 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIR-ALIGN: Enhancing Hyperspectral Image Restoration via Diffusion-Based Data Generation
May 13, 2026Hyperspectral image (HSI) restoration is crucial for reliable analysis, as real HSIs suffer from degradations like noise, blur, and resolution loss. However, existing models trained on source data often fail on target domains lacking clean references, a common occurrence in practice. To address this issue, we present HIR-ALIGN, a plug-and-play target-adaptive augmentation framework that enhances hyperspectral image restoration by augmenting limited training images with synthetic data that closely matches the target distribution using no extra data. It consists of three stages: (i) proxy generation, where off-the-shelf restoration models restore degraded target observations to produce semantics-preserving proxy HSIs that approximate target-domain clean images; (ii) distribution-adaptive synthesis, where a blur-robust unCLIP diffusion model generates target-aligned RGBs from proxy RGBs, with prompt conditioning and embedding-space noise initialization. Then, a warp-based spectral transfer module synthesizes HSIs by aligning each generated RGB with the proxy RGB, estimating soft patch-wise transport weights, and applying these weights and learnable local interpolation kernels to the proxy HSI; and (iii) aligned supervised finetuning, where restoration networks pretrained on the source distribution are finetuned using both the proxy HSIs and synthesized target-aligned HSIs, and are then deployed on degraded target images. We further provide theoretical analysis showing that augmentation-based finetuning can achieve lower target-domain restoration risk by jointly improving target distribution coverage and controlling spectral bias. Extensive experiments on simulated and real datasets across denoising and super-resolution tasks demonstrate that HIR-ALIGN consistently improves source-only supervised baselines, outperforming both source-only counterparts and representative unsupervised methods.
ChangeQuery: Advancing Remote Sensing Change Analysis for Natural and Human-Induced Disasters from Visual Detection to Semantic Understanding
Apr 24, 2026Rapid situational awareness is critical in post-disaster response. While remote sensing damage assessment is evolving from pixel-level change detection to high-level semantic analysis, existing vision-language methodologies still struggle to provide actionable intelligence for complex strategic queries. They remain severely constrained by unimodal optical dependence, a prevailing bias towards natural disasters, and a fundamental lack of grounded interactivity. To address these limitations, we present ChangeQuery, a unified multimodal framework designed for comprehensive, all-weather disaster situation awareness. To overcome modality constraints and scenario biases, we construct the Disaster-Induced Change Query (DICQ) dataset, a large-scale benchmark coupling pre-event optical semantics with post-event SAR structural features across a balanced distribution of natural catastrophes and armed conflicts. Furthermore, to provide the high-quality supervision required for interactive reasoning, we propose a novel Automated Semantic Annotation Pipeline. Adhering to a ``statistics-first, generation-later'' paradigm, this engine automatically transforms raw segmentation masks into grounded, hierarchical instruction sets, effectively equipping the model with fine-grained spatial and quantitative awareness. Trained on this structured data, the ChangeQuery architecture operates as an interactive disaster analyst. It supports multi-task reasoning driven by diverse user queries, delivering precise damage quantification, region-specific descriptions, and holistic post-disaster summaries. Extensive experiments demonstrate that ChangeQuery establishes a new state-of-the-art, providing a robust and interpretable solution for complex disaster monitoring. The code is available at \href{https://sundongwei.github.io/changequery/}{https://sundongwei.github.io/changequery/}.
The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
Layout-Guided Controllable Pathology Image Generation with In-Context Diffusion Transformers
Mar 11, 2026Controllable pathology image synthesis requires reliable regulation of spatial layout, tissue morphology, and semantic detail. However, existing text-guided diffusion models offer only coarse global control and lack the ability to enforce fine-grained structural constraints. Progress is further limited by the absence of large datasets that pair patch-level spatial layouts with detailed diagnostic descriptions, since generating such annotations for gigapixel whole-slide images is prohibitively time-consuming for human experts. To overcome these challenges, we first develop a scalable multi-agent LVLM annotation framework that integrates image description, diagnostic step extraction, and automatic quality judgment into a coordinated pipeline, and we evaluate the reliability of the system through a human verification process. This framework enables efficient construction of fine-grained and clinically aligned supervision at scale. Building on the curated data, we propose In-Context Diffusion Transformer (IC-DiT), a layout-aware generative model that incorporates spatial layouts, textual descriptions, and visual embeddings into a unified diffusion transformer. Through hierarchical multimodal attention, IC-DiT maintains global semantic coherence while accurately preserving structural and morphological details. Extensive experiments on five histopathology datasets show that IC-DiT achieves higher fidelity, stronger spatial controllability, and better diagnostic consistency than existing methods. In addition, the generated images serve as effective data augmentation resources for downstream tasks such as cancer classification and survival analysis.
