 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMASD: A Multimodal Dataset for Autism Intervention Analysis
Jun 16, 2023



Autism spectrum disorder (ASD) is a developmental disorder characterized by significant social communication impairments and difficulties perceiving and presenting communication cues. Machine learning techniques have been broadly adopted to facilitate autism studies and assessments. However, computational models are primarily concentrated on specific analysis and validated on private datasets in the autism community, which limits comparisons across models due to privacy-preserving data sharing complications. This work presents a novel privacy-preserving open-source dataset, MMASD as a MultiModal ASD benchmark dataset, collected from play therapy interventions of children with Autism. MMASD includes data from 32 children with ASD, and 1,315 data samples segmented from over 100 hours of intervention recordings. To promote public access, each data sample consists of four privacy-preserving modalities of data: (1) optical flow, (2) 2D skeleton, (3) 3D skeleton, and (4) clinician ASD evaluation scores of children, e.g., ADOS scores. MMASD aims to assist researchers and therapists in understanding children's cognitive status, monitoring their progress during therapy, and customizing the treatment plan accordingly. It also has inspiration for downstream tasks such as action quality assessment and interpersonal synchrony estimation. MMASD dataset can be easily accessed at https://github.com/Li-Jicheng/MMASD-A-Multimodal-Dataset-for-Autism-Intervention-Analysis.
A Probabilistic Representation of Deep Learning for Improving The Information Theoretic Interpretability
Oct 27, 2020
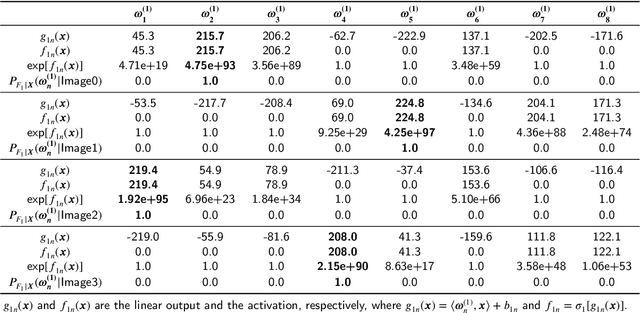
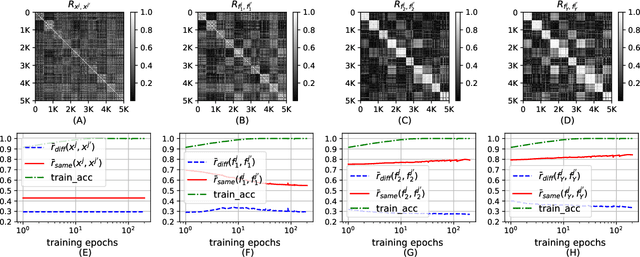

In this paper, we propose a probabilistic representation of MultiLayer Perceptrons (MLPs) to improve the information-theoretic interpretability. Above all, we demonstrate that the activations being i.i.d. is not valid for all the hidden layers of MLPs, thus the existing mutual information estimators based on non-parametric inference methods, e.g., empirical distributions and Kernel Density Estimate (KDE), are invalid for measuring the information flow in MLPs. Moreover, we introduce explicit probabilistic explanations for MLPs: (i) we define the probability space (Omega_F, t, P_F) for a fully connected layer f and demonstrate the great effect of an activation function on the probability measure P_F ; (ii) we prove the entire architecture of MLPs as a Gibbs distribution P; and (iii) the back-propagation aims to optimize the sample space Omega_F of all the fully connected layers of MLPs for learning an optimal Gibbs distribution P* to express the statistical connection between the input and the label. Based on the probabilistic explanations for MLPs, we improve the information-theoretic interpretability of MLPs in three aspects: (i) the random variable of f is discrete and the corresponding entropy is finite; (ii) the information bottleneck theory cannot correctly explain the information flow in MLPs if we take into account the back-propagation; and (iii) we propose novel information-theoretic explanations for the generalization of MLPs. Finally, we demonstrate the proposed probabilistic representation and information-theoretic explanations for MLPs in a synthetic dataset and benchmark datasets.
