 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dimensional Visual Data Recovery: Scale-Aware Tensor Modeling and Accelerated Randomized Computation
Feb 13, 2026The recently proposed fully-connected tensor network (FCTN) decomposition has demonstrated significant advantages in correlation characterization and transpositional invariance, and has achieved notable achievements in multi-dimensional data processing and analysis. However, existing multi-dimensional data recovery methods leveraging FCTN decomposition still have room for further enhancement, particularly in computational efficiency and modeling capability. To address these issues, we first propose a FCTN-based generalized nonconvex regularization paradigm from the perspective of gradient mapping. Then, reliable and scalable multi-dimensional data recovery models are investigated, where the model formulation is shifted from unquantized observations to coarse-grained quantized observations. Based on the alternating direction method of multipliers (ADMM) framework, we derive efficient optimization algorithms with convergence guarantees to solve the formulated models. To alleviate the computational bottleneck encountered when processing large-scale multi-dimensional data, fast and efficient randomized compression algorithms are devised in virtue of sketching techniques in numerical linear algebra. These dimensionality-reduction techniques serve as the computational acceleration core of our proposed algorithm framework. Theoretical results on approximation error upper bounds and convergence analysis for the proposed method are derived. Extensive numerical experiments illustrate the effectiveness and superiority of the proposed algorithm over other state-of-the-art methods in terms of quantitative metrics, visual quality, and running time.
A Pluggable Multi-Task Learning Framework for Sentiment-Aware Financial Relation Extraction
Jun 14, 2025Relation Extraction (RE) aims to extract semantic relationships in texts from given entity pairs, and has achieved significant improvements. However, in different domains, the RE task can be influenced by various factors. For example, in the financial domain, sentiment can affect RE results, yet this factor has been overlooked by modern RE models. To address this gap, this paper proposes a Sentiment-aware-SDP-Enhanced-Module (SSDP-SEM), a multi-task learning approach for enhancing financial RE. Specifically, SSDP-SEM integrates the RE models with a pluggable auxiliary sentiment perception (ASP) task, enabling the RE models to concurrently navigate their attention weights with the text's sentiment. We first generate detailed sentiment tokens through a sentiment model and insert these tokens into an instance. Then, the ASP task focuses on capturing nuanced sentiment information through predicting the sentiment token positions, combining both sentiment insights and the Shortest Dependency Path (SDP) of syntactic information. Moreover, this work employs a sentiment attention information bottleneck regularization method to regulate the reasoning process. Our experiment integrates this auxiliary task with several prevalent frameworks, and the results demonstrate that most previous models benefit from the auxiliary task, thereby achieving better results. These findings highlight the importance of effectively leveraging sentiment in the financial RE task.
Accelerating Large-Scale Regularized High-Order Tensor Recovery
Jun 11, 2025Currently, existing tensor recovery methods fail to recognize the impact of tensor scale variations on their structural characteristics. Furthermore, existing studies face prohibitive computational costs when dealing with large-scale high-order tensor data. To alleviate these issue, assisted by the Krylov subspace iteration, block Lanczos bidiagonalization process, and random projection strategies, this article first devises two fast and accurate randomized algorithms for low-rank tensor approximation (LRTA) problem. Theoretical bounds on the accuracy of the approximation error estimate are established. Next, we develop a novel generalized nonconvex modeling framework tailored to large-scale tensor recovery, in which a new regularization paradigm is exploited to achieve insightful prior representation for large-scale tensors. On the basis of the above, we further investigate new unified nonconvex models and efficient optimization algorithms, respectively, for several typical high-order tensor recovery tasks in unquantized and quantized situations. To render the proposed algorithms practical and efficient for large-scale tensor data, the proposed randomized LRTA schemes are integrated into their central and time-intensive computations. Finally, we conduct extensive experiments on various large-scale tensors, whose results demonstrate the practicability, effectiveness and superiority of the proposed method in comparison with some state-of-the-art approaches.
