 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
World Models for Policy Refinement in StarCraft II
Feb 16, 2026Large Language Models (LLMs) have recently shown strong reasoning and generalization capabilities, motivating their use as decision-making policies in complex environments. StarCraft II (SC2), with its massive state-action space and partial observability, is a challenging testbed. However, existing LLM-based SC2 agents primarily focus on improving the policy itself and overlook integrating a learnable, action-conditioned transition model into the decision loop. To bridge this gap, we propose StarWM, the first world model for SC2 that predicts future observations under partial observability. To facilitate learning SC2's hybrid dynamics, we introduce a structured textual representation that factorizes observations into five semantic modules, and construct SC2-Dynamics-50k, the first instruction-tuning dataset for SC2 dynamics prediction. We further develop a multi-dimensional offline evaluation framework for predicted structured observations. Offline results show StarWM's substantial gains over zero-shot baselines, including nearly 60% improvements in resource prediction accuracy and self-side macro-situation consistency. Finally, we propose StarWM-Agent, a world-model-augmented decision system that integrates StarWM into a Generate--Simulate--Refine decision loop for foresight-driven policy refinement. Online evaluation against SC2's built-in AI demonstrates consistent improvements, yielding win-rate gains of 30%, 15%, and 30% against Hard (LV5), Harder (LV6), and VeryHard (LV7), respectively, alongside improved macro-management stability and tactical risk assessment.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
MrCoM: A Meta-Regularized World-Model Generalizing Across Multi-Scenarios
Nov 09, 2025Model-based reinforcement learning (MBRL) is a crucial approach to enhance the generalization capabilities and improve the sample efficiency of RL algorithms. However, current MBRL methods focus primarily on building world models for single tasks and rarely address generalization across different scenarios. Building on the insight that dynamics within the same simulation engine share inherent properties, we attempt to construct a unified world model capable of generalizing across different scenarios, named Meta-Regularized Contextual World-Model (MrCoM). This method first decomposes the latent state space into various components based on the dynamic characteristics, thereby enhancing the accuracy of world-model prediction. Further, MrCoM adopts meta-state regularization to extract unified representation of scenario-relevant information, and meta-value regularization to align world-model optimization with policy learning across diverse scenario objectives. We theoretically analyze the generalization error upper bound of MrCoM in multi-scenario settings. We systematically evaluate our algorithm's generalization ability across diverse scenarios, demonstrating significantly better performance than previous state-of-the-art methods.
SC2Arena and StarEvolve: Benchmark and Self-Improvement Framework for LLMs in Complex Decision-Making Tasks
Aug 14, 2025Evaluating large language models (LLMs) in complex decision-making is essential for advancing AI's ability for strategic planning and real-time adaptation. However, existing benchmarks for tasks like StarCraft II fail to capture the game's full complexity, such as its complete game context, diverse action spaces, and all playable races. To address this gap, we present SC2Arena, a benchmark that fully supports all playable races, low-level action spaces, and optimizes text-based observations to tackle spatial reasoning challenges. Complementing this, we introduce StarEvolve, a hierarchical framework that integrates strategic planning with tactical execution, featuring iterative self-correction and continuous improvement via fine-tuning on high-quality gameplay data. Its key components include a Planner-Executor-Verifier structure to break down gameplay, and a scoring system for selecting high-quality training samples. Comprehensive analysis using SC2Arena provides valuable insights into developing generalist agents that were not possible with previous benchmarks. Experimental results also demonstrate that our proposed StarEvolve achieves superior performance in strategic planning. Our code, environment, and algorithms are publicly available.
DPMT: Dual Process Multi-scale Theory of Mind Framework for Real-time Human-AI Collaboration
Jul 18, 2025Real-time human-artificial intelligence (AI) collaboration is crucial yet challenging, especially when AI agents must adapt to diverse and unseen human behaviors in dynamic scenarios. Existing large language model (LLM) agents often fail to accurately model the complex human mental characteristics such as domain intentions, especially in the absence of direct communication. To address this limitation, we propose a novel dual process multi-scale theory of mind (DPMT) framework, drawing inspiration from cognitive science dual process theory. Our DPMT framework incorporates a multi-scale theory of mind (ToM) module to facilitate robust human partner modeling through mental characteristic reasoning. Experimental results demonstrate that DPMT significantly enhances human-AI collaboration, and ablation studies further validate the contributions of our multi-scale ToM in the slow system.
