 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Recovery of Non-Random Missing Multidimensional Time Series via Temporal Isometric Delay-Embedding Transform
Dec 11, 2025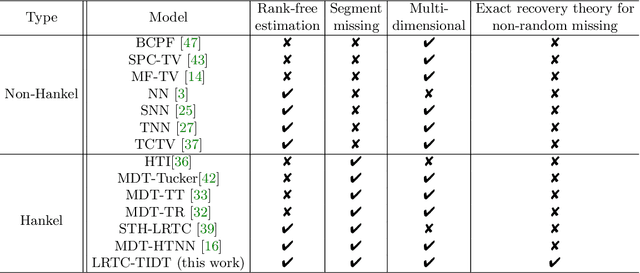
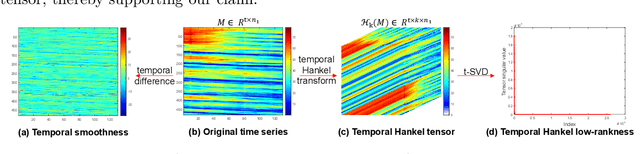
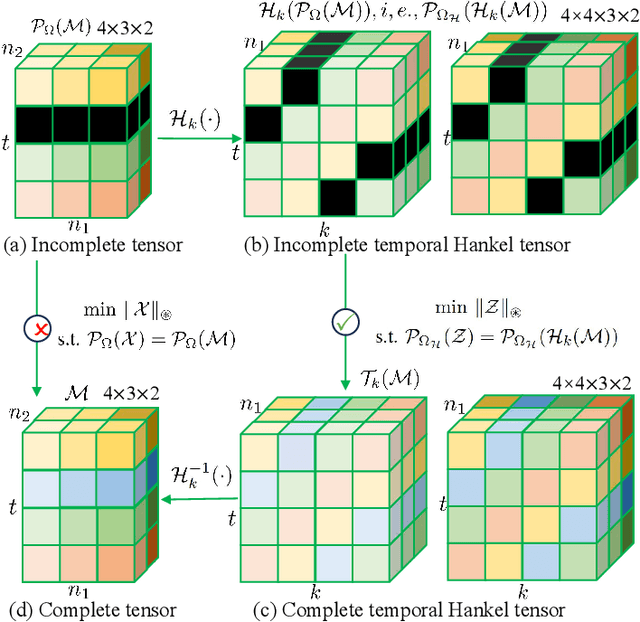
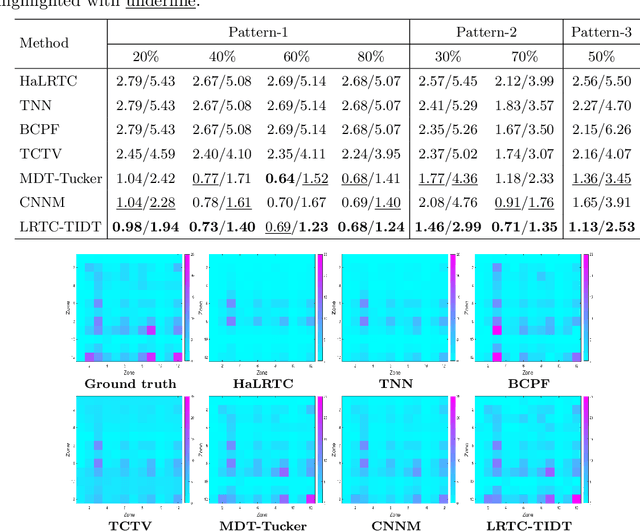
Non-random missing data is a ubiquitous yet undertreated flaw in multidimensional time series, fundamentally threatening the reliability of data-driven analysis and decision-making. Pure low-rank tensor completion, as a classical data recovery method, falls short in handling non-random missingness, both methodologically and theoretically. Hankel-structured tensor completion models provide a feasible approach for recovering multidimensional time series with non-random missing patterns. However, most Hankel-based multidimensional data recovery methods both suffer from unclear sources of Hankel tensor low-rankness and lack an exact recovery theory for non-random missing data. To address these issues, we propose the temporal isometric delay-embedding transform, which constructs a Hankel tensor whose low-rankness is naturally induced by the smoothness and periodicity of the underlying time series. Leveraging this property, we develop the \textit{Low-Rank Tensor Completion with Temporal Isometric Delay-embedding Transform} (LRTC-TIDT) model, which characterizes the low-rank structure under the \textit{Tensor Singular Value Decomposition} (t-SVD) framework. Once the prescribed non-random sampling conditions and mild incoherence assumptions are satisfied, the proposed LRTC-TIDT model achieves exact recovery, as confirmed by simulation experiments under various non-random missing patterns. Furthermore, LRTC-TIDT consistently outperforms existing tensor-based methods across multiple real-world tasks, including network flow reconstruction, urban traffic estimation, and temperature field prediction. Our implementation is publicly available at https://github.com/HaoShu2000/LRTC-TIDT.