PAC-Bayesian Generalization Bounds for MultiLayer Perceptrons
Jun 17, 2020
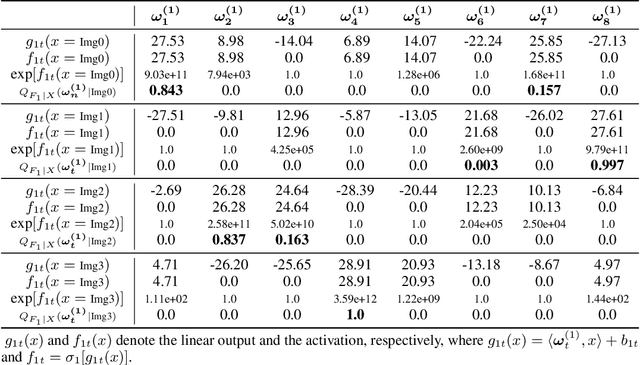


We study PAC-Bayesian generalization bounds for Multilayer Perceptrons (MLPs) with the cross entropy loss. Above all, we introduce probabilistic explanations for MLPs in two aspects: (i) MLPs formulate a family of Gibbs distributions, and (ii) minimizing the cross-entropy loss for MLPs is equivalent to Bayesian variational inference, which establish a solid probabilistic foundation for studying PAC-Bayesian bounds on MLPs. Furthermore, based on the Evidence Lower Bound (ELBO), we prove that MLPs with the cross entropy loss inherently guarantee PAC- Bayesian generalization bounds, and minimizing PAC-Bayesian generalization bounds for MLPs is equivalent to maximizing the ELBO. Finally, we validate the proposed PAC-Bayesian generalization bound on benchmark datasets.
Audio-video Emotion Recognition in the Wild using Deep Hybrid Networks
Feb 20, 2020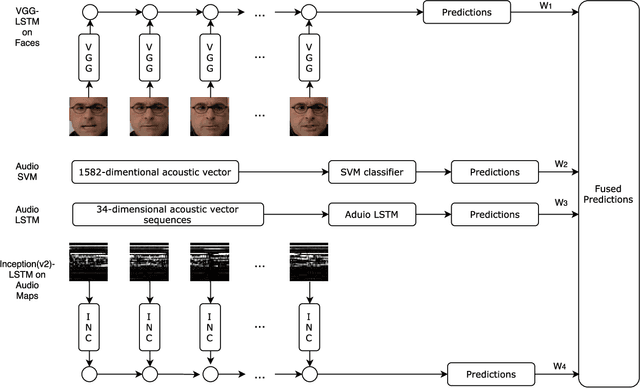
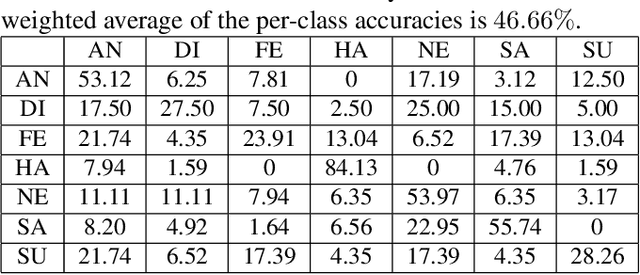
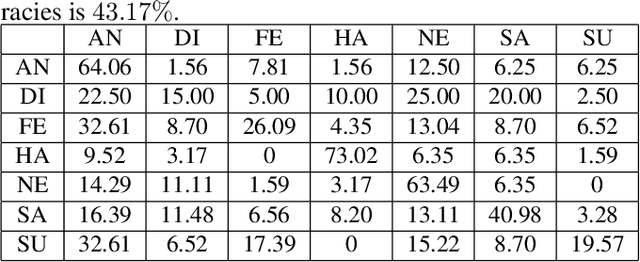
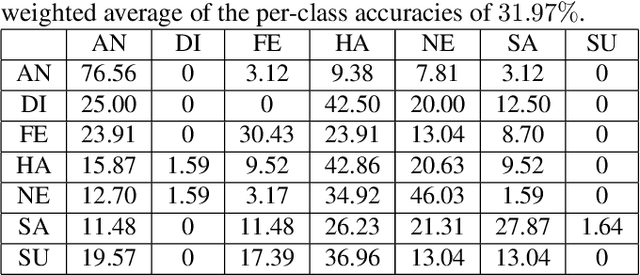
This paper presents an audiovisual-based emotion recognition hybrid network. While most of the previous work focuses either on using deep models or hand-engineered features extracted from images, we explore multiple deep models built on both images and audio signals. Specifically, in addition to convolutional neural networks (CNN) and recurrent neutral networks (RNN) trained on facial images, the hybrid network also contains one SVM classifier trained on holistic acoustic feature vectors, one long short-term memory network (LSTM) trained on short-term feature sequences extracted from segmented audio clips, and one Inception(v2)-LSTM network trained on image-like maps, which are built based on short-term acoustic feature sequences. Experimental results show that the proposed hybrid network outperforms the baseline method by a large margin.
Explicitly Bayesian Regularizations in Deep Learning
Oct 22, 2019



Generalization is essential for deep learning. In contrast to previous works claiming that Deep Neural Networks (DNNs) have an implicit regularization implemented by the stochastic gradient descent, we demonstrate explicitly Bayesian regularizations in a specific category of DNNs, i.e., Convolutional Neural Networks (CNNs). First, we introduce a novel probabilistic representation for the hidden layers of CNNs and demonstrate that CNNs correspond to Bayesian networks with the serial connection. Furthermore, we show that the hidden layers close to the input formulate prior distributions, thus CNNs have explicitly Bayesian regularizations based on the Bayesian regularization theory. In addition, we clarify two recently observed empirical phenomena that are inconsistent with traditional theories of generalization. Finally, we validate the proposed theory on a synthetic dataset
Graph Neural Networks for Image Understanding Based on Multiple Cues: Group Emotion Recognition and Event Recognition as Use Cases
Sep 19, 2019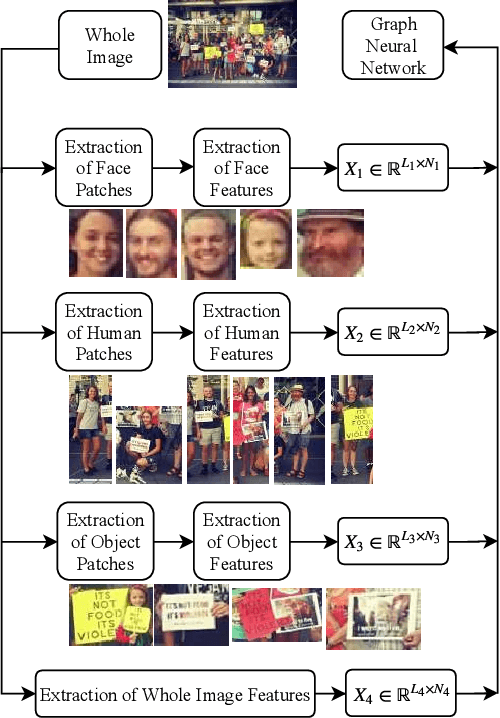
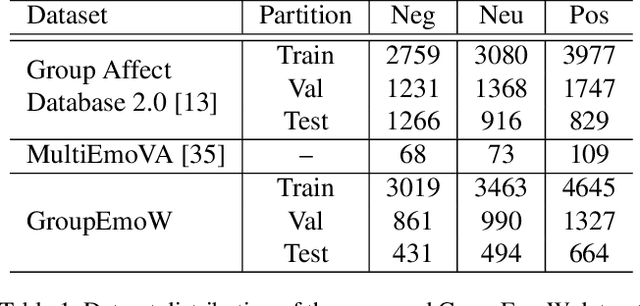
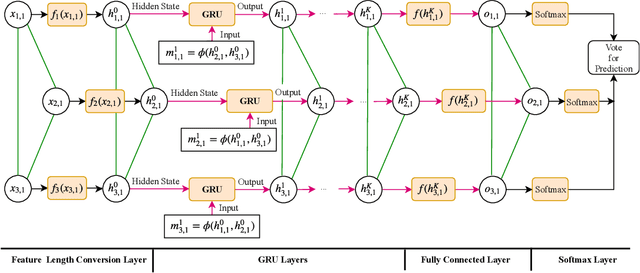
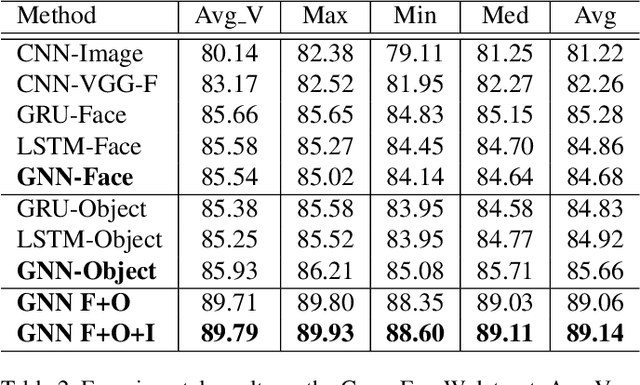
A graph neural network (GNN) for image understanding based on multiple cues is proposed in this paper. Compared to traditional feature and decision fusion approaches that neglect the fact that features can interact and exchange information, the proposed GNN is able to pass information among features extracted from different models. Two image understanding tasks, namely group-level emotion recognition (GER) and event recognition, which are highly semantic and require the interaction of several deep models to synthesize multiple cues, were selected to validate the performance of the proposed method. It is shown through experiments that the proposed method achieves state-of-the-art performance on the selected image understanding tasks. In addition, a new group-level emotion recognition database is introduced and shared in this paper.
A Probabilistic Representation of Deep Learning
Aug 26, 2019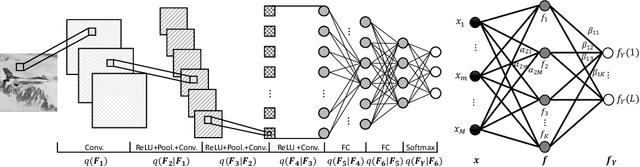
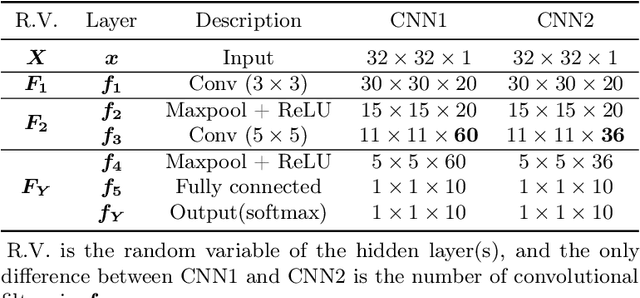
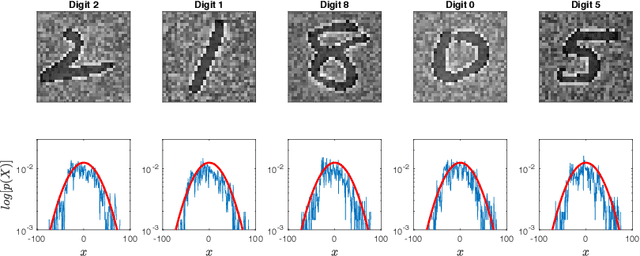
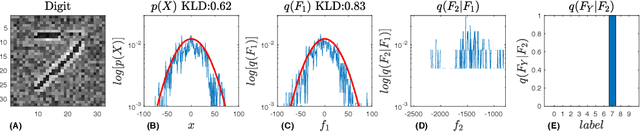
In this work, we introduce a novel probabilistic representation of deep learning, which provides an explicit explanation for the Deep Neural Networks (DNNs) in three aspects: (i) neurons define the energy of a Gibbs distribution; (ii) the hidden layers of DNNs formulate Gibbs distributions; and (iii) the whole architecture of DNNs can be interpreted as a Bayesian neural network. Based on the proposed probabilistic representation, we investigate two fundamental properties of deep learning: hierarchy and generalization. First, we explicitly formulate the hierarchy property from the Bayesian perspective, namely that some hidden layers formulate a prior distribution and the remaining layers formulate a likelihood distribution. Second, we demonstrate that DNNs have an explicit regularization by learning a prior distribution and the learning algorithm is one reason for decreasing the generalization ability of DNNs. Moreover, we clarify two empirical phenomena of DNNs that cannot be explained by traditional theories of generalization. Simulation results validate the proposed probabilistic representation and the insights into these properties of deep learning based on a synthetic dataset.
Smile detection in the wild based on transfer learning
Jan 17, 2018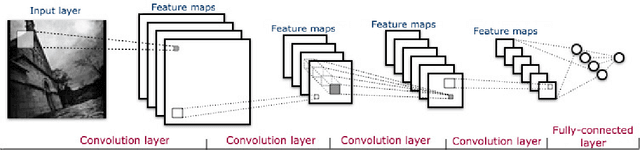
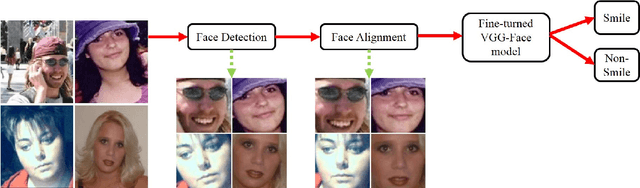

Smile detection from unconstrained facial images is a specialized and challenging problem. As one of the most informative expressions, smiles convey basic underlying emotions, such as happiness and satisfaction, which lead to multiple applications, e.g., human behavior analysis and interactive controlling. Compared to the size of databases for face recognition, far less labeled data is available for training smile detection systems. To leverage the large amount of labeled data from face recognition datasets and to alleviate overfitting on smile detection, an efficient transfer learning-based smile detection approach is proposed in this paper. Unlike previous works which use either hand-engineered features or train deep convolutional networks from scratch, a well-trained deep face recognition model is explored and fine-tuned for smile detection in the wild. Three different models are built as a result of fine-tuning the face recognition model with different inputs, including aligned, unaligned and grayscale images generated from the GENKI-4K dataset. Experiments show that the proposed approach achieves improved state-of-the-art performance. Robustness of the model to noise and blur artifacts is also evaluated in this paper.
