 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrandCode: Achieving Grandmaster Level in Competitive Programming via Agentic Reinforcement Learning
Apr 03, 2026Competitive programming remains one of the last few human strongholds in coding against AI. The best AI system to date still underperforms the best humans competitive programming: the most recent best result, Google's Gemini~3 Deep Think, attained 8th place even not being evaluated under live competition conditions. In this work, we introduce GrandCode, a multi-agent RL system designed for competitive programming. The capability of GrandCode is attributed to two key factors: (1) It orchestrates a variety of agentic modules (hypothesis proposal, solver, test generator, summarization, etc) and jointly improves them through post-training and online test-time RL; (2) We introduce Agentic GRPO specifically designed for multi-stage agent rollouts with delayed rewards and the severe off-policy drift that is prevalent in agentic RL. GrandCode is the first AI system that consistently beats all human participants in live contests of competitive programming: in the most recent three Codeforces live competitions, i.e., Round~1087 (Mar 21, 2026), Round~1088 (Mar 28, 2026), and Round~1089 (Mar 29, 2026), GrandCode placed first in all of them, beating all human participants, including legendary grandmasters. GrandCode shows that AI systems have reached a point where they surpass the strongest human programmers on the most competitive coding tasks.
Self-Rewarded Multimodal Coherent Reasoning Across Diverse Visual Domains
Dec 27, 2025Multimodal LLMs often produce fluent yet unreliable reasoning, exhibiting weak step-to-step coherence and insufficient visual grounding, largely because existing alignment approaches supervise only the final answer while ignoring the reliability of the intermediate reasoning process. We introduce SR-MCR, a lightweight and label-free framework that aligns reasoning by exploiting intrinsic process signals derived directly from model outputs. Five self-referential cues -- semantic alignment, lexical fidelity, non-redundancy, visual grounding, and step consistency -- are integrated into a normalized, reliability-weighted reward that provides fine-grained process-level guidance. A critic-free GRPO objective, enhanced with a confidence-aware cooling mechanism, further stabilizes training and suppresses trivial or overly confident generations. Built on Qwen2.5-VL, SR-MCR improves both answer accuracy and reasoning coherence across a broad set of visual benchmarks; among open-source models of comparable size, SR-MCR-7B achieves state-of-the-art performance with an average accuracy of 81.4%. Ablation studies confirm the independent contributions of each reward term and the cooling module.
MM-CoT:A Benchmark for Probing Visual Chain-of-Thought Reasoning in Multimodal Models
Dec 09, 2025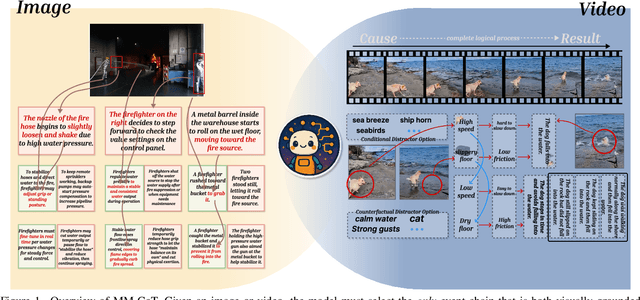
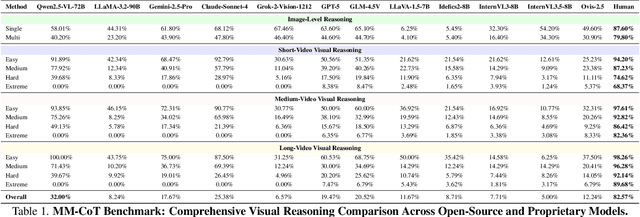
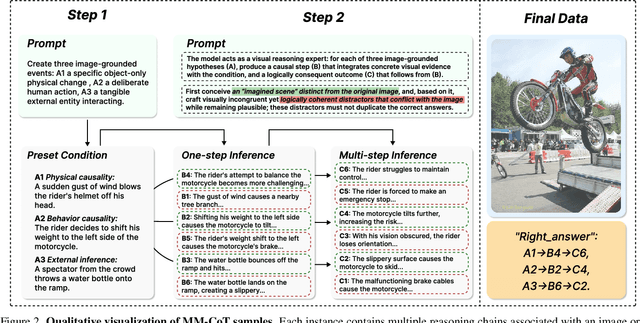
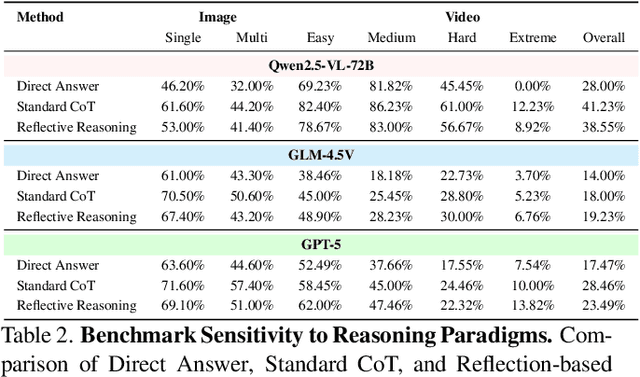
The ability to perform Chain-of-Thought (CoT) reasoning marks a major milestone for multimodal models (MMs), enabling them to solve complex visual reasoning problems. Yet a critical question remains: is such reasoning genuinely grounded in visual evidence and logically coherent? Existing benchmarks emphasize generation but neglect verification, i.e., the capacity to assess whether a reasoning chain is both visually consistent and logically valid. To fill this gap, we introduce MM-CoT, a diagnostic benchmark specifically designed to probe the visual grounding and logical coherence of CoT reasoning in MMs. Instead of generating free-form explanations, models must select the sole event chain that satisfies two orthogonal constraints: (i) visual consistency, ensuring all steps are anchored