 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Self-contrastive Learning Framework for Test-time Ultrasound Image Denoising
May 12, 2026The inherent electronic and speckle noise complicates clinical interpretation of ultrasound images. Conventional denoising methods rely on explicit noise assumptions whose validity diminishes under composite noise conditions. Learning-based methods require massive labeled data and model parameters. These pre-defined and pre-trained manners entail an inevitable domain shift in complex in vivo environments, so they are limited to a specific noise type and often blur structural details. In this study, we propose a pure test-time training framework for one-shot ultrasound image denoising and apply it to synthetic aperture ultrasound (SAU), which synthesizes transmit focus from sub-aperture transmissions. Our Aperture-to-Aperture (A2A) framework disentangles anatomical similarity and noise randomness from shuffled sub-apertures through self-contrastive learning in pyramid latent spaces. The clean image is then decoded from the anatomy space, while discarding the noise space. A2A is trained at test time on one noisy sample of SAU signals, so it fundamentally eliminates the domain shift and pretraining costs. Simulation experiments, including electronic noise levels of 0 to 30 dB and different inclusion geometries, demonstrated an improvement of 69.3% SNR and 34.4% CNR by A2A. The in vivo results showed 84.8% SNR and 25.7% CNR gains using only two aperture data of the heart in six echocardiographic views, liver, and kidney. A2A delivers clear images/signals across diverse imaging targets and configurations, paving the way for more reliable anatomical visualization and functional assessment by ultrasound.
Synthetic Aperture for High Spatial Resolution Acoustoelectric Imaging
Dec 16, 2025
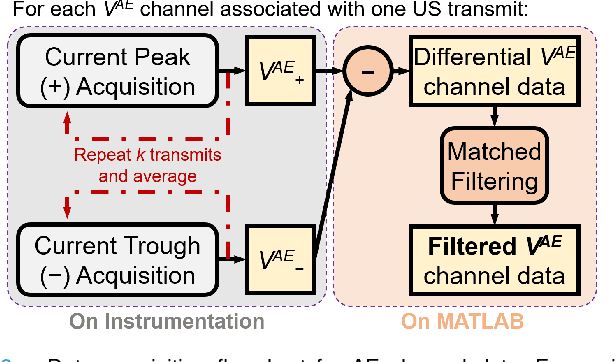


Acoustoelectric (AE) imaging provides electro-anatomical contrast by mapping the distribution of electric fields in biological tissues, by delivering ultrasound waves which spatially modulate the medium resistivity via the AE effect. The conventional method in AE imaging is to transmit focused ultrasound (FUS) beams; however, the depth-of-field (DOF) of FUS-AE is limited to the size of the focal spot, which does not span across the centimeter-scale of organs. Instead of fixing the focal depth on transmission, we propose to dynamically synthesize the AE modulation regions via a Synthetic Aperture approach (SA-AE). SA-AE involves a straightforward pixel-based delay-and-sum reconstruction of AE images from unfocused AE signals. In saline and ex vivo lobster nerve experiments, FUS-AE was shown to perform well only at the focal depth, with poor spatial resolution for out-of-focus electric sources. Meanwhile, SA-AE generally improved spatial resolution throughout the DOF, but introduced strong background noise. The flexibility of uncoupled, single-element induced AE signals in SA-AE was further leveraged to quantify their spatial coherence across the transmit aperture, obtaining maps of the coherence factor (CF) and pulse-length coherence factor (CFPL). Weighting SA-AE images with their derived CF and CFPL maps resulted in further improvement in image resolution and contrast, and notably, boosted the image SNR beyond that of FUS-AE. CFPL exhibited stronger noise suppression over CF. Using unfocused wave transmissions, the proposed coherence-weighted SA-AE strategy offers a high resolution yet noise-robust solution towards the practical imaging of fast biological currents.