Guaranteed Multidimensional Time Series Prediction via Deterministic Tensor Completion Theory
Jan 26, 2025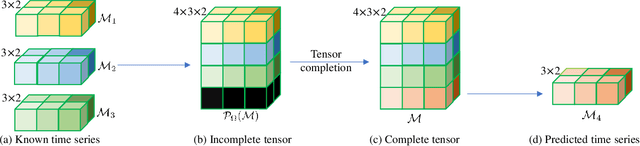



In recent years, the prediction of multidimensional time series data has become increasingly important due to its wide-ranging applications. Tensor-based prediction methods have gained attention for their ability to preserve the inherent structure of such data. However, existing approaches, such as tensor autoregression and tensor decomposition, often have consistently failed to provide clear assertions regarding the number of samples that can be exactly predicted. While matrix-based methods using nuclear norms address this limitation, their reliance on matrices limits accuracy and increases computational costs when handling multidimensional data. To overcome these challenges, we reformulate multidimensional time series prediction as a deterministic tensor completion problem and propose a novel theoretical framework. Specifically, we develop a deterministic tensor completion theory and introduce the Temporal Convolutional Tensor Nuclear Norm (TCTNN) model. By convolving the multidimensional time series along the temporal dimension and applying the tensor nuclear norm, our approach identifies the maximum forecast horizon for exact predictions. Additionally, TCTNN achieves superior performance in prediction accuracy and computational efficiency compared to existing methods across diverse real-world datasets, including climate temperature, network flow, and traffic ride data. Our implementation is publicly available at https://github.com/HaoShu2000/TCTNN.
MMASD+: A Novel Dataset for Privacy-Preserving Behavior Analysis of Children with Autism Spectrum Disorder
Aug 27, 2024Autism spectrum disorder (ASD) is characterized by significant challenges in social interaction and comprehending communication signals. Recently, therapeutic interventions for ASD have increasingly utilized Deep learning powered-computer vision techniques to monitor individual progress over time. These models are trained on private, non-public datasets from the autism community, creating challenges in comparing results across different models due to privacy-preserving data-sharing issues. This work introduces MMASD+. MMASD+ consists of diverse data modalities, including 3D-Skeleton, 3D Body Mesh, and Optical Flow data. It integrates the capabilities of Yolov8 and Deep SORT algorithms to distinguish between the therapist and children, addressing a significant barrier in the original dataset. Additionally, a Multimodal Transformer framework is proposed to predict 11 action types and the presence of ASD. This framework achieves an accuracy of 95.03% for predicting action types and 96.42% for predicting ASD presence, demonstrating over a 10% improvement compared to models trained on single data modalities. These findings highlight the advantages of integrating multiple data modalities within the Multimodal Transformer framework.
MMASD: A Multimodal Dataset for Autism Intervention Analysis
Jun 16, 2023



Autism spectrum disorder (ASD) is a developmental disorder characterized by significant social communication impairments and difficulties perceiving and presenting communication cues. Machine learning techniques have been broadly adopted to facilitate autism studies and assessments. However, computational models are primarily concentrated on specific analysis and validated on private datasets in the autism community, which limits comparisons across models due to privacy-preserving data sharing complications. This work presents a novel privacy-preserving open-source dataset, MMASD as a MultiModal ASD benchmark dataset, collected from play therapy interventions of children with Autism. MMASD includes data from 32 children with ASD, and 1,315 data samples segmented from over 100 hours of intervention recordings. To promote public access, each data sample consists of four privacy-preserving modalities of data: (1) optical flow, (2) 2D skeleton, (3) 3D skeleton, and (4) clinician ASD evaluation scores of children, e.g., ADOS scores. MMASD aims to assist researchers and therapists in understanding children's cognitive status, monitoring their progress during therapy, and customizing the treatment plan accordingly. It also has inspiration for downstream tasks such as action quality assessment and interpersonal synchrony estimation. MMASD dataset can be easily accessed at https://github.com/Li-Jicheng/MMASD-A-Multimodal-Dataset-for-Autism-Intervention-Analysis.
Pose Uncertainty Aware Movement Synchrony Estimation via Spatial-Temporal Graph Transformer
Aug 01, 2022


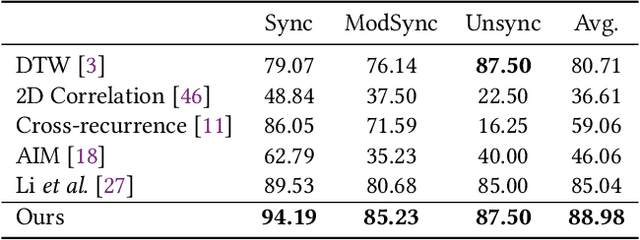
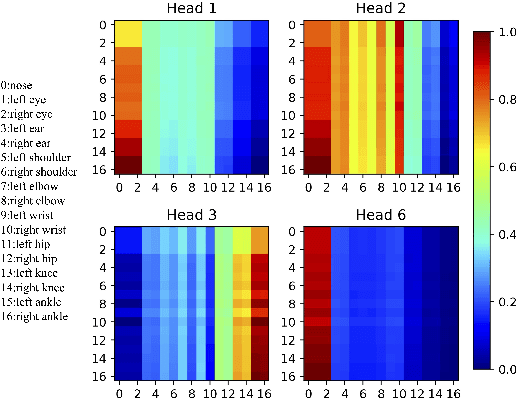
Movement synchrony reflects the coordination of body movements between interacting dyads. The estimation of movement synchrony has been automated by powerful deep learning models such as transformer networks. However, instead of designing a specialized network for movement synchrony estimation, previous transformer-based works broadly adopted architectures from other tasks such as human activity recognition. Therefore, this paper proposed a skeleton-based graph transformer for movement synchrony estimation. The proposed model applied ST-GCN, a spatial-temporal graph convolutional neural network for skeleton feature extraction, followed by a spatial transformer for spatial feature generation. The spatial transformer is guided by a uniquely designed joint position embedding shared between the same joints of interacting individuals. Besides, we incorporated a temporal similarity matrix in temporal attention computation considering the periodic intrinsic of body movements. In addition, the confidence score associated with each joint reflects the uncertainty of a pose, while previous works on movement synchrony estimation have not sufficiently emphasized this point. Since transformer networks demand a significant amount of data to train, we constructed a dataset for movement synchrony estimation using Human3.6M, a benchmark dataset for human activity recognition, and pretrained our model on it using contrastive learning. We further applied knowledge distillation to alleviate information loss introduced by pose detector failure in a privacy-preserving way. We compared our method with representative approaches on PT13, a dataset collected from autism therapy interventions. Our method achieved an overall accuracy of 88.98% and surpassed its counterparts by a wide margin while maintaining data privacy.
Dyadic Movement Synchrony Estimation Under Privacy-preserving Conditions
Aug 01, 2022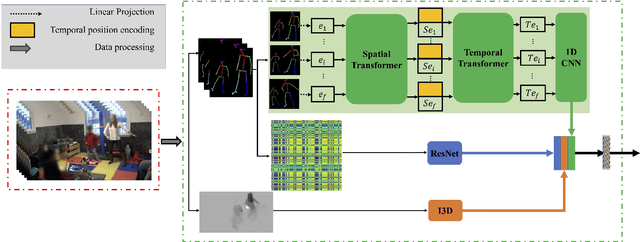

Movement synchrony refers to the dynamic temporal connection between the motions of interacting people. The applications of movement synchrony are wide and broad. For example, as a measure of coordination between teammates, synchrony scores are often reported in sports. The autism community also identifies movement synchrony as a key indicator of children's social and developmental achievements. In general, raw video recordings are often used for movement synchrony estimation, with the drawback that they may reveal people's identities. Furthermore, such privacy concern also hinders data sharing, one major roadblock to a fair comparison between different approaches in autism research. To address the issue, this paper proposes an ensemble method for movement synchrony estimation, one of the first deep-learning-based methods for automatic movement synchrony assessment under privacy-preserving conditions. Our method relies entirely on publicly shareable, identity-agnostic secondary data, such as skeleton data and optical flow. We validate our method on two datasets: (1) PT13 dataset collected from autism therapy interventions and (2) TASD-2 dataset collected from synchronized diving competitions. In this context, our method outperforms its counterpart approaches, both deep neural networks and alternatives.
Mixup Decoding for Diverse Machine Translation
Sep 14, 2021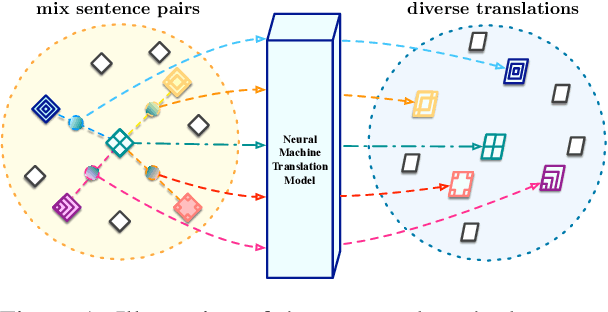

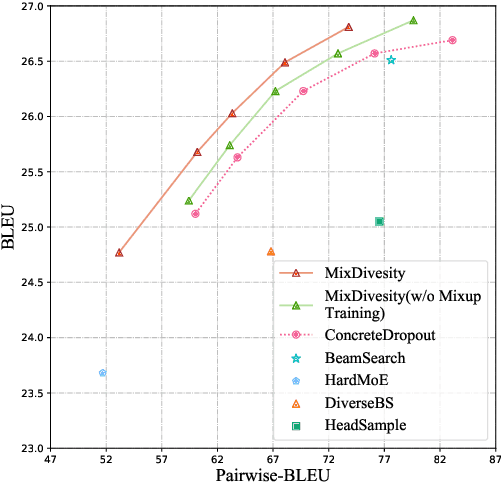
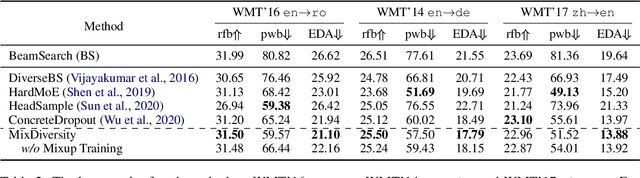
Diverse machine translation aims at generating various target language translations for a given source language sentence. Leveraging the linear relationship in the sentence latent space introduced by the mixup training, we propose a novel method, MixDiversity, to generate different translations for the input sentence by linearly interpolating it with different sentence pairs sampled from the training corpus when decoding. To further improve the faithfulness and diversity of the translations, we propose two simple but effective approaches to select diverse sentence pairs in the training corpus and adjust the interpolation weight for each pair correspondingly. Moreover, by controlling the interpolation weight, our method can achieve the trade-off between faithfulness and diversity without any additional training, which is required in most of the previous methods. Experiments on WMT'16 en-ro, WMT'14 en-de, and WMT'17 zh-en are conducted to show that our method substantially outperforms all previous diverse machine translation methods.
A Two-stage Multi-modal Affect Analysis Framework for Children with Autism Spectrum Disorder
Jun 17, 2021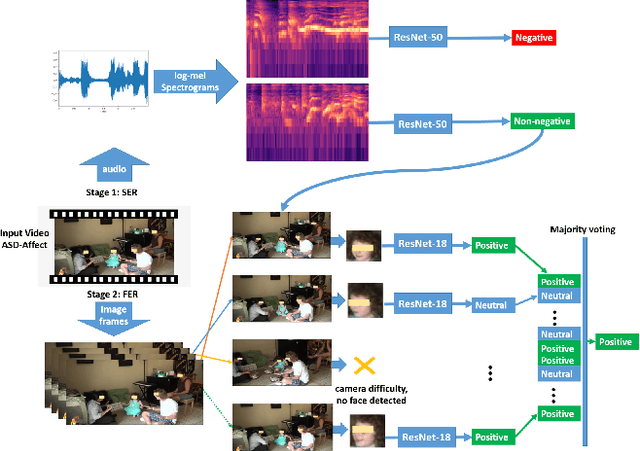

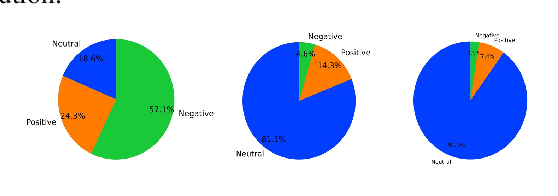
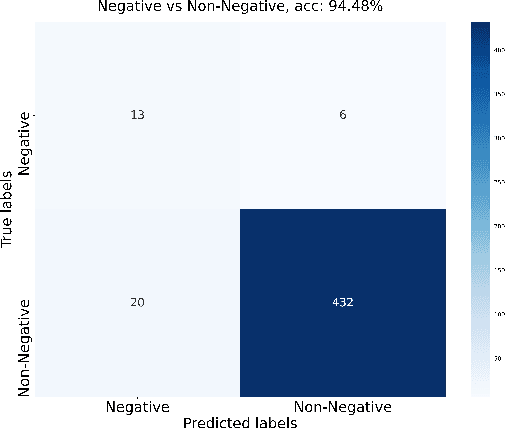
Autism spectrum disorder (ASD) is a developmental disorder that influences the communication and social behavior of a person in a way that those in the spectrum have difficulty in perceiving other people's facial expressions, as well as presenting and communicating emotions and affect via their own faces and bodies. Some efforts have been made to predict and improve children with ASD's affect states in play therapy, a common method to improve children's social skills via play and games. However, many previous works only used pre-trained models on benchmark emotion datasets and failed to consider the distinction in emotion between typically developing children and children with autism. In this paper, we present an open-source two-stage multi-modal approach leveraging acoustic and visual cues to predict three main affect states of children with ASD's affect states (positive, negative, and neutral) in real-world play therapy scenarios, and achieved an overall accuracy of 72:40%. This work presents a novel way to combine human expertise and machine intelligence for ASD affect recognition by proposing a two-stage schema.