Exploiting Restricted Boltzmann Machines and Deep Belief Networks in Compressed Sensing
May 30, 2017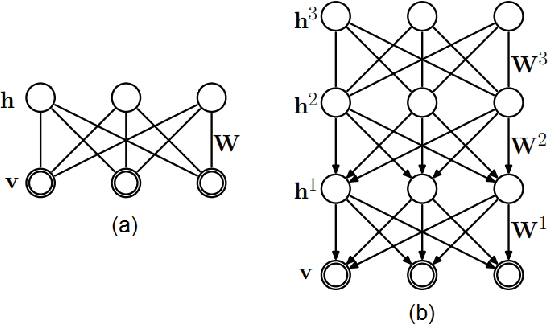
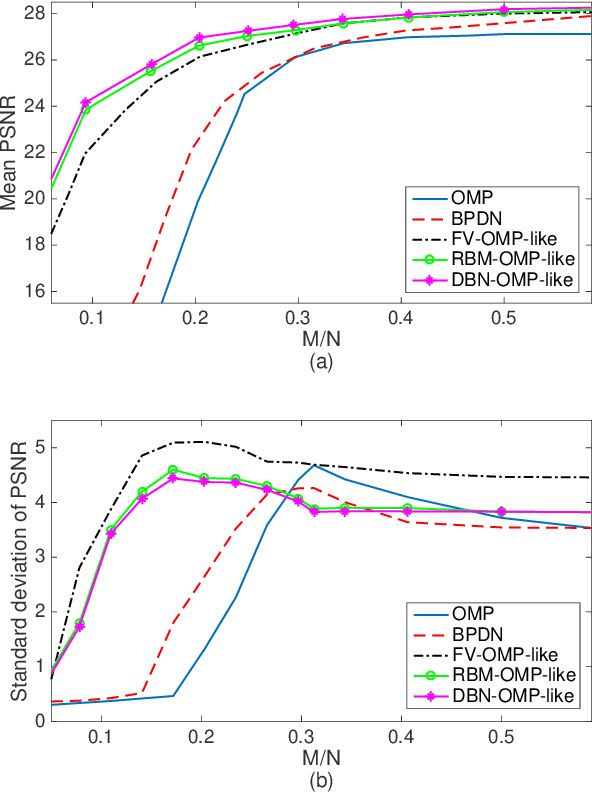

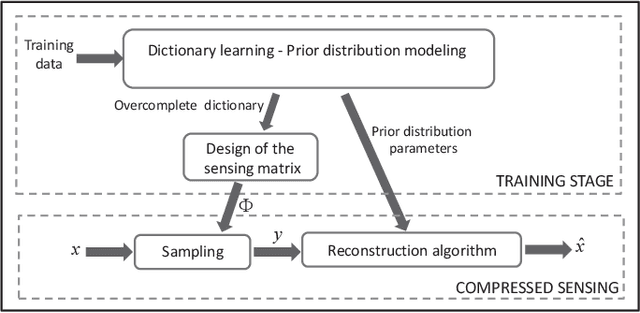
This paper proposes a CS scheme that exploits the representational power of restricted Boltzmann machines and deep learning architectures to model the prior distribution of the sparsity pattern of signals belonging to the same class. The determined probability distribution is then used in a maximum a posteriori (MAP) approach for the reconstruction. The parameters of the prior distribution are learned from training data. The motivation behind this approach is to model the higher-order statistical dependencies between the coefficients of the sparse representation, with the final goal of improving the reconstruction. The performance of the proposed method is validated on the Berkeley Segmentation Dataset and the MNIST Database of handwritten digits.