 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Multimodal Reasoning in Large Models for Direct Robot Manipulation
May 19, 2025Recent Large Multimodal Models have demonstrated remarkable reasoning capabilities, especially in solving complex mathematical problems and realizing accurate spatial perception. Our key insight is that these emerging abilities can naturally extend to robotic manipulation by enabling LMMs to directly infer the next goal in language via reasoning, rather than relying on a separate action head. However, this paradigm meets two main challenges: i) How to make LMMs understand the spatial action space, and ii) How to fully exploit the reasoning capacity of LMMs in solving these tasks. To tackle the former challenge, we propose a novel task formulation, which inputs the current states of object parts and the gripper, and reformulates rotation by a new axis representation instead of traditional Euler angles. This representation is more compatible with spatial reasoning and easier to interpret within a unified language space. For the latter challenge, we design a pipeline to utilize cutting-edge LMMs to generate a small but high-quality reasoning dataset of multi-round dialogues that successfully solve manipulation tasks for supervised fine-tuning. Then, we perform reinforcement learning by trial-and-error interactions in simulation to further enhance the model's reasoning abilities for robotic manipulation. Our resulting reasoning model built upon a 7B backbone, named ReasonManip, demonstrates three notable advantages driven by its system-2 level reasoning capabilities: i) exceptional generalizability to out-of-distribution environments, objects, and tasks; ii) inherent sim-to-real transfer ability enabled by the unified language representation shared across domains; iii) transparent interpretability connecting high-level reasoning and low-level control. Extensive experiments demonstrate the effectiveness of the proposed paradigm and its potential to advance LMM-driven robotic manipulation.
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
Oct 09, 2024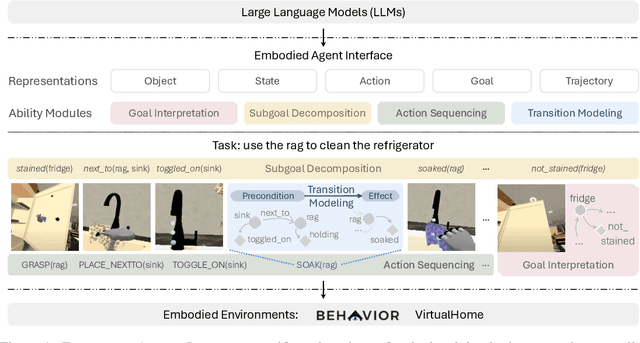

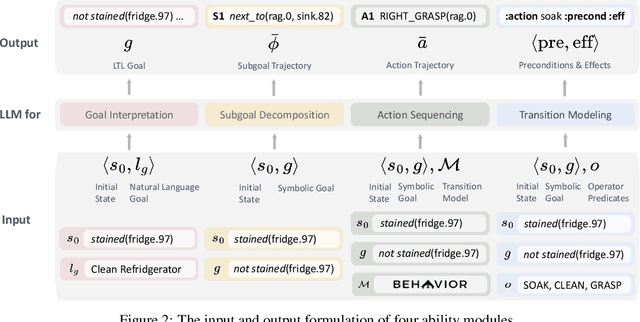
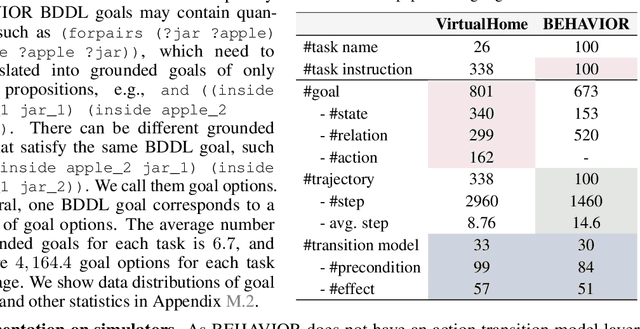
We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics which break down evaluation into various types of errors, such as hallucination errors, affordance errors, various types of planning errors, etc. Overall, our benchmark offers a comprehensive assessment of LLMs' performance for different subtasks, pinpointing the strengths and weaknesses in LLM-powered embodied AI systems, and providing insights for effective and selective use of LLMs in embodied decision making.
SOK-Bench: A Situated Video Reasoning Benchmark with Aligned Open-World Knowledge
May 17, 2024