Hyperspectral Anomaly Detection Fused Unified Nonconvex Tensor Ring Factors Regularization
May 23, 2025In recent years, tensor decomposition-based approaches for hyperspectral anomaly detection (HAD) have gained significant attention in the field of remote sensing. However, existing methods often fail to fully leverage both the global correlations and local smoothness of the background components in hyperspectral images (HSIs), which exist in both the spectral and spatial domains. This limitation results in suboptimal detection performance. To mitigate this critical issue, we put forward a novel HAD method named HAD-EUNTRFR, which incorporates an enhanced unified nonconvex tensor ring (TR) factors regularization. In the HAD-EUNTRFR framework, the raw HSIs are first decomposed into background and anomaly components. The TR decomposition is then employed to capture the spatial-spectral correlations within the background component. Additionally, we introduce a unified and efficient nonconvex regularizer, induced by tensor singular value decomposition (TSVD), to simultaneously encode the low-rankness and sparsity of the 3-D gradient TR factors into a unique concise form. The above characterization scheme enables the interpretable gradient TR factors to inherit the low-rankness and smoothness of the original background. To further enhance anomaly detection, we design a generalized nonconvex regularization term to exploit the group sparsity of the anomaly component. To solve the resulting doubly nonconvex model, we develop a highly efficient optimization algorithm based on the alternating direction method of multipliers (ADMM) framework. Experimental results on several benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art (SOTA) approaches in terms of detection accuracy.
Label Distribution Learning with Biased Annotations by Learning Multi-Label Representation
Feb 03, 2025Multi-label learning (MLL) has gained attention for its ability to represent real-world data. Label Distribution Learning (LDL), an extension of MLL to learning from label distributions, faces challenges in collecting accurate label distributions. To address the issue of biased annotations, based on the low-rank assumption, existing works recover true distributions from biased observations by exploring the label correlations. However, recent evidence shows that the label distribution tends to be full-rank, and naive apply of low-rank approximation on biased observation leads to inaccurate recovery and performance degradation. In this paper, we address the LDL with biased annotations problem from a novel perspective, where we first degenerate the soft label distribution into a hard multi-hot label and then recover the true label information for each instance. This idea stems from an insight that assigning hard multi-hot labels is often easier than assigning a soft label distribution, and it shows stronger immunity to noise disturbances, leading to smaller label bias. Moreover, assuming that the multi-label space for predicting label distributions is low-rank offers a more reasonable approach to capturing label correlations. Theoretical analysis and experiments confirm the effectiveness and robustness of our method on real-world datasets.
Guaranteed Multidimensional Time Series Prediction via Deterministic Tensor Completion Theory
Jan 26, 2025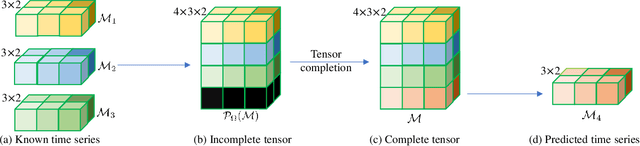



In recent years, the prediction of multidimensional time series data has become increasingly important due to its wide-ranging applications. Tensor-based prediction methods have gained attention for their ability to preserve the inherent structure of such data. However, existing approaches, such as tensor autoregression and tensor decomposition, often have consistently failed to provide clear assertions regarding the number of samples that can be exactly predicted. While matrix-based methods using nuclear norms address this limitation, their reliance on matrices limits accuracy and increases computational costs when handling multidimensional data. To overcome these challenges, we reformulate multidimensional time series prediction as a deterministic tensor completion problem and propose a novel theoretical framework. Specifically, we develop a deterministic tensor completion theory and introduce the Temporal Convolutional Tensor Nuclear Norm (TCTNN) model. By convolving the multidimensional time series along the temporal dimension and applying the tensor nuclear norm, our approach identifies the maximum forecast horizon for exact predictions. Additionally, TCTNN achieves superior performance in prediction accuracy and computational efficiency compared to existing methods across diverse real-world datasets, including climate temperature, network flow, and traffic ride data. Our implementation is publicly available at https://github.com/HaoShu2000/TCTNN.