Volumetric Ultrasound via 3D Null Subtraction Imaging with Circular and Spiral Apertures
Nov 15, 2025Volumetric ultrasound imaging faces a fundamental trade-off among image quality, frame rate, and hardware complexity. This study introduces three-dimensional Null Subtraction Imaging (3D NSI), a nonlinear beamforming framework that addresses this trade-off by combining computationally efficient null-subtraction process with multiplexing-aware sparse aperture designs on matrix arrays. We evaluate three apodization configurations: a fully addressed circular aperture and two Fermat's spiral sparse apertures. To overcome channel-sharing constraints common in matrix arrays multiplexed with low-channel-count ultrasound systems, we propose a spiral "no-reuse" apodization that enforces non-overlapping element sets across transmit-receive events. This design resolves multiplexing conflicts and enables up to a 16-fold increase in acquisition volume rate using only 240 active elements on a 1024-element probe. In computer simulations and tissue-mimicking phantom experiments, 3D NSI achieved an average improvement of 36% in azimuthal and elevational resolutions, along with an approximately 20% higher contrast ratio, compared to the conventional Delay-and-Sum (DAS) beamformer under matched transmit/receive configurations. When implemented with the spiral no-reuse aperture, the 3D NSI framework achieved over 1000 volumes per second with a computational load less than three times that of DAS, making it a practical solution for real-time 4D imaging.
SOK-Bench: A Situated Video Reasoning Benchmark with Aligned Open-World Knowledge
May 17, 2024



Learning commonsense reasoning from visual contexts and scenes in real-world is a crucial step toward advanced artificial intelligence. However, existing video reasoning benchmarks are still inadequate since they were mainly designed for factual or situated reasoning and rarely involve broader knowledge in the real world. Our work aims to delve deeper into reasoning evaluations, specifically within dynamic, open-world, and structured context knowledge. We propose a new benchmark (SOK-Bench), consisting of 44K questions and 10K situations with instance-level annotations depicted in the videos. The reasoning process is required to understand and apply situated knowledge and general knowledge for problem-solving. To create such a dataset, we propose an automatic and scalable generation method to generate question-answer pairs, knowledge graphs, and rationales by instructing the combinations of LLMs and MLLMs. Concretely, we first extract observable situated entities, relations, and processes from videos for situated knowledge and then extend to open-world knowledge beyond the visible content. The task generation is facilitated through multiple dialogues as iterations and subsequently corrected and refined by our designed self-promptings and demonstrations. With a corpus of both explicit situated facts and implicit commonsense, we generate associated question-answer pairs and reasoning processes, finally followed by manual reviews for quality assurance. We evaluated recent mainstream large vision-language models on the benchmark and found several insightful conclusions. For more information, please refer to our benchmark at www.bobbywu.com/SOKBench.
Towards Real-time Training of Physics-informed Neural Networks: Applications in Ultrafast Ultrasound Blood Flow Imaging
Sep 09, 2023

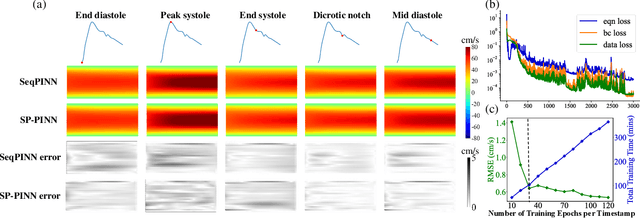

Physics-informed Neural Network (PINN) is one of the most preeminent solvers of Navier-Stokes equations, which are widely used as the governing equation of blood flow. However, current approaches, relying on full Navier-Stokes equations, are impractical for ultrafast Doppler ultrasound, the state-of-the-art technique for depiction of complex blood flow dynamics \emph{in vivo} through acquired thousands of frames (or, timestamps) per second. In this article, we first propose a novel training framework of PINN for solving Navier-Stokes equations by discretizing Navier-Stokes equations into steady state and sequentially solving steady-state Navier-Stokes equations with transfer learning. The novel training framework is coined as SeqPINN. Upon the success of SeqPINN, we adopt the idea of averaged constant stochastic gradient descent (SGD) as initialization and propose a parallel training scheme for all timestamps. To ensure an initialization that generalizes well, we borrow the concept of Stochastic Weight Averaging Gaussian to perform uncertainty estimation as an indicator of generalizability of the initialization. This algorithm, named SP-PINN, further expedites training of PINN while achieving comparable accuracy with SeqPINN. Finite-element simulations and \emph{in vitro} phantoms of single-branch and trifurcate blood vessels are used to evaluate the performance of SeqPINN and SP-PINN. Results show that both SeqPINN and SP-PINN are manyfold faster than the original design of PINN, while respectively achieving Root Mean Square Errors (RMSEs) of 1.01 cm/s and 1.26 cm/s on the straight vessel and 1.91 cm/s and 2.56 cm/s on the trifurcate blood vessel when recovering blood flow velocities.