in observable evidence, and (ii) logical coherence, ensuring causal and commonsense validity. Adversarial distractors are engineered to violate one of these constraints, exposing distinct reasoning failures. We evaluate leading vision-language models on MM-CoT and find that even the most advanced systems struggle, revealing a sharp discrepancy between generative fluency and true reasoning fidelity. MM-CoT shows low correlation with existing benchmarks, confirming that it measures a unique combination of visual grounding and logical reasoning. This benchmark provides a foundation for developing future models that reason not just plausibly, but faithfully and coherently within the visual world.
OSC: Cognitive Orchestration through Dynamic Knowledge Alignment in Multi-Agent LLM Collaboration
Sep 05, 2025This paper introduces OSC (Orchestrating Cognitive Synergy), a knowledge-aware adaptive collaboration framework designed to enhance cognitive synergy in multi-agent systems with large language models. While prior work has advanced agent selection and result aggregation, efficient linguistic interactions for deep collaboration among expert agents remain a critical bottleneck. OSC addresses this gap as a pivotal intermediate layer between selection and aggregation, introducing Collaborator Knowledge Models (CKM) to enable each agent to dynamically perceive its collaborators' cognitive states. Through real-time cognitive gap analysis, agents adaptively adjust communication behaviors, including content focus, detail level, and expression style, using learned strategies. Experiments on complex reasoning and problem-solving benchmarks demonstrate that OSC significantly improves task performance and communication efficiency, transforming "parallel-working individuals'' into a "deeply collaborative cognitive team.'' This framework not only optimizes multi-agent collaboration but also offers new insights into LLM agent interaction behaviors.
CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning
Jul 18, 2025The exponential growth in demand for GPU computing resources, driven by the rapid advancement of Large Language Models, has created an urgent need for automated CUDA optimization strategies. While recent advances in LLMs show promise for code generation, current SOTA models (e.g. R1, o1) achieve low success rates in improving CUDA speed. In this paper, we introduce CUDA-L1, an automated reinforcement learning framework for CUDA optimization. CUDA-L1 achieves performance improvements on the CUDA optimization task: trained on NVIDIA A100, it delivers an average speedup of x17.7 across all 250 CUDA kernels of KernelBench, with peak speedups reaching x449. Furthermore, the model also demonstrates excellent portability across GPU architectures, achieving average speedups of x17.8 on H100, x19.0 on RTX 3090, x16.5 on L40, x14.7 on H800, and x13.9 on H20 despite being optimized specifically for A100. Beyond these benchmark results, CUDA-L1 demonstrates several remarkable properties: 1) Discovers a variety of CUDA optimization techniques and learns to combine them strategically to achieve optimal performance; 2) Uncovers fundamental principles of CUDA optimization; 3) Identifies non-obvious performance bottlenecks and rejects seemingly beneficial optimizations that harm performance. The capabilities of CUDA-L1 demonstrate that reinforcement learning can transform an initially poor-performing LLM into an effective CUDA optimizer through speedup-based reward signals alone, without human expertise or domain knowledge. More importantly, the trained RL model extend the acquired reasoning abilities to new kernels. This paradigm opens possibilities for automated optimization of CUDA operations, and holds promise to substantially promote GPU efficiency and alleviate the rising pressure on GPU computing resources.
FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset
Mar 11, 2025Due to the data-driven nature of current face identity (FaceID) customization methods, all state-of-the-art models rely on large-scale datasets containing millions of high-quality text-image pairs for training. However, none of these datasets are publicly available, which restricts transparency and hinders further advancements in the field. To address this issue, in this paper, we collect and release FaceID-6M, the first large-scale, open-source FaceID dataset containing 6 million high-quality text-image pairs. Filtered from LAION-5B \cite{schuhmann2022laion}, FaceID-6M undergoes a rigorous image and text filtering steps to ensure dataset quality, including resolution filtering to maintain high-quality images and faces, face filtering to remove images that lack human faces, and keyword-based strategy to retain descriptions containing human-related terms (e.g., nationality, professions and names). Through these cleaning processes, FaceID-6M provides a high-quality dataset optimized for training powerful FaceID customization models, facilitating advancements in the field by offering an open resource for research and development. We conduct extensive experiments to show the effectiveness of our FaceID-6M, demonstrating that models trained on our FaceID-6M dataset achieve performance that is comparable to, and slightly better than currently available industrial models. Additionally, to support and advance research in the FaceID customization community, we make our code, datasets, and models fully publicly available. Our codes, models, and datasets are available at: https://github.com/ShuheSH/FaceID-6M.
Turn That Frown Upside Down: FaceID Customization via Cross-Training Data
Jan 26, 2025



Existing face identity (FaceID) customization methods perform well but are limited to generating identical faces as the input, while in real-world applications, users often desire images of the same person but with variations, such as different expressions (e.g., smiling, angry) or angles (e.g., side profile). This limitation arises from the lack of datasets with controlled input-output facial variations, restricting models' ability to learn effective modifications. To address this issue, we propose CrossFaceID, the first large-scale, high-quality, and publicly available dataset specifically designed to improve the facial modification capabilities of FaceID customization models. Specifically, CrossFaceID consists of 40,000 text-image pairs from approximately 2,000 persons, with each person represented by around 20 images showcasing diverse facial attributes such as poses, expressions, angles, and adornments. During the training stage, a specific face of a person is used as input, and the FaceID customization model is forced to generate another image of the same person but with altered facial features. This allows the FaceID customization model to acquire the ability to personalize and modify known facial features during the inference stage. Experiments show that models fine-tuned on the CrossFaceID dataset retain its performance in preserving FaceID fidelity while significantly improving its face customization capabilities. To facilitate further advancements in the FaceID customization field, our code, constructed datasets, and trained models are fully available to the public.
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Feb 06, 2024We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
Sentiment Analysis through LLM Negotiations
Nov 03, 2023



A standard paradigm for sentiment analysis is to rely on a singular LLM and makes the decision in a single round under the framework of in-context learning. This framework suffers the key disadvantage that the single-turn output generated by a single LLM might not deliver the perfect decision, just as humans sometimes need multiple attempts to get things right. This is especially true for the task of sentiment analysis where deep reasoning is required to address the complex linguistic phenomenon (e.g., clause composition, irony, etc) in the input. To address this issue, this paper introduces a multi-LLM negotiation framework for sentiment analysis. The framework consists of a reasoning-infused generator to provide decision along with rationale, a explanation-deriving discriminator to evaluate the credibility of the generator. The generator and the discriminator iterate until a consensus is reached. The proposed framework naturally addressed the aforementioned challenge, as we are able to take the complementary abilities of two LLMs, have them use rationale to persuade each other for correction. Experiments on a wide range of sentiment analysis benchmarks (SST-2, Movie Review, Twitter, yelp, amazon, IMDB) demonstrate the effectiveness of proposed approach: it consistently yields better performances than the ICL baseline across all benchmarks, and even superior performances to supervised baselines on the Twitter and movie review datasets.
Constrained CycleGAN for Effective Generation of Ultrasound Sector Images of Improved Spatial Resolution
Sep 02, 2023Objective. A phased or a curvilinear array produces ultrasound (US) images with a sector field of view (FOV), which inherently exhibits spatially-varying image resolution with inferior quality in the far zone and towards the two sides azimuthally. Sector US images with improved spatial resolutions are favorable for accurate quantitative analysis of large and dynamic organs, such as the heart. Therefore, this study aims to translate US images with spatially-varying resolution to ones with less spatially-varying resolution. CycleGAN has been a prominent choice for unpaired medical image translation; however, it neither guarantees structural consistency nor preserves backscattering patterns between input and generated images for unpaired US images. Approach. To circumvent this limitation, we propose a constrained CycleGAN (CCycleGAN), which directly performs US image generation with unpaired images acquired by different ultrasound array probes. In addition to conventional adversarial and cycle-consistency losses of CycleGAN, CCycleGAN introduces an identical loss and a correlation coefficient loss based on intrinsic US backscattered signal properties to constrain structural consistency and backscattering patterns, respectively. Instead of post-processed B-mode images, CCycleGAN uses envelope data directly obtained from beamformed radio-frequency signals without any other non-linear postprocessing. Main Results. In vitro phantom results demonstrate that CCycleGAN successfully generates images with improved spatial resolution as well as higher peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) compared with benchmarks. Significance. CCycleGAN-generated US images of the in vivo human beating heart further facilitate higher quality heart wall motion estimation than benchmarks-generated ones, particularly in deep regions.