Learning commonsense reasoning from visual contexts and scenes in real-world is a crucial step toward advanced artificial intelligence. However, existing video reasoning benchmarks are still inadequate since they were mainly designed for factual or situated reasoning and rarely involve broader knowledge in the real world. Our work aims to delve deeper into reasoning evaluations, specifically within dynamic, open-world, and structured context knowledge. We propose a new benchmark (SOK-Bench), consisting of 44K questions and 10K situations with instance-level annotations depicted in the videos. The reasoning process is required to understand and apply situated knowledge and general knowledge for problem-solving. To create such a dataset, we propose an automatic and scalable generation method to generate question-answer pairs, knowledge graphs, and rationales by instructing the combinations of LLMs and MLLMs. Concretely, we first extract observable situated entities, relations, and processes from videos for situated knowledge and then extend to open-world knowledge beyond the visible content. The task generation is facilitated through multiple dialogues as iterations and subsequently corrected and refined by our designed self-promptings and demonstrations. With a corpus of both explicit situated facts and implicit commonsense, we generate associated question-answer pairs and reasoning processes, finally followed by manual reviews for quality assurance. We evaluated recent mainstream large vision-language models on the benchmark and found several insightful conclusions. For more information, please refer to our benchmark at www.bobbywu.com/SOKBench.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024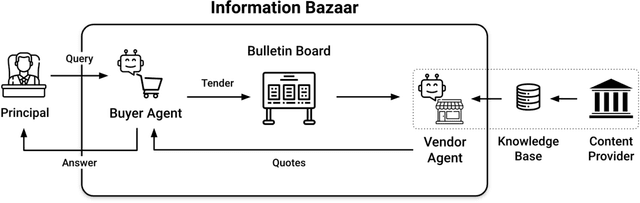

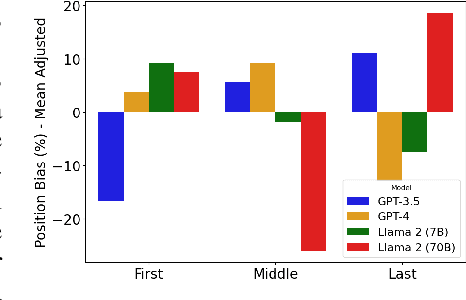
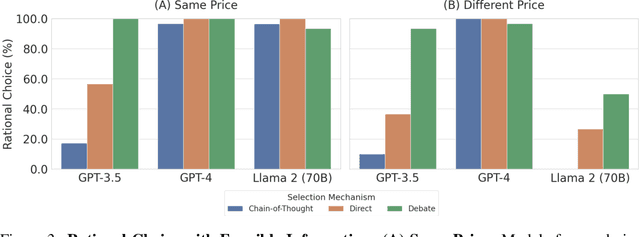
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
Compositional 3D Scene Synthesis with Scene Graph Guided Layout-Shape Generation
Mar 19, 2024



Compositional 3D scene synthesis has diverse applications across a spectrum of industries such as robotics, films, and video games, as it closely mirrors the complexity of real-world multi-object environments. Early works typically employ shape retrieval based frameworks which naturally suffer from limited shape diversity. Recent progresses have been made in shape generation with powerful generative models, such as diffusion models, which increases the shape fidelity. However, these approaches separately treat 3D shape generation and layout generation. The synthesized scenes are usually hampered by layout collision, which implies that the scene-level fidelity is still under-explored. In this paper, we aim at generating realistic and reasonable 3D scenes from scene graph. To enrich the representation capability of the given scene graph inputs, large language model is utilized to explicitly aggregate the global graph features with local relationship features. With a unified graph convolution network (GCN), graph features are extracted from scene graphs updated via joint layout-shape distribution. During scene generation, an IoU-based regularization loss is introduced to constrain the predicted 3D layouts. Benchmarked on the SG-FRONT dataset, our method achieves better 3D scene synthesis, especially in terms of scene-level fidelity. The source code will be released after publication.
Learning 3D object-centric representation through prediction
Mar 06, 2024

As part of human core knowledge, the representation of objects is the building block of mental representation that supports high-level concepts and symbolic reasoning. While humans develop the ability of perceiving objects situated in 3D environments without supervision, models that learn the same set of abilities with similar constraints faced by human infants are lacking. Towards this end, we developed a novel network architecture that simultaneously learns to 1) segment objects from discrete images, 2) infer their 3D locations, and 3) perceive depth, all while using only information directly available to the brain as training data, namely: sequences of images and self-motion. The core idea is treating objects as latent causes of visual input which the brain uses to make efficient predictions of future scenes. This results in object representations being learned as an essential byproduct of learning to predict.
ViGoR: Improving Visual Grounding of Large Vision Language Models with Fine-Grained Reward Modeling
Feb 09, 2024