Constrained CycleGAN for Effective Generation of Ultrasound Sector Images of Improved Spatial Resolution
Sep 02, 2023Objective. A phased or a curvilinear array produces ultrasound (US) images with a sector field of view (FOV), which inherently exhibits spatially-varying image resolution with inferior quality in the far zone and towards the two sides azimuthally. Sector US images with improved spatial resolutions are favorable for accurate quantitative analysis of large and dynamic organs, such as the heart. Therefore, this study aims to translate US images with spatially-varying resolution to ones with less spatially-varying resolution. CycleGAN has been a prominent choice for unpaired medical image translation; however, it neither guarantees structural consistency nor preserves backscattering patterns between input and generated images for unpaired US images. Approach. To circumvent this limitation, we propose a constrained CycleGAN (CCycleGAN), which directly performs US image generation with unpaired images acquired by different ultrasound array probes. In addition to conventional adversarial and cycle-consistency losses of CycleGAN, CCycleGAN introduces an identical loss and a correlation coefficient loss based on intrinsic US backscattered signal properties to constrain structural consistency and backscattering patterns, respectively. Instead of post-processed B-mode images, CCycleGAN uses envelope data directly obtained from beamformed radio-frequency signals without any other non-linear postprocessing. Main Results. In vitro phantom results demonstrate that CCycleGAN successfully generates images with improved spatial resolution as well as higher peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) compared with benchmarks. Significance. CCycleGAN-generated US images of the in vivo human beating heart further facilitate higher quality heart wall motion estimation than benchmarks-generated ones, particularly in deep regions.
Exploring Concept Contribution Spatially: Hidden Layer Interpretation with Spatial Activation Concept Vector
May 21, 2022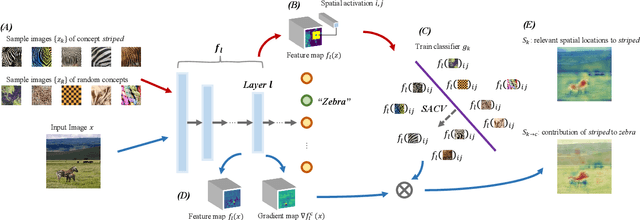

To interpret deep learning models, one mainstream is to explore the learned concepts by networks. Testing with Concept Activation Vector (TCAV) presents a powerful tool to quantify the contribution of query concepts (represented by user-defined guidance images) to a target class. For example, we can quantitatively evaluate whether and to what extent concept striped contributes to model prediction zebra with TCAV. Therefore, TCAV whitens the reasoning process of deep networks. And it has been applied to solve practical problems such as diagnosis. However, for some images where the target object only occupies a small fraction of the region, TCAV evaluation may be interfered with by redundant background features because TCAV calculates concept contribution to a target class based on a whole hidden layer. To tackle this problem, based on TCAV, we propose Spatial Activation Concept Vector (SACV) which identifies the relevant spatial locations to the query concept while evaluating their contributions to the model prediction of the target class. Experiment shows that SACV generates a more fine-grained explanation map for a hidden layer and quantifies concepts' contributions spatially. Moreover, it avoids interference from background features. The code is available on https://github.com/AntonotnaWang/Spatial-Activation-Concept-Vector.
HINT: Hierarchical Neuron Concept Explainer
Mar 27, 2022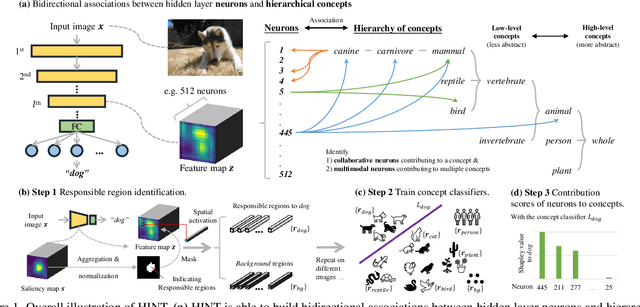
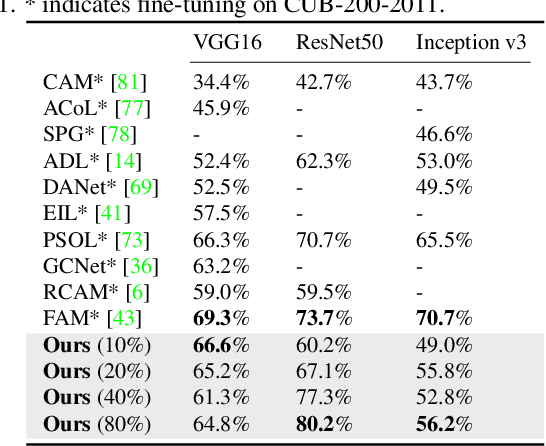

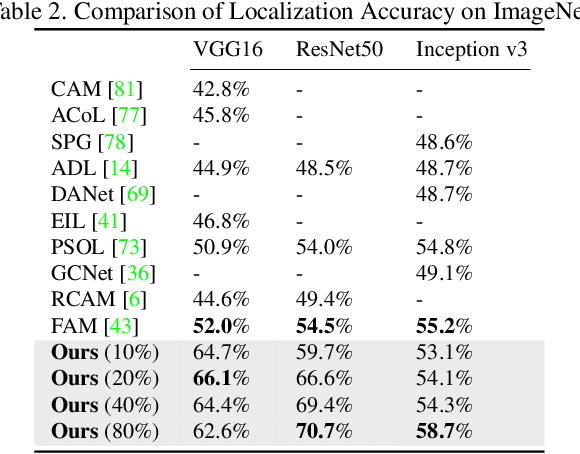
To interpret deep networks, one main approach is to associate neurons with human-understandable concepts. However, existing methods often ignore the inherent relationships of different concepts (e.g., dog and cat both belong to animals), and thus lose the chance to explain neurons responsible for higher-level concepts (e.g., animal). In this paper, we study hierarchical concepts inspired by the hierarchical cognition process of human beings. To this end, we propose HIerarchical Neuron concepT explainer (HINT) to effectively build bidirectional associations between neurons and hierarchical concepts in a low-cost and scalable manner. HINT enables us to systematically and quantitatively study whether and how the implicit hierarchical relationships of concepts are embedded into neurons, such as identifying collaborative neurons responsible to one concept and multimodal neurons for different concepts, at different semantic levels from concrete concepts (e.g., dog) to more abstract ones (e.g., animal). Finally, we verify the faithfulness of the associations using Weakly Supervised Object Localization, and demonstrate its applicability in various tasks such as discovering saliency regions and explaining adversarial attacks. Code is available on https://github.com/AntonotnaWang/HINT.