Nonconvex Robust High-Order Tensor Completion Using Randomized Low-Rank Approximation
May 19, 2023Within the tensor singular value decomposition (T-SVD) framework, existing robust low-rank tensor completion approaches have made great achievements in various areas of science and engineering. Nevertheless, these methods involve the T-SVD based low-rank approximation, which suffers from high computational costs when dealing with large-scale tensor data. Moreover, most of them are only applicable to third-order tensors. Against these issues, in this article, two efficient low-rank tensor approximation approaches fusing randomized techniques are first devised under the order-d (d >= 3) T-SVD framework. On this basis, we then further investigate the robust high-order tensor completion (RHTC) problem, in which a double nonconvex model along with its corresponding fast optimization algorithms with convergence guarantees are developed. To the best of our knowledge, this is the first study to incorporate the randomized low-rank approximation into the RHTC problem. Empirical studies on large-scale synthetic and real tensor data illustrate that the proposed method outperforms other state-of-the-art approaches in terms of both computational efficiency and estimated precision.
Guaranteed Tensor Recovery Fused Low-rankness and Smoothness
Feb 04, 2023
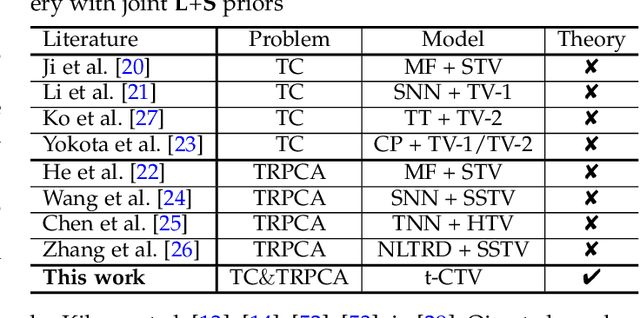
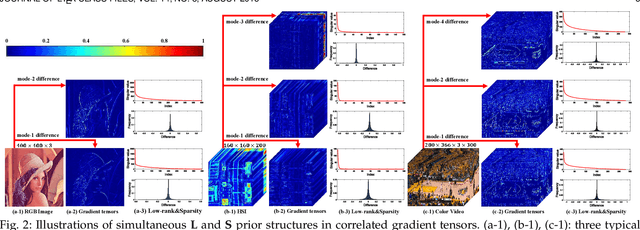

The tensor data recovery task has thus attracted much research attention in recent years. Solving such an ill-posed problem generally requires to explore intrinsic prior structures underlying tensor data, and formulate them as certain forms of regularization terms for guiding a sound estimate of the restored tensor. Recent research have made significant progress by adopting two insightful tensor priors, i.e., global low-rankness (L) and local smoothness (S) across different tensor modes, which are always encoded as a sum of two separate regularization terms into the recovery models. However, unlike the primary theoretical developments on low-rank tensor recovery, these joint L+S models have no theoretical exact-recovery guarantees yet, making the methods lack reliability in real practice. To this crucial issue, in this work, we build a unique regularization term, which essentially encodes both L and S priors of a tensor simultaneously. Especially, by equipping this single regularizer into the recovery models, we can rigorously prove the exact recovery guarantees for two typical tensor recovery tasks, i.e., tensor completion (TC) and tensor robust principal component analysis (TRPCA). To the best of our knowledge, this should be the first exact-recovery results among all related L+S methods for tensor recovery. Significant recovery accuracy improvements over many other SOTA methods in several TC and TRPCA tasks with various kinds of visual tensor data are observed in extensive experiments. Typically, our method achieves a workable performance when the missing rate is extremely large, e.g., 99.5%, for the color image inpainting task, while all its peers totally fail in such challenging case.