Exchange Is All You Need for Remote Sensing Change Detection
Jan 12, 2026Remote sensing change detection fundamentally relies on the effective fusion and discrimination of bi-temporal features. Prevailing paradigms typically utilize Siamese encoders bridged by explicit difference computation modules, such as subtraction or concatenation, to identify changes. In this work, we challenge this complexity with SEED (Siamese Encoder-Exchange-Decoder), a streamlined paradigm that replaces explicit differencing with parameter-free feature exchange. By sharing weights across both Siamese encoders and decoders, SEED effectively operates as a single parameter set model. Theoretically, we formalize feature exchange as an orthogonal permutation operator and prove that, under pixel consistency, this mechanism preserves mutual information and Bayes optimal risk, whereas common arithmetic fusion methods often introduce information loss. Extensive experiments across five benchmarks, including SYSU-CD, LEVIR-CD, PX-CLCD, WaterCD, and CDD, and three backbones, namely SwinT, EfficientNet, and ResNet, demonstrate that SEED matches or surpasses state of the art methods despite its simplicity. Furthermore, we reveal that standard semantic segmentation models can be transformed into competitive change detectors solely by inserting this exchange mechanism, referred to as SEG2CD. The proposed paradigm offers a robust, unified, and interpretable framework for change detection, demonstrating that simple feature exchange is sufficient for high performance information fusion. Code and full training and evaluation protocols will be released at https://github.com/dyzy41/open-rscd.
SegEarth-R2: Towards Comprehensive Language-guided Segmentation for Remote Sensing Images
Dec 23, 2025Effectively grounding complex language to pixels in remote sensing (RS) images is a critical challenge for applications like disaster response and environmental monitoring. Current models can parse simple, single-target commands but fail when presented with complex geospatial scenarios, e.g., segmenting objects at various granularities, executing multi-target instructions, and interpreting implicit user intent. To drive progress against these failures, we present LaSeRS, the first large-scale dataset built for comprehensive training and evaluation across four critical dimensions of language-guided segmentation: hierarchical granularity, target multiplicity, reasoning requirements, and linguistic variability. By capturing these dimensions, LaSeRS moves beyond simple commands, providing a benchmark for complex geospatial reasoning. This addresses a critical gap: existing datasets oversimplify, leading to sensitivity-prone real-world models. We also propose SegEarth-R2, an MLLM architecture designed for comprehensive language-guided segmentation in RS, which directly confronts these challenges. The model's effectiveness stems from two key improvements: (1) a spatial attention supervision mechanism specifically handles the localization of small objects and their components, and (2) a flexible and efficient segmentation query mechanism that handles both single-target and multi-target scenarios. Experimental results demonstrate that our SegEarth-R2 achieves outstanding performance on LaSeRS and other benchmarks, establishing a powerful baseline for the next generation of geospatial segmentation. All data and code will be released at https://github.com/earth-insights/SegEarth-R2.
SegEarth-OV3: Exploring SAM 3 for Open-Vocabulary Semantic Segmentation in Remote Sensing Images
Dec 09, 2025Most existing methods for training-free Open-Vocabulary Semantic Segmentation (OVSS) are based on CLIP. While these approaches have made progress, they often face challenges in precise localization or require complex pipelines to combine separate modules, especially in remote sensing scenarios where numerous dense and small targets are present. Recently, Segment Anything Model 3 (SAM 3) was proposed, unifying segmentation and recognition in a promptable framework. In this paper, we present a preliminary exploration of applying SAM 3 to the remote sensing OVSS task without any training. First, we implement a mask fusion strategy that combines the outputs from SAM 3's semantic segmentation head and the Transformer decoder (instance head). This allows us to leverage the strengths of both heads for better land coverage. Second, we utilize the presence score from the presence head to filter out categories that do not exist in the scene, reducing false positives caused by the vast vocabulary sizes and patch-level processing in geospatial scenes. We evaluate our method on extensive remote sensing datasets. Experiments show that this simple adaptation achieves promising performance, demonstrating the potential of SAM 3 for remote sensing OVSS. Our code is released at https://github.com/earth-insights/SegEarth-OV-3.
