 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQPoser: Quantized Explicit Pose Prior Modeling for Controllable Pose Generation
Dec 02, 2023Explicit pose prior models compress human poses into latent representations for using in pose-related downstream tasks. A desirable explicit pose prior model should satisfy three desirable abilities: 1) correctness, i.e. ensuring to generate physically possible poses; 2) expressiveness, i.e. ensuring to preserve details in generation; 3) controllability, meaning that generation from reference poses and explicit instructions should be convenient. Existing explicit pose prior models fail to achieve all of three properties, in special controllability. To break this situation, we propose QPoser, a highly controllable explicit pose prior model which guarantees correctness and expressiveness. In QPoser, a multi-head vector quantized autoencoder (MS-VQVAE) is proposed for obtaining expressive and distributed pose representations. Furthermore, a global-local feature integration mechanism (GLIF-AE) is utilized to disentangle the latent representation and integrate full-body information into local-joint features. Experimental results show that QPoser significantly outperforms state-of-the-art approaches in representing expressive and correct poses, meanwhile is easily to be used for detailed conditional generation from reference poses and prompting instructions.
Generating by Understanding: Neural Visual Generation with Logical Symbol Groundings
Oct 26, 2023



Despite the great success of neural visual generative models in recent years, integrating them with strong symbolic knowledge reasoning systems remains a challenging task. The main challenges are two-fold: one is symbol assignment, i.e. bonding latent factors of neural visual generators with meaningful symbols from knowledge reasoning systems. Another is rule learning, i.e. learning new rules, which govern the generative process of the data, to augment the knowledge reasoning systems. To deal with these symbol grounding problems, we propose a neural-symbolic learning approach, Abductive Visual Generation (AbdGen), for integrating logic programming systems with neural visual generative models based on the abductive learning framework. To achieve reliable and efficient symbol assignment, the quantized abduction method is introduced for generating abduction proposals by the nearest-neighbor lookups within semantic codebooks. To achieve precise rule learning, the contrastive meta-abduction method is proposed to eliminate wrong rules with positive cases and avoid less-informative rules with negative cases simultaneously. Experimental results on various benchmark datasets show that compared to the baselines, AbdGen requires significantly fewer instance-level labeling information for symbol assignment. Furthermore, our approach can effectively learn underlying logical generative rules from data, which is out of the capability of existing approaches.
BEDRF: Bidirectional Edge Diffraction Response Function for Interactive Sound Propagation
Jun 03, 2023We introduce bidirectional edge diffraction response function (BEDRF), a new approach to model wave diffraction around edges with path tracing. The diffraction part of the wave is expressed as an integration on path space, and the wave-edge interaction is expressed using only the localized information around points on the edge similar to a bidirectional scattering distribution function (BSDF) for visual rendering. For an infinite single wedge, our model generates the same result as the analytic solution. Our approach can be easily integrated into interactive geometric sound propagation algorithms that use path tracing to compute specular and diffuse reflections. Our resulting propagation algorithm can approximate complex wave propagation phenomena involving high-order diffraction, and is able to handle dynamic, deformable objects and moving sources and listeners. We highlight the performance of our approach in different scenarios to generate smooth auralization.
A Psychoacoustic Quality Criterion for Path-Traced Sound Propagation
Feb 03, 2022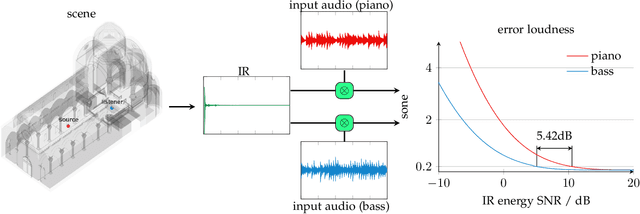
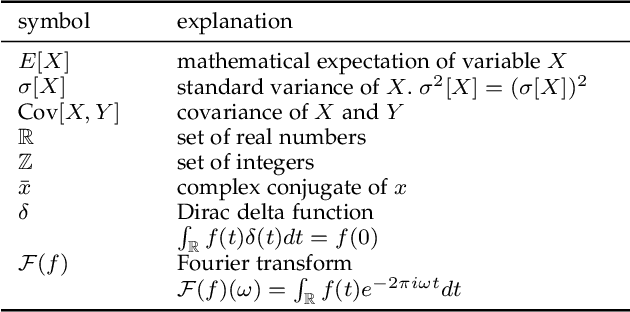
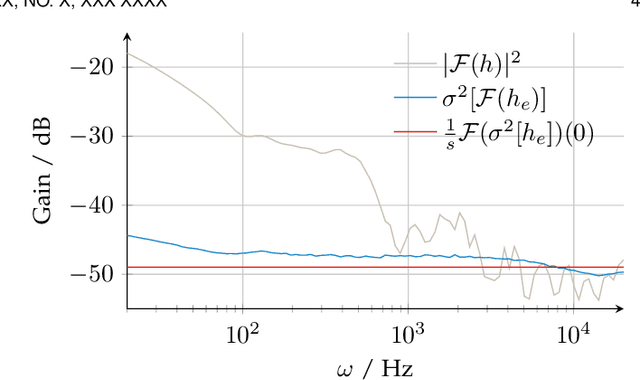

In developing virtual acoustic environments, it is important to understand the relationship between the computation cost and the perceptual significance of the resultant numerical error. In this paper, we propose a quality criterion that evaluates the error significance of path-tracing-based sound propagation simulators. We present an analytical formula that estimates the error signal power spectrum. With this spectrum estimation, we can use a modified Zwicker's loudness model to calculate the relative loudness of the error signal masked by the ideal output. Our experimental results show that the proposed criterion can explain the human perception of simulation error in a variety of cases.