 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoCap: Video Object Captioning and Segmentation from Any Prompt
Aug 29, 2025Understanding objects in videos in terms of fine-grained localization masks and detailed semantic properties is a fundamental task in video understanding. In this paper, we propose VoCap, a flexible video model that consumes a video and a prompt of various modalities (text, box or mask), and produces a spatio-temporal masklet with a corresponding object-centric caption. As such our model addresses simultaneously the tasks of promptable video object segmentation, referring expression segmentation, and object captioning. Since obtaining data for this task is tedious and expensive, we propose to annotate an existing large-scale segmentation dataset (SAV) with pseudo object captions. We do so by preprocessing videos with their ground-truth masks to highlight the object of interest and feed this to a large Vision Language Model (VLM). For an unbiased evaluation, we collect manual annotations on the validation set. We call the resulting dataset SAV-Caption. We train our VoCap model at scale on a SAV-Caption together with a mix of other image and video datasets. Our model yields state-of-the-art results on referring expression video object segmentation, is competitive on semi-supervised video object segmentation, and establishes a benchmark for video object captioning. Our dataset will be made available at https://github.com/google-deepmind/vocap.
Progressive Data Dropout: An Embarrassingly Simple Approach to Faster Training
May 28, 2025The success of the machine learning field has reliably depended on training on large datasets. While effective, this trend comes at an extraordinary cost. This is due to two deeply intertwined factors: the size of models and the size of datasets. While promising research efforts focus on reducing the size of models, the other half of the equation remains fairly mysterious. Indeed, it is surprising that the standard approach to training remains to iterate over and over, uniformly sampling the training dataset. In this paper we explore a series of alternative training paradigms that leverage insights from hard-data-mining and dropout, simple enough to implement and use that can become the new training standard. The proposed Progressive Data Dropout reduces the number of effective epochs to as little as 12.4% of the baseline. This savings actually do not come at any cost for accuracy. Surprisingly, the proposed method improves accuracy by up to 4.82%. Our approach requires no changes to model architecture or optimizer, and can be applied across standard training pipelines, thus posing an excellent opportunity for wide adoption. Code can be found here: https://github.com/bazyagami/LearningWithRevision
What Are You Doing? A Closer Look at Controllable Human Video Generation
Mar 06, 2025
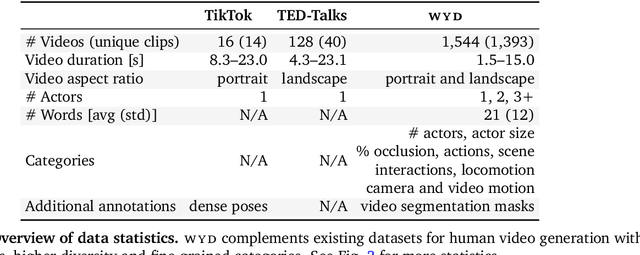
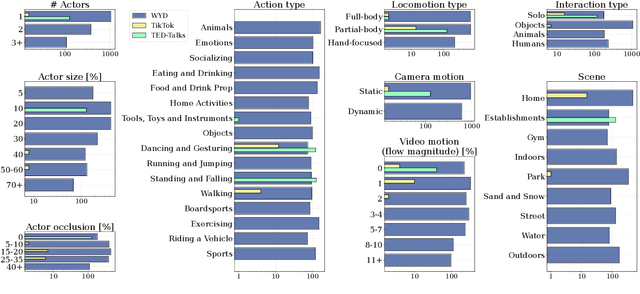
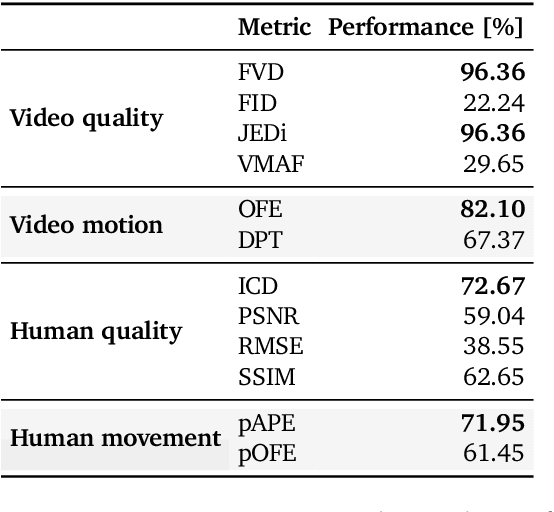
High-quality benchmarks are crucial for driving progress in machine learning research. However, despite the growing interest in video generation, there is no comprehensive dataset to evaluate human generation. Humans can perform a wide variety of actions and interactions, but existing datasets, like TikTok and TED-Talks, lack the diversity and complexity to fully capture the capabilities of video generation models. We close this gap by introducing `What Are You Doing?' (WYD): a new benchmark for fine-grained evaluation of controllable image-to-video generation of humans. WYD consists of 1{,}544 captioned videos that have been meticulously collected and annotated with 56 fine-grained categories. These allow us to systematically measure performance across 9 aspects of human generation, including actions, interactions and motion. We also propose and validate automatic metrics that leverage our annotations and better capture human evaluations. Equipped with our dataset and metrics, we perform in-depth analyses of seven state-of-the-art models in controllable image-to-video generation, showing how WYD provides novel insights about the capabilities of these models. We release our data and code to drive forward progress in human video generation modeling at https://github.com/google-deepmind/wyd-benchmark.
From Image to Video: An Empirical Study of Diffusion Representations
Feb 10, 2025Diffusion models have revolutionized generative modeling, enabling unprecedented realism in image and video synthesis. This success has sparked interest in leveraging their representations for visual understanding tasks. While recent works have explored this potential for image generation, the visual understanding capabilities of video diffusion models remain largely uncharted. To address this gap, we systematically compare the same model architecture trained for video versus image generation, analyzing the performance of their latent representations on various downstream tasks including image classification, action recognition, depth estimation, and tracking. Results show that video diffusion models consistently outperform their image counterparts, though we find a striking range in the extent of this superiority. We further analyze features extracted from different layers and with varying noise levels, as well as the effect of model size and training budget on representation and generation quality. This work marks the first direct comparison of video and image diffusion objectives for visual understanding, offering insights into the role of temporal information in representation learning.
Principles of Visual Tokens for Efficient Video Understanding
Nov 20, 2024



Video understanding has made huge strides in recent years, relying largely on the power of the transformer architecture. As this architecture is notoriously expensive and video is highly redundant, research into improving efficiency has become particularly relevant. This has led to many creative solutions, including token merging and token selection. While most methods succeed in reducing the cost of the model and maintaining accuracy, an interesting pattern arises: most methods do not outperform the random sampling baseline. In this paper we take a closer look at this phenomenon and make several observations. First, we develop an oracle for the value of tokens which exposes a clear Pareto distribution where most tokens have remarkably low value, and just a few carry most of the perceptual information. Second, we analyze why this oracle is extremely hard to learn, as it does not consistently coincide with visual cues. Third, we observe that easy videos need fewer tokens to maintain accuracy. We build on these and further insights to propose a lightweight video model we call LITE that can select a small number of tokens effectively, outperforming state-of-the-art and existing baselines across datasets (Kinetics400 and Something-Something-V2) in the challenging trade-off of computation (GFLOPs) vs accuracy.
Towards Optimal Adapter Placement for Efