 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Recovery of Non-Random Missing Multidimensional Time Series via Temporal Isometric Delay-Embedding Transform
Dec 11, 2025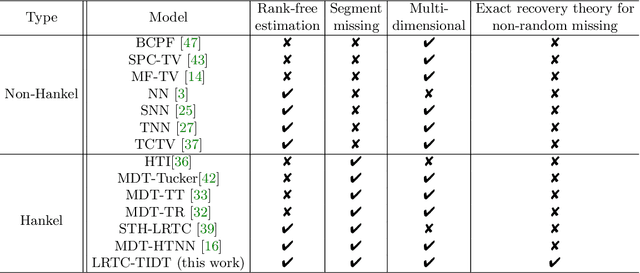
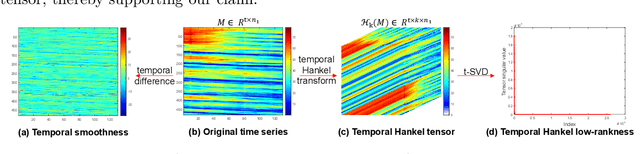
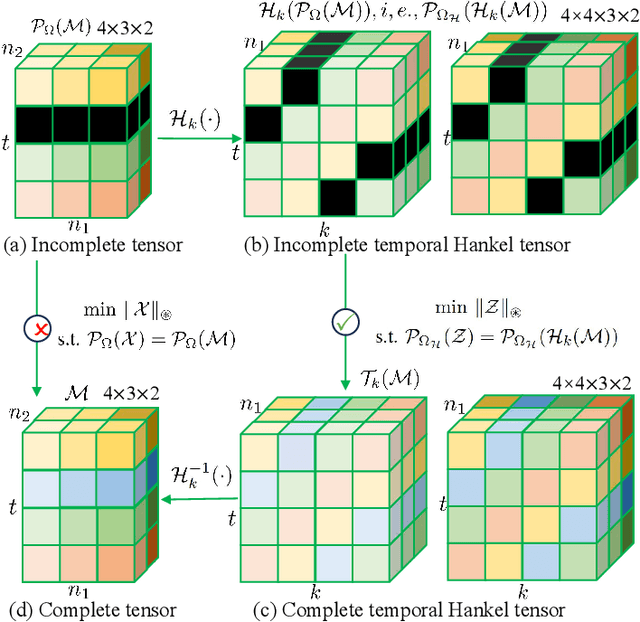
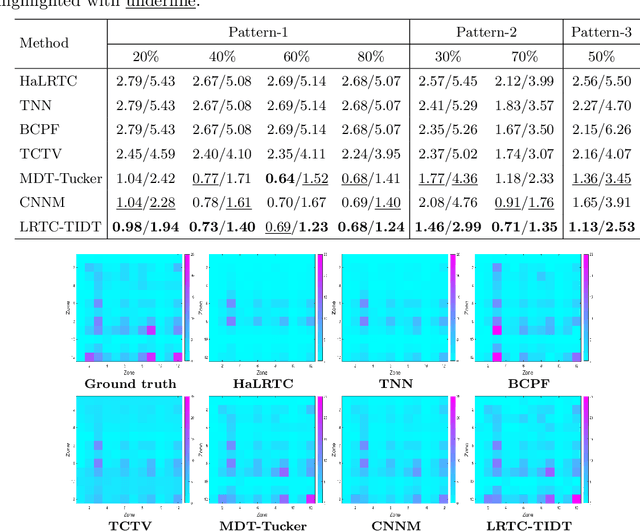
Non-random missing data is a ubiquitous yet undertreated flaw in multidimensional time series, fundamentally threatening the reliability of data-driven analysis and decision-making. Pure low-rank tensor completion, as a classical data recovery method, falls short in handling non-random missingness, both methodologically and theoretically. Hankel-structured tensor completion models provide a feasible approach for recovering multidimensional time series with non-random missing patterns. However, most Hankel-based multidimensional data recovery methods both suffer from unclear sources of Hankel tensor low-rankness and lack an exact recovery theory for non-random missing data. To address these issues, we propose the temporal isometric delay-embedding transform, which constructs a Hankel tensor whose low-rankness is naturally induced by the smoothness and periodicity of the underlying time series. Leveraging this property, we develop the \textit{Low-Rank Tensor Completion with Temporal Isometric Delay-embedding Transform} (LRTC-TIDT) model, which characterizes the low-rank structure under the \textit{Tensor Singular Value Decomposition} (t-SVD) framework. Once the prescribed non-random sampling conditions and mild incoherence assumptions are satisfied, the proposed LRTC-TIDT model achieves exact recovery, as confirmed by simulation experiments under various non-random missing patterns. Furthermore, LRTC-TIDT consistently outperforms existing tensor-based methods across multiple real-world tasks, including network flow reconstruction, urban traffic estimation, and temperature field prediction. Our implementation is publicly available at https://github.com/HaoShu2000/LRTC-TIDT.
Dynamic Graph Induced Contour-aware Heat Conduction Network for Event-based Object Detection
May 19, 2025Event-based Vision Sensors (EVS) have demonstrated significant advantages over traditional RGB frame-based cameras in low-light conditions, high-speed motion capture, and low latency. Consequently, object detection based on EVS has attracted increasing attention from researchers. Current event stream object detection algorithms are typically built upon Convolutional Neural Networks (CNNs) or Transformers, which either capture limited local features using convolutional filters or incur high computational costs due to the utilization of self-attention. Recently proposed vision heat conduction backbone networks have shown a good balance between efficiency and accuracy; however, these models are not specifically designed for event stream data. They exhibit weak capability in modeling object contour information and fail to exploit the benefits of multi-scale features. To address these issues, this paper proposes a novel dynamic graph induced contour-aware heat conduction network for event stream based object detection, termed CvHeat-DET. The proposed model effectively leverages the clear contour information inherent in event streams to predict the thermal diffusivity coefficients within the heat conduction model, and integrates hierarchical structural graph features to enhance feature learning across multiple scales. Extensive experiments on three benchmark datasets for event stream-based object detection fully validated the effectiveness of the proposed model. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvDET.
Pre-Training Meta-Rule Selection Policy for Visual Generative Abductive Learning
Mar 09, 2025

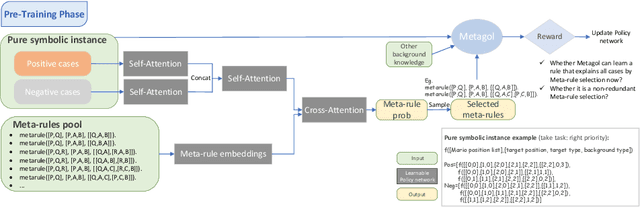
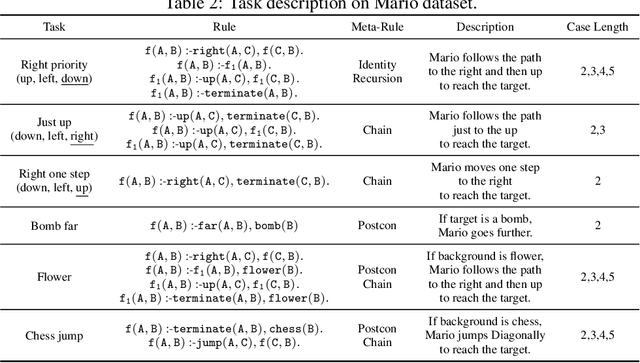
Visual generative abductive learning studies jointly training symbol-grounded neural visual generator and inducing logic rules from data, such that after learning, the visual generation process is guided by the induced logic rules. A major challenge for this task is to reduce the time cost of logic abduction during learning, an essential step when the logic symbol set is large and the logic rule to induce is complicated. To address this challenge, we propose a pre-training method for obtaining meta-rule selection policy for the recently proposed visual generative learning approach AbdGen [Peng et al., 2023], aiming at significantly reducing the candidate meta-rule set and pruning the search space. The selection model is built based on the embedding representation of both symbol grounding of cases and meta-rules, which can be effectively integrated with both neural model and logic reasoning system. The pre-training process is done on pure symbol data, not involving symbol grounding learning of raw visual inputs, making the entire learning process low-cost. An additional interesting observation is that the selection policy can rectify symbol grounding errors unseen during pre-training, which is resulted from the memorization ability of attention mechanism and the relative stability of symbolic patterns. Experimental results show that our method is able to effectively address the meta-rule selection problem for visual abduction, boosting the efficiency of visual generative abductive learning. Code is available at https://github.com/future-item/metarule-select.
XiHeFusion: Harnessing Large Language Models for Science Communication in Nuclear Fusion
Feb 08, 2025



Nuclear fusion is one of the most promising ways for humans to obtain infinite energy. Currently, with the rapid development of artificial intelligence, the mission of nuclear fusion has also entered a critical period of its development. How to let more people to understand nuclear fusion and join in its research is one of the effective means to accelerate the implementation of fusion. This paper proposes the first large model in the field of nuclear fusion, XiHeFusion, which is obtained through supervised fine-tuning based on the open-source large model Qwen2.5-14B. We have collected multi-source knowledge about nuclear fusion tasks to support the training of this model, including the common crawl, eBooks, arXiv, dissertation, etc. After the model has mastered the knowledge of the nuclear fusion field, we further used the chain of thought to enhance its logical reasoning ability, making XiHeFusion able to provide more accurate and logical answers. In addition, we propose a test questionnaire containing 180+ questions to assess the conversational ability of this science popularization large model. Extensive experimental results show that our nuclear fusion dialogue model, XiHeFusion, can perform well in answering science popularization knowledge. The pre-trained XiHeFusion model is released on https://github.com/Event-AHU/XiHeFusion.
Guaranteed Multidimensional Time Series Prediction via Deterministic Tensor Completion Theory
Jan 26, 2025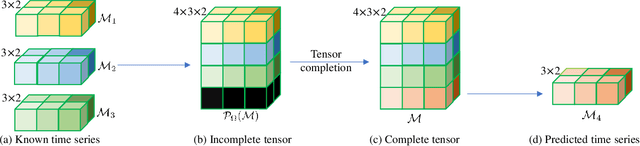



In recent years, the prediction of multidimensional time series data has become increasingly important due to its wide-ranging applications. Tensor-based prediction methods have gained attention for their ability to preserve the inherent structure of such data. However, existing approaches, such as tensor autoregression and tensor decomposition, often have consistently failed to provide clear assertions regarding the number of samples that can be exactly predicted. While matrix-based methods using nuclear norms address this limitation, their reliance on matrices limits accuracy and increases computational costs when handling multidimensional data. To overcome these challenges, we reformulate multidimensional time series prediction as a deterministic tensor completion problem and propose a novel theoretical framework. Specifically, we develop a deterministic tensor completion theory and introduce the Temporal Convolutional Tensor Nuclear Norm (TCTNN) model. By convolving the multidimensional time series along the temporal dimension and applying the tensor nuclear norm, our approach identifies the maximum forecast horizon for exact predictions. Additionally, TCTNN achieves superior performance in prediction accuracy and computational efficiency compared to existing methods across diverse real-world datasets, including climate temperature, network flow, and traffic ride data. Our implementation is publicly available at https://github.com/HaoShu2000/TCTNN.
Object Detection using Event Camera: A MoE Heat Conduction based Detector and A New Benchmark Dataset
Dec 09, 2024



Object detection in event streams has emerged as a cutting-edge research area, demonstrating superior performance in low-light conditions, scenarios with motion blur, and rapid movements. Current detectors leverage spiking neural networks, Transformers, or convolutional neural networks as their core architectures, each with its own set of limitations including restricted performance, high computational overhead, or limited local receptive fields. This paper introduces a novel MoE (Mixture of Experts) heat conduction-based object detection algorithm that strikingly balances accuracy and computational efficiency. Initially, we employ a stem network for event data embedding, followed by processing through our innovative MoE-HCO blocks. Each block integrates various expert modules to mimic heat conduction within event streams. Subsequently, an IoU-based query selection module is utilized for efficient token extraction, which is then channeled into a detection head for the final object detection process. Furthermore, we are pleased to introduce EvDET200K, a novel benchmark dataset for event-based object detection. Captured with a high-definition Prophesee EVK4-HD event camera, this dataset encompasses 10 distinct categories, 200,000 bounding boxes, and 10,054 samples, each spanning 2 to 5 seconds. We also provide comprehensive results from over 15 state-of-the-art detectors, offering a solid foundation for future research and comparison. The source code of this paper will be released on: https://github.com/Event-AHU/OpenEvDET
Flow-Inspired Lightweight Multi-Robot Real-Time Scheduling Planner
Sep 11, 2024Collision avoidance and trajectory planning are crucial in multi-robot systems, particularly in environments with numerous obstacles. Although extensive research has been conducted in this field, the challenge of rapid traversal through such environments has not been fully addressed. This paper addresses this problem by proposing a novel real-time scheduling scheme designed to optimize the passage of multi-robot systems through complex, obstacle-rich maps. Inspired from network flow optimization, our scheme decomposes the environment into a network structure, enabling the efficient allocation of robots to paths based on real-time congestion data. The proposed scheduling planner operates on top of existing collision avoidance algorithms, focusing on minimizing traversal time by balancing robot detours and waiting times. Our simulation results demonstrate the efficiency of the proposed scheme. Additionally, we validated its effectiveness through real world flight tests using ten quadrotors. This work contributes a lightweight, effective scheduling planner capable of meeting the real-time demands of multi-robot systems in obstacle-rich environments.
Enhancing Knowledge Retrieval with In-Context Learning and Semantic Search through Generative AI
Jun 13, 2024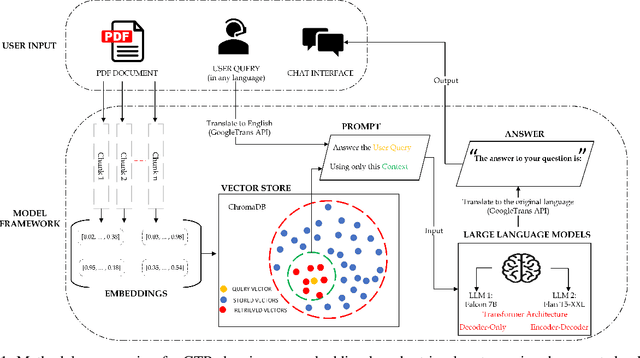

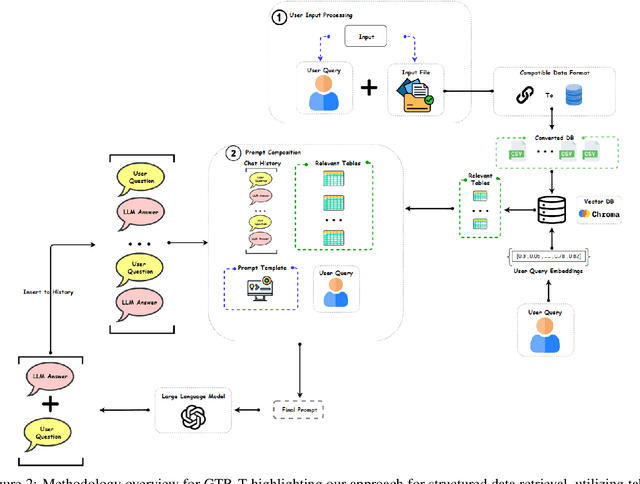

Retrieving and extracting knowledge from extensive research documents and large databases presents significant challenges for researchers, students, and professionals in today's information-rich era. Existing retrieval systems, which rely on general-purpose Large Language Models (LLMs), often fail to provide accurate responses to domain-specific inquiries. Additionally, the high cost of pretraining or fine-tuning LLMs for specific domains limits their widespread adoption. To address these limitations, we propose a novel methodology that combines the generative capabilities of LLMs with the fast and accurate retrieval capabilities of vector databases. This advanced retrieval system can efficiently handle both tabular and non-tabular data, understand natural language user queries, and retrieve relevant information without fine-tuning. The developed model, Generative Text Retrieval (GTR), is adaptable to both unstructured and structured data with minor refinement. GTR was evaluated on both manually annotated and public datasets, achieving over 90% accuracy and delivering truthful outputs in 87% of cases. Our model achieved state-of-the-art performance with a Rouge-L F1 score of 0.98 on the MSMARCO dataset. The refined model, Generative Tabular Text Retrieval (GTR-T), demonstrated its efficiency in large database querying, achieving an Execution Accuracy (EX) of 0.82 and an Exact-Set-Match (EM) accuracy of 0.60 on the Spider dataset, using an open-source LLM. These efforts leverage Generative AI and In-Context Learning to enhance human-text interaction and make advanced AI capabilities more accessible. By integrating robust retrieval systems with powerful LLMs, our approach aims to democratize access to sophisticated AI tools, improving the efficiency, accuracy, and scalability of AI-driven information retrieval and database querying.
