 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Image to Video: An Empirical Study of Diffusion Representations
Feb 10, 2025Diffusion models have revolutionized generative modeling, enabling unprecedented realism in image and video synthesis. This success has sparked interest in leveraging their representations for visual understanding tasks. While recent works have explored this potential for image generation, the visual understanding capabilities of video diffusion models remain largely uncharted. To address this gap, we systematically compare the same model architecture trained for video versus image generation, analyzing the performance of their latent representations on various downstream tasks including image classification, action recognition, depth estimation, and tracking. Results show that video diffusion models consistently outperform their image counterparts, though we find a striking range in the extent of this superiority. We further analyze features extracted from different layers and with varying noise levels, as well as the effect of model size and training budget on representation and generation quality. This work marks the first direct comparison of video and image diffusion objectives for visual understanding, offering insights into the role of temporal information in representation learning.
Audio-video Emotion Recognition in the Wild using Deep Hybrid Networks
Feb 20, 2020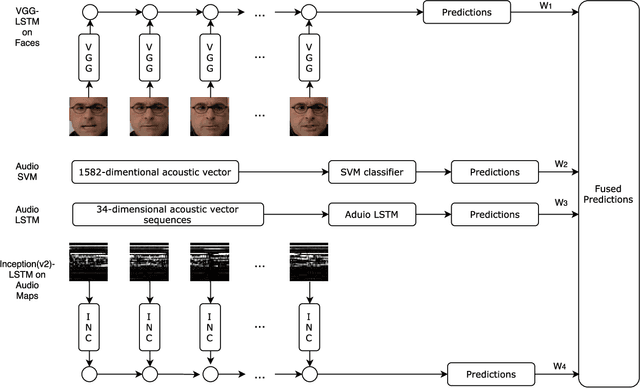
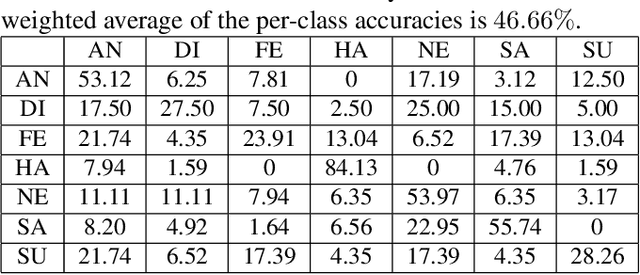
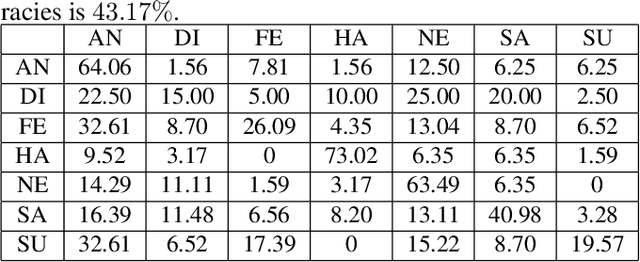
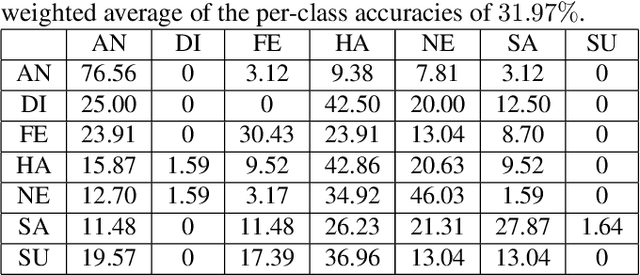
This paper presents an audiovisual-based emotion recognition hybrid network. While most of the previous work focuses either on using deep models or hand-engineered features extracted from images, we explore multiple deep models built on both images and audio signals. Specifically, in addition to convolutional neural networks (CNN) and recurrent neutral networks (RNN) trained on facial images, the hybrid network also contains one SVM classifier trained on holistic acoustic feature vectors, one long short-term memory network (LSTM) trained on short-term feature sequences extracted from segmented audio clips, and one Inception(v2)-LSTM network trained on image-like maps, which are built based on short-term acoustic feature sequences. Experimental results show that the proposed hybrid network outperforms the baseline method by a large margin.
Smile detection in the wild based on transfer learning
Jan 17, 2018
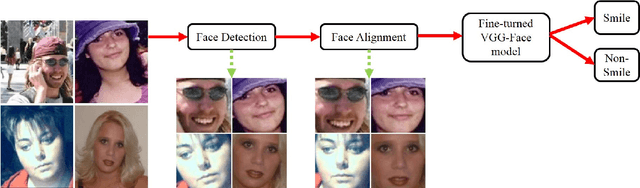

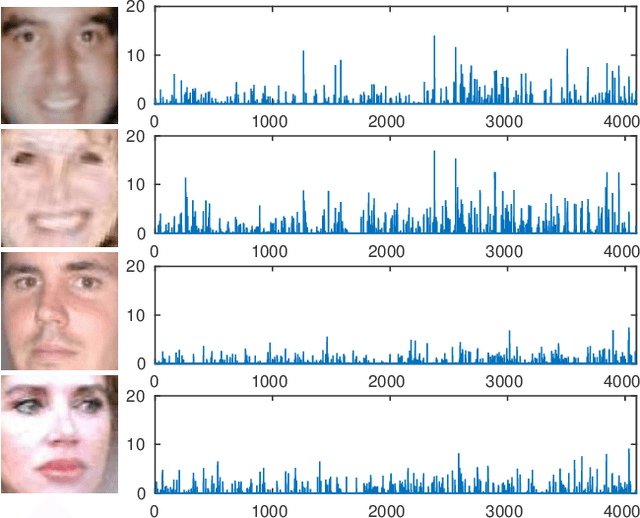
Smile detection from unconstrained facial images is a specialized and challenging problem. As one of the most informative expressions, smiles convey basic underlying emotions, such as happiness and satisfaction, which lead to multiple applications, e.g., human behavior analysis and interactive controlling. Compared to the size of databases for face recognition, far less labeled data is available for training smile detection systems. To leverage the large amount of labeled data from face recognition datasets and to alleviate overfitting on smile detection, an efficient transfer learning-based smile detection approach is proposed in this paper. Unlike previous works which use either hand-engineered features or train deep convolutional networks from scratch, a well-trained deep face recognition model is explored and fine-tuned for smile detection in the wild. Three different models are built as a result of fine-tuning the face recognition model with different inputs, including aligned, unaligned and grayscale images generated from the GENKI-4K dataset. Experiments show that the proposed approach achieves improved state-of-the-art performance. Robustness of the model to noise and blur artifacts is also evaluated in this paper.