ZoomEarth: Active Perception for Ultra-High-Resolution Geospatial Vision-Language Tasks
Nov 15, 2025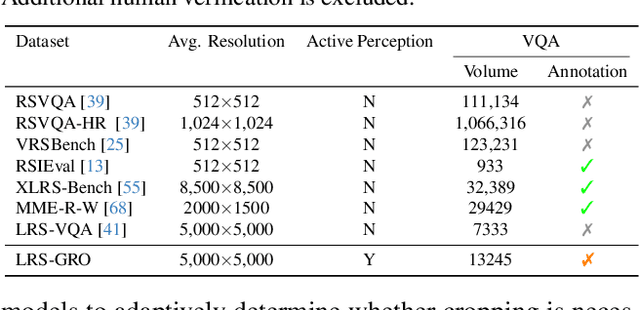
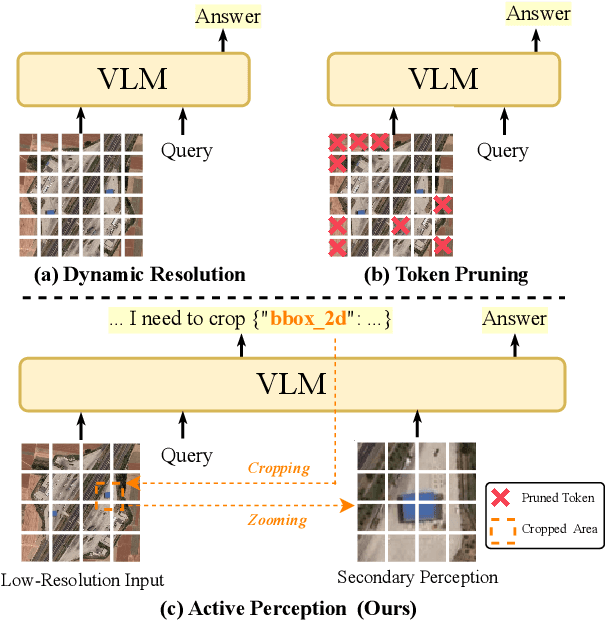
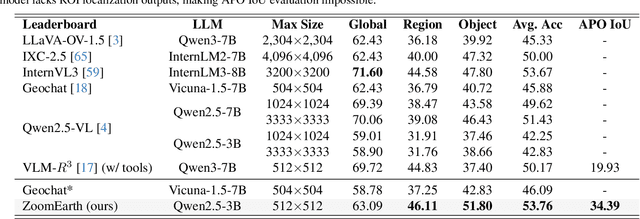
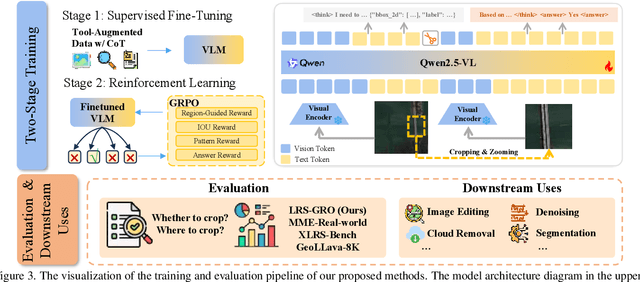
Ultra-high-resolution (UHR) remote sensing (RS) images offer rich fine-grained information but also present challenges in effective processing. Existing dynamic resolution and token pruning methods are constrained by a passive perception paradigm, suffering from increased redundancy when obtaining finer visual inputs. In this work, we explore a new active perception paradigm that enables models to revisit information-rich regions. First, we present LRS-GRO, a large-scale benchmark dataset tailored for active perception in UHR RS processing, encompassing 17 question types across global, region, and object levels, annotated via a semi-automatic pipeline. Building on LRS-GRO, we propose ZoomEarth, an adaptive cropping-zooming framework with a novel Region-Guided reward that provides fine-grained guidance. Trained via supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO), ZoomEarth achieves state-of-the-art performance on LRS-GRO and, in the zero-shot setting, on three public UHR remote sensing benchmarks. Furthermore, ZoomEarth can be seamlessly integrated with downstream models for tasks such as cloud removal, denoising, segmentation, and image editing through simple tool interfaces, demonstrating strong versatility and extensibility.