VQA and Visual Reasoning: An Overview of Recent Datasets, Methods and Challenges
Dec 26, 2022
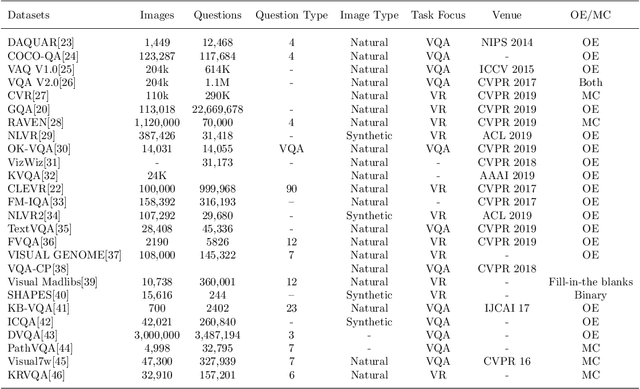
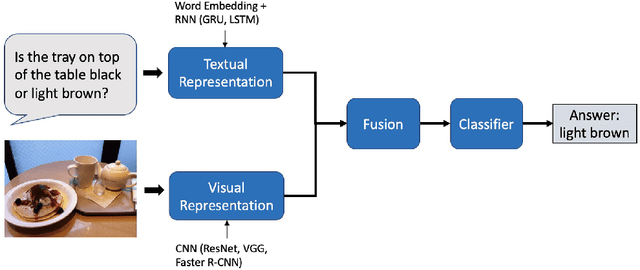

Artificial Intelligence (AI) and its applications have sparked extraordinary interest in recent years. This achievement can be ascribed in part to advances in AI subfields including Machine Learning (ML), Computer Vision (CV), and Natural Language Processing (NLP). Deep learning, a sub-field of machine learning that employs artificial neural network concepts, has enabled the most rapid growth in these domains. The integration of vision and language has sparked a lot of attention as a result of this. The tasks have been created in such a way that they properly exemplify the concepts of deep learning. In this review paper, we provide a thorough and an extensive review of the state of the arts approaches, key models design principles and discuss existing datasets, methods, their problem formulation and evaluation measures for VQA and Visual reasoning tasks to understand vision and language representation learning. We also present some potential future paths in this field of research, with the hope that our study may generate new ideas and novel approaches to handle existing difficulties and develop new applications.
Fast Noise Removal in Hyperspectral Images via Representative Coefficient Total Variation
Nov 03, 2022Mining structural priors in data is a widely recognized technique for hyperspectral image (HSI) denoising tasks, whose typical ways include model-based methods and data-based methods. The model-based methods have good generalization ability, while the runtime cannot meet the fast processing requirements of the practical situations due to the large size of an HSI data $ \mathbf{X} \in \mathbb{R}^{MN\times B}$. For the data-based methods, they perform very fast on new test data once they have been trained. However, their generalization ability is always insufficient. In this paper, we propose a fast model-based HSI denoising approach. Specifically, we propose a novel regularizer named Representative Coefficient Total Variation (RCTV) to simultaneously characterize the low rank and local smooth properties. The RCTV regularizer is proposed based on the observation that the representative coefficient matrix $\mathbf{U}\in\mathbb{R}^{MN\times R} (R\ll B)$ obtained by orthogonally transforming the original HSI $\mathbf{X}$ can inherit the strong local-smooth prior of $\mathbf{X}$. Since $R/B$ is very small, the HSI denoising model based on the RCTV regularizer has lower time complexity. Additionally, we find that the representative coefficient matrix $\mathbf{U}$ is robust to noise, and thus the RCTV regularizer can somewhat promote the robustness of the HSI denoising model. Extensive experiments on mixed noise removal demonstrate the superiority of the proposed method both in denoising performance and denoising speed compared with other state-of-the-art methods. Remarkably, the denoising speed of our proposed method outperforms all the model-based techniques and is comparable with the deep learning-based approaches.