Rare Class Prediction Model for Smart Industry in Semiconductor Manufacturing
Jun 06, 2024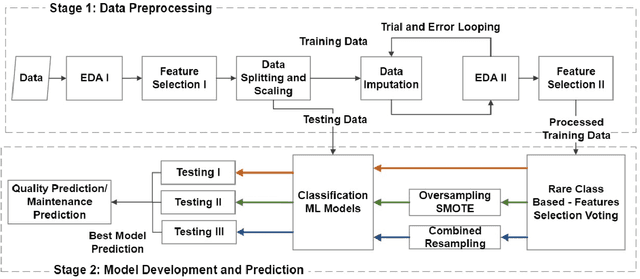
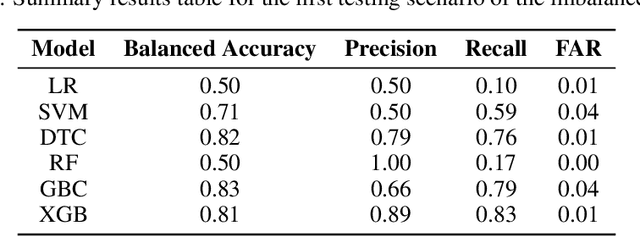
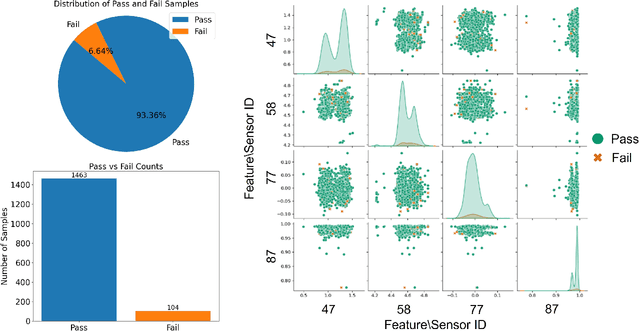
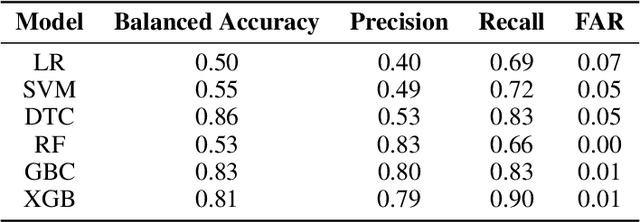
The evolution of industry has enabled the integration of physical and digital systems, facilitating the collection of extensive data on manufacturing processes. This integration provides a reliable solution for improving process quality and managing equipment health. However, data collected from real manufacturing processes often exhibit challenging properties, such as severe class imbalance, high rates of missing values, and noisy features, which hinder effective machine learning implementation. In this study, a rare class prediction approach is developed for in situ data collected from a smart semiconductor manufacturing process. The primary objective is to build a model that addresses issues of noise and class imbalance, enhancing class separation. The developed approach demonstrated promising results compared to existing literature, which would allow the prediction of new observations that could give insights into future maintenance plans and production quality. The model was evaluated using various performance metrics, with ROC curves showing an AUC of 0.95, a precision of 0.66, and a recall of 0.96
GAMedX: Generative AI-based Medical Entity Data Extractor Using Large Language Models
May 31, 2024



In the rapidly evolving field of healthcare and beyond, the integration of generative AI in Electronic Health Records (EHRs) represents a pivotal advancement, addressing a critical gap in current information extraction techniques. This paper introduces GAMedX, a Named Entity Recognition (NER) approach utilizing Large Language Models (LLMs) to efficiently extract entities from medical narratives and unstructured text generated throughout various phases of the patient hospital visit. By addressing the significant challenge of processing unstructured medical text, GAMedX leverages the capabilities of generative AI and LLMs for improved data extraction. Employing a unified approach, the methodology integrates open-source LLMs for NER, utilizing chained prompts and Pydantic schemas for structured output to navigate the complexities of specialized medical jargon. The findings reveal significant ROUGE F1 score on one of the evaluation datasets with an accuracy of 98\%. This innovation enhances entity extraction, offering a scalable, cost-effective solution for automated forms filling from unstructured data. As a result, GAMedX streamlines the processing of unstructured narratives, and sets a new standard in NER applications, contributing significantly to theoretical and practical advancements beyond the medical technology sphere.