LVC: A Lightweight Compression Framework for Enhancing VLMs in Long Video Understanding
Apr 09, 2025Long video understanding is a complex task that requires both spatial detail and temporal awareness. While Vision-Language Models (VLMs) obtain frame-level understanding capabilities through multi-frame input, they suffer from information loss due to the sparse sampling strategy. In contrast, Video Large Language Models (Video-LLMs) capture temporal relationships within visual features but are limited by the scarcity of high-quality video-text datasets. To transfer long video understanding capabilities to VLMs with minimal data and computational cost, we propose Lightweight Video Compression (LVC), a novel method featuring the Query-Attention Video Compression mechanism, which effectively tackles the sparse sampling problem in VLMs. By training only the alignment layer with 10k short video-text pairs, LVC significantly enhances the temporal reasoning abilities of VLMs. Extensive experiments show that LVC provides consistent performance improvements across various models, including the InternVL2 series and Phi-3.5-Vision. Notably, the InternVL2-40B-LVC achieves scores of 68.2 and 65.9 on the long video understanding benchmarks MLVU and Video-MME, respectively, with relative improvements of 14.6% and 7.7%. The enhanced models and code will be publicly available soon.
UniViTAR: Unified Vision Transformer with Native Resolution
Apr 02, 2025Conventional Vision Transformer simplifies visual modeling by standardizing input resolutions, often disregarding the variability of natural visual data and compromising spatial-contextual fidelity. While preliminary explorations have superficially investigated native resolution modeling, existing approaches still lack systematic analysis from a visual representation perspective. To bridge this gap, we introduce UniViTAR, a family of homogeneous vision foundation models tailored for unified visual modality and native resolution scenario in the era of multimodal. Our framework first conducts architectural upgrades to the vanilla paradigm by integrating multiple advanced components. Building upon these improvements, a progressive training paradigm is introduced, which strategically combines two core mechanisms: (1) resolution curriculum