Annotation-Free Open-Vocabulary Segmentation for Remote-Sensing Images
Aug 25, 2025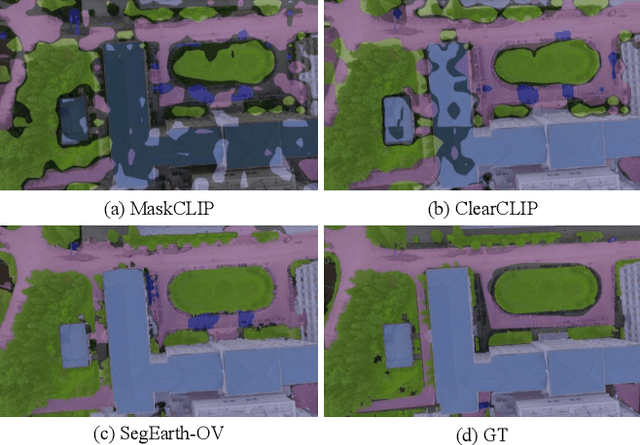
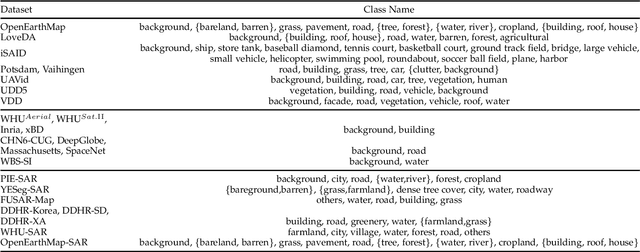
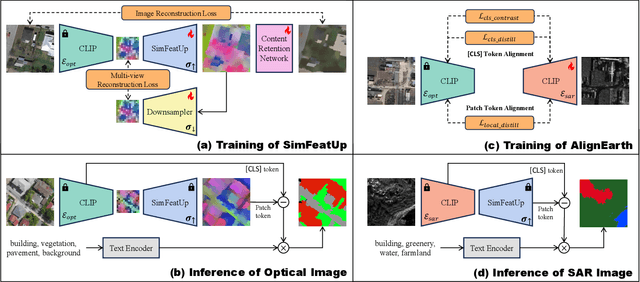
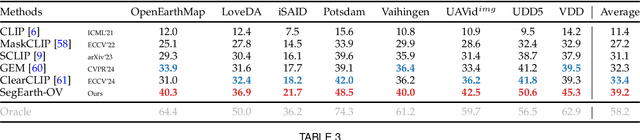
Semantic segmentation of remote sensing (RS) images is pivotal for comprehensive Earth observation, but the demand for interpreting new object categories, coupled with the high expense of manual annotation, poses significant challenges. Although open-vocabulary semantic segmentation (OVSS) offers a promising solution, existing frameworks designed for natural images are insufficient for the unique complexities of RS data. They struggle with vast scale variations and fine-grained details, and their adaptation often relies on extensive, costly annotations. To address this critical gap, this paper introduces SegEarth-OV, the first framework for annotation-free open-vocabulary segmentation of RS images. Specifically, we propose SimFeatUp, a universal upsampler that robustly restores high-resolution spatial details from coarse features, correcting distorted target shapes without any task-specific post-training. We also present a simple yet effective Global Bias Alleviation operation to subtract the inherent global context from patch features, significantly enhancing local semantic fidelity. These components empower SegEarth-OV to effectively harness the rich semantics of pre-trained VLMs, making OVSS possible in optical RS contexts. Furthermore, to extend the framework's universality to other challenging RS modalities like SAR images, where large-scale VLMs are unavailable and expensive to create, we introduce AlignEarth, which is a distillation-based strategy and can efficiently transfer semantic knowledge from an optical VLM encoder to an SAR encoder, bypassing the need to build SAR foundation models from scratch and enabling universal OVSS across diverse sensor types. Extensive experiments on both optical and SAR datasets validate that SegEarth-OV can achieve dramatic improvements over the SOTA methods, establishing a robust foundation for annotation-free and open-world Earth observation.