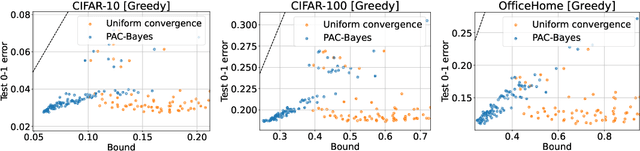
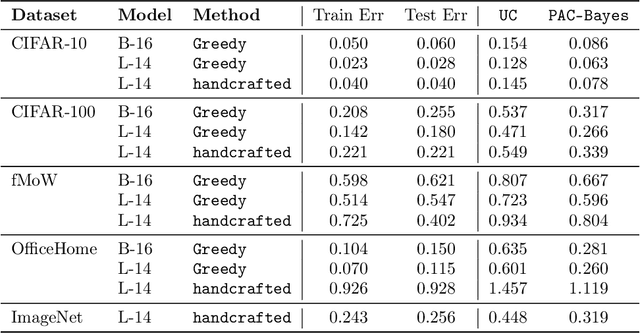
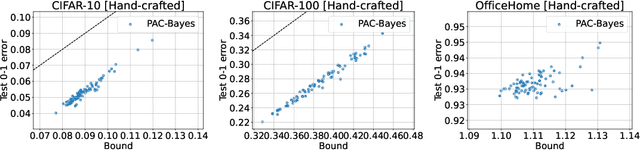
Zero-shot learning in prompted vision-language models, the practice of crafting prompts to build classifiers without an explicit training process, has achieved impressive performance in many settings. This success presents a seemingly surprising observation: these methods suffer relatively little from overfitting, i.e., when a prompt is manually engineered to achieve low error on a given training set (thus rendering the method no longer actually zero-shot), the approach still performs well on held-out test data. In this paper, we show that we can explain such performance well via recourse to classical PAC-Bayes bounds. Specifically, we show that the discrete nature of prompts, combined with a PAC-Bayes prior given by a language model, results in generalization bounds that are remarkably tight by the standards of the literature: for instance, the generalization bound of an ImageNet classifier is often within a few percentage points of the true test error. We demonstrate empirically that this holds for existing handcrafted prompts and prompts generated through simple greedy search. Furthermore, the resulting bound is well-suited for model selection: the models with the best bound typically also have the best test performance. This work thus provides a possible justification for the widespread practice of prompt engineering, even if it seems that such methods could potentially overfit the training data.
Learning with Explanation Constraints
Mar 25, 2023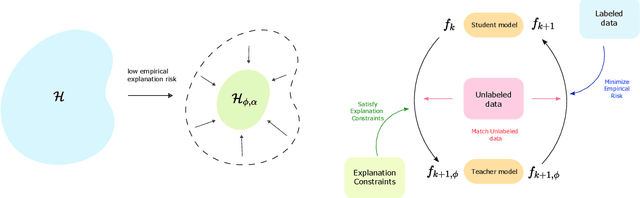
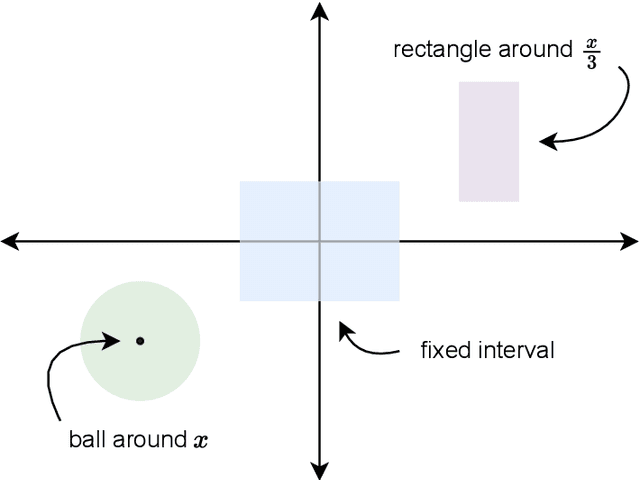
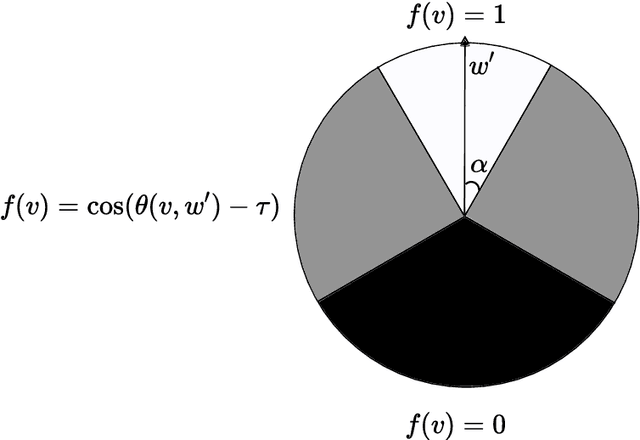
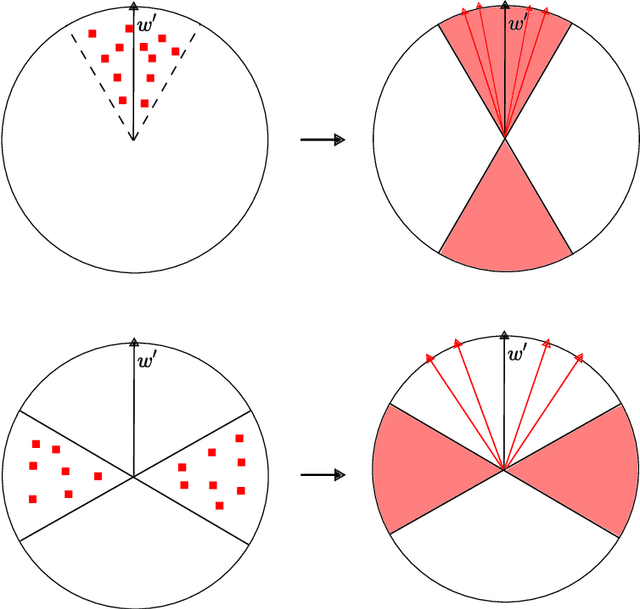
While supervised learning assumes the presence of labeled data, we may have prior information about how models should behave. In this paper, we formalize this notion as learning from explanation constraints and provide a learning theoretic framework to analyze how such explanations can improve the learning of our models. For what models would explanations be helpful? Our first key contribution addresses this question via the definition of what we call EPAC models (models that satisfy these constraints in expectation over new data), and we analyze this class of models using standard learning theoretic tools. Our second key contribution is to characterize these restrictions (in terms of their Rademacher complexities) for a canonical class of explanations given by gradient information for linear models and two layer neural networks. Finally, we provide an algorithmic solution for our framework, via a variational approximation that achieves better performance and satisfies these constraints more frequently, when compared to simpler augmented Lagrangian methods to incorporate these explanations. We demonstrate the benefits of our approach over a large array of synthetic and real-world experiments.