learning, transitioning from fixed-resolution pretraining to native resolution tuning, thereby leveraging ViT's inherent adaptability to variable-length sequences, and (2) visual modality adaptation via inter-batch image-video switching, which balances computational efficiency with enhanced temporal reasoning. In parallel, a hybrid training framework further synergizes sigmoid-based contrastive loss with feature distillation from a frozen teacher model, thereby accelerating early-stage convergence. Finally, trained exclusively on public datasets, externsive experiments across multiple model scales from 0.3B to 1B demonstrate its effectiveness.
Retinex-MEF: Retinex-based Glare Effects Aware Unsupervised Multi-Exposure Image Fusion
Mar 10, 2025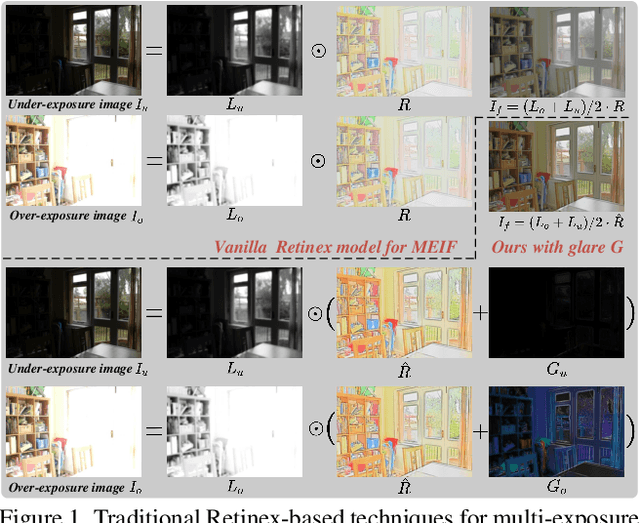
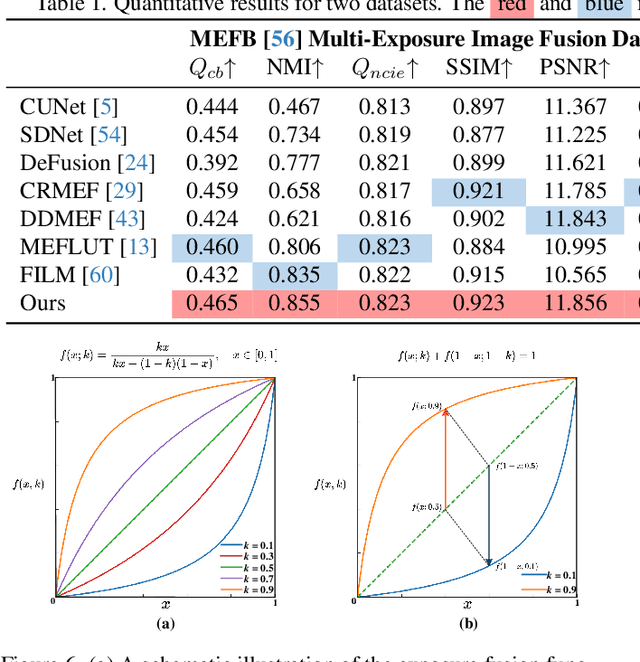
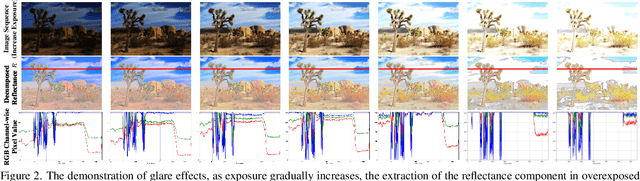
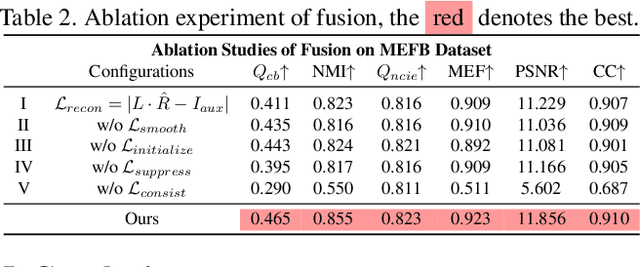
Multi-exposure image fusion consolidates multiple low dynamic range images of the same scene into a singular high dynamic range image. Retinex theory, which separates image illumination from scene reflectance, is naturally adopted to ensure consistent scene representation and effective information fusion across varied exposure levels. However, the conventional pixel-wise multiplication of illumination and reflectance inadequately models the glare effect induced by overexposure. To better adapt this theory for multi-exposure image fusion, we introduce an unsupervised and controllable method termed~\textbf{(Retinex-MEF)}. Specifically, our method decomposes multi-exposure images into separate illumination components and a shared reflectance component, and effectively modeling the glare induced by overexposure. Employing a bidirectional loss constraint to learn the common reflectance component, our approach effectively mitigates the glare effect. Furthermore, we establish a controllable exposure fusion criterion, enabling global exposure adjustments while preserving contrast, thus overcoming the constraints of fixed-level fusion. A series of experiments across multiple datasets, including underexposure-overexposure fusion, exposure control fusion, and homogeneous extreme exposure fusion, demonstrate the effective decomposition and flexible fusion capability of our model.
Deep Unfolding Multi-modal Image Fusion Network via Attribution Analysis
Feb 03, 2025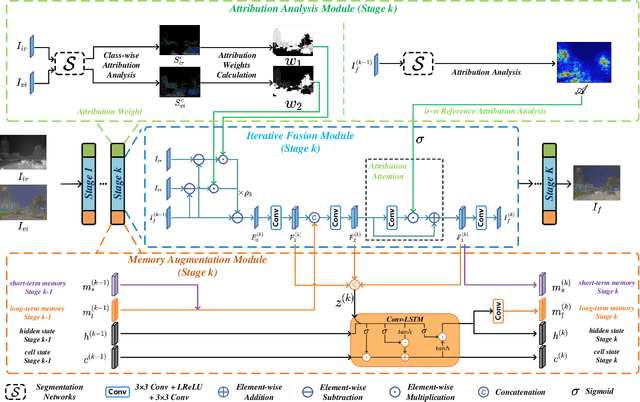

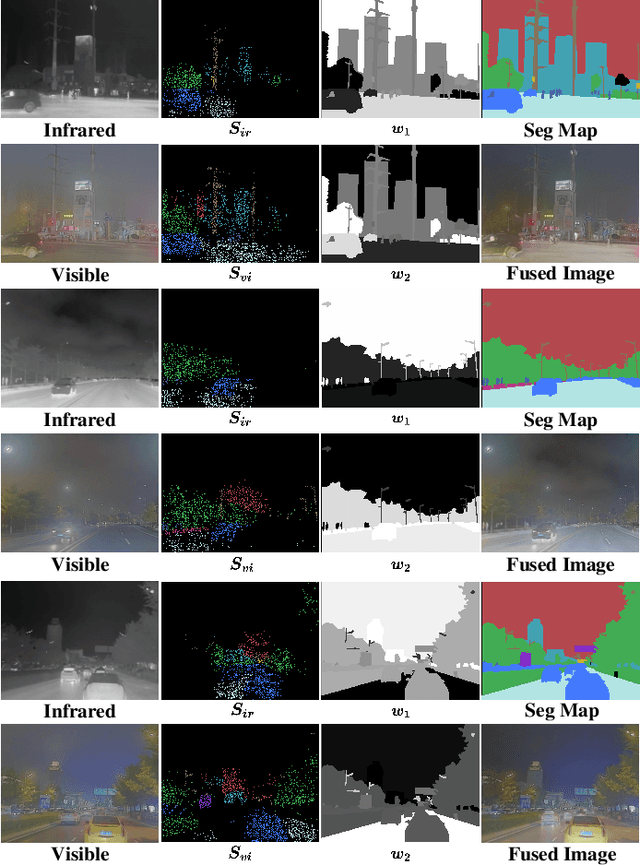
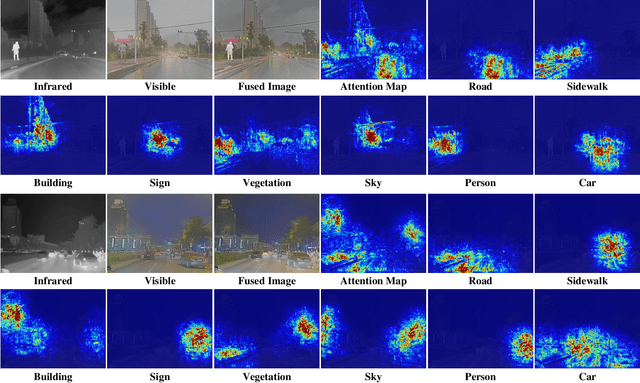
Multi-modal image fusion synthesizes information from multiple sources into a single image, facilitating downstream tasks such as semantic segmentation. Current approaches primarily focus on acquiring informative fusion images at the visual display stratum through intricate mappings. Although some approaches attempt to jointly optimize image fusion and downstream tasks, these efforts often lack direct guidance or interaction, serving only to assist with a predefined fusion loss. To address this, we propose an ``Unfolding Attribution Analysis Fusion network'' (UAAFusion), using attribution analysis to tailor fused images more effectively for semantic segmentation, enhancing the interaction between the fusion and segmentation. Specifically, we utilize attribution analysis techniques to explore the contributions of semantic regions in the source images to task discrimination. At the same time, our fusion algorithm incorporates more beneficial features from the source images, thereby allowing the segmentation to guide the fusion process. Our method constructs a model-driven unfolding network that uses optimization objectives derived from attribution analysis, with an attribution fusion loss calculated from the current state of the segmentation network. We also develop a new pathway function for attribution analysis, specifically tailored to the fusion tasks in our unfolding network. An attribution attention mechanism is integrated at each network stage, allowing the fusion network to prioritize areas and pixels crucial for high-level recognition tasks. Additionally, to mitigate the information loss in traditional unfolding networks, a memory augmentation module is incorporated into our network to improve the information flow across various network layers. Extensive experiments demonstrate our method's superiority in image fusion and applicability to semantic segmentation.