NaviAirway: a bronchiole-sensitive deep learning-based airway segmentation pipeline for planning of navigation bronchoscopy
Mar 08, 2022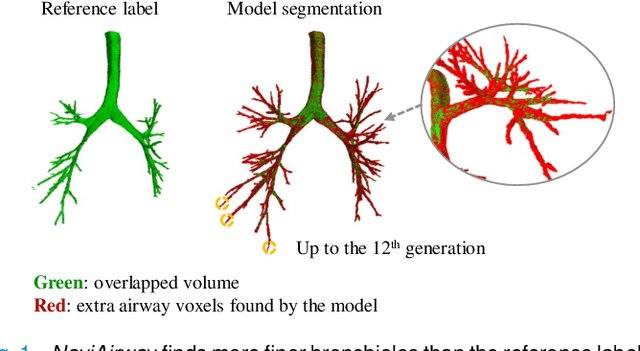

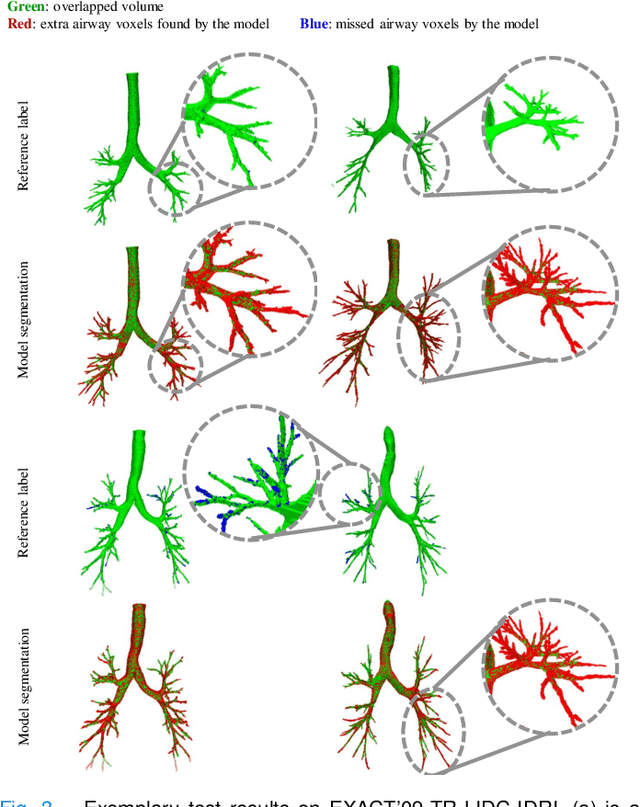
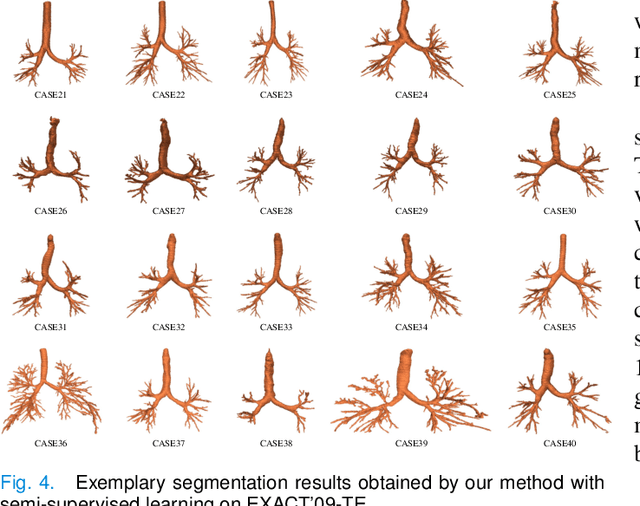
Navigation bronchoscopy is a minimally invasive procedure in which doctors pass a bronchoscope into a subject's airways to sample the target pulmonary lesion. A three-dimensional (3D) airway roadmap reconstructed from Computer Tomography (CT) scans is a prerequisite for this procedure, especially when the target is distally located. Therefore, an accurate and efficient airway segmentation algorithm is essential to reduce bronchoscopists' burden of pre-procedural airway identification as well as patients' discomfort during the prolonged procedure. However, airway segmentation remains a challenging task because of the intrinsic complex tree-like structure, imbalanced sizes of airway branches, potential domain shifts of CT scans, and few available labeled images. To address these problems, we present a deep learning-based pipeline, denoted as NaviAirway, which finds finer bronchioles through four major novel components - feature extractor modules in model architecture design, a bronchiole-sensitive loss function, a human-vision-inspired iterative training strategy, and a semi-supervised learning framework to utilize unlabeled CT images. Experimental results showed that NaviAirway outperformed existing methods, particularly in identification of higher generation bronchioles and robustness to new CT scans. On average, NaviAirway takes five minutes to segment the CT scans of one patient on a GPU-embedded computer. Moreover, we propose two new metrics to complement conventional ones for a more comprehensive and fairer evaluation of deep learning-based airway segmentation approaches. The code is publicly available on https://github.com/AntonotnaWang/NaviAirway.