By combining natural language understanding and the generation capabilities and breadth of knowledge of large language models with image perception, recent large vision language models (LVLMs) have shown unprecedented reasoning capabilities in the real world. However, the generated text often suffers from inaccurate grounding in the visual input, resulting in errors such as hallucinating nonexistent scene elements, missing significant parts of the scene, and inferring incorrect attributes and relationships between objects. To address these issues, we introduce a novel framework, ViGoR (Visual Grounding Through Fine-Grained Reward Modeling) that utilizes fine-grained reward modeling to significantly enhance the visual grounding of LVLMs over pre-trained baselines. This improvement is efficiently achieved using much cheaper human evaluations instead of full supervisions, as well as automated methods. We show the effectiveness of our approach through numerous metrics on several benchmarks. Additionally, we construct a comprehensive and challenging dataset specifically designed to validate the visual grounding capabilities of LVLMs. Finally, we plan to release our human annotation comprising approximately 16,000 images and generated text pairs with fine-grained evaluations to contribute to related research in the community.
AffordanceLLM: Grounding Affordance from Vision Language Models
Jan 12, 2024



Affordance grounding refers to the task of finding the area of an object with which one can interact. It is a fundamental but challenging task, as a successful solution requires the comprehensive understanding of a scene in multiple aspects including detection, localization, and recognition of objects with their parts, of geo-spatial configuration/layout of the scene, of 3D shapes and physics, as well as of the functionality and potential interaction of the objects and humans. Much of the knowledge is hidden and beyond the image content with the supervised labels from a limited training set. In this paper, we make an attempt to improve the generalization capability of the current affordance grounding by taking the advantage of the rich world, abstract, and human-object-interaction knowledge from pretrained large-scale vision language models. Under the AGD20K benchmark, our proposed model demonstrates a significant performance gain over the competing methods for in-the-wild object affordance grounding. We further demonstrate it can ground affordance for objects from random Internet images, even if both objects and actions are unseen during training. Project site: https://jasonqsy.github.io/AffordanceLLM/
The Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Oct 04, 2023
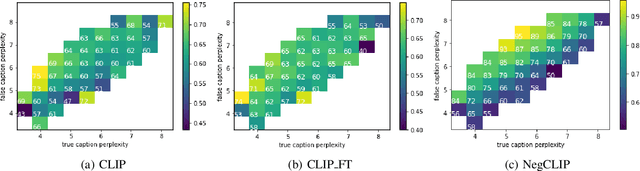