* 8 pages including reference; 8 figures
SE-DAE: Style-Enhanced Denoising Auto-Encoder for Unsupervised Text Style Transfer
Apr 27, 2021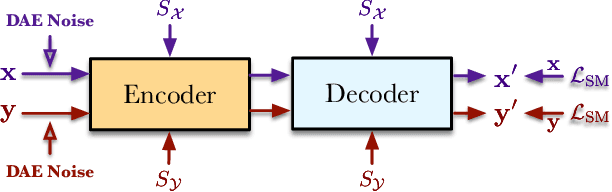
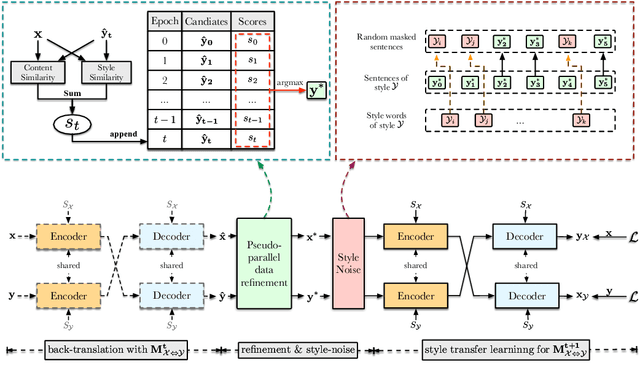
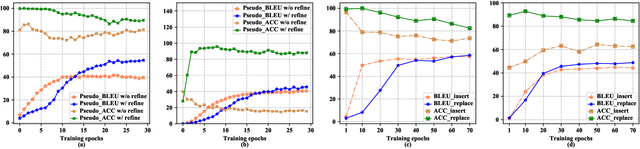
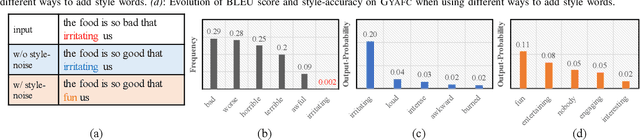
Text style transfer aims to change the style of sentences while preserving the semantic meanings. Due to the lack of parallel data, the Denoising Auto-Encoder (DAE) is widely used in this task to model distributions of different sentence styles. However, because of the conflict between the target of the conventional denoising procedure and the target of style transfer task, the vanilla DAE can not produce satisfying enough results. To improve the transferability of the model, most of the existing works combine DAE with various complicated unsupervised networks, which makes the whole system become over-complex. In this work, we design a novel DAE model named Style-Enhanced DAE (SE-DAE), which is specifically designed for the text style transfer task. Compared with previous complicated style-transfer models, our model do not consist of any complicated unsupervised networks, but only relies on the high-quality pseudo-parallel data generated by a novel data refinement mechanism. Moreover, to alleviate the conflict between the targets of the conventional denoising procedure and the style transfer task, we propose another novel style denoising mechanism, which is more compatible with the target of the style transfer task. We validate the effectiveness of our model on two style benchmark datasets. Both automatic evaluation and human evaluation show that our proposed model is highly competitive compared with previous strong the state of the art (SOTA) approaches and greatly outperforms the vanilla DAE.