Compositionality is a common property in many modalities including natural languages and images, but the compositional generalization of multi-modal models is not well-understood. In this paper, we identify two sources of visual-linguistic compositionality: linguistic priors and the interplay between images and texts. We show that current attempts to improve compositional generalization rely on linguistic priors rather than on information in the image. We also propose a new metric for compositionality without such linguistic priors.
DAT++: Spatially Dynamic Vision Transformer with Deformable Attention
Sep 04, 2023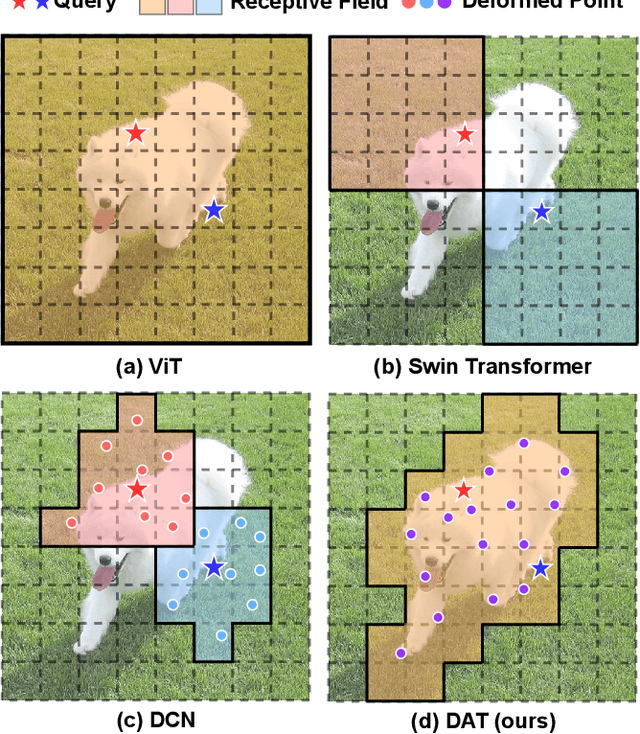
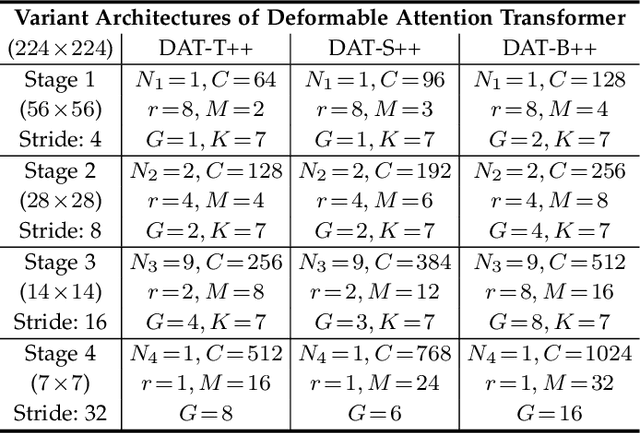
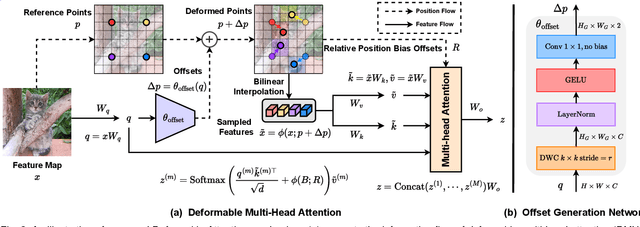
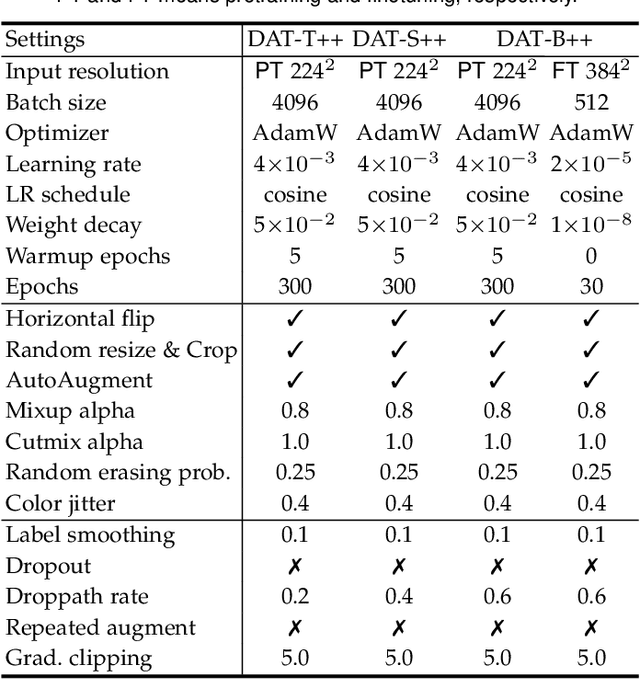
Transformers have shown superior performance on various vision tasks. Their large receptive field endows Transformer models with higher representation power than their CNN counterparts. Nevertheless, simply enlarging the receptive field also raises several concerns. On the one hand, using dense attention in ViT leads to excessive memory and computational cost, and features can be influenced by irrelevant parts that are beyond the region of interests. On the other hand, the handcrafted attention adopted in PVT or Swin Transformer is data agnostic and may limit the ability to model long-range relations. To solve this dilemma, we propose a novel deformable multi-head attention module, where the positions of key and value pairs in self-attention are adaptively allocated in a data-dependent way. This flexible scheme enables the proposed deformable attention to dynamically focus on relevant regions while maintains the representation power of global attention. On this basis, we present Deformable Attention Transformer (DAT), a general vision backbone efficient and effective for visual recognition. We further build an enhanced version DAT++. Extensive experiments show that our DAT++ achieves state-of-the-art results on various visual recognition benchmarks, with 85.9% ImageNet accuracy, 54.5 and 47.0 MS-COCO instance segmentation mAP, and 51.5 ADE20K semantic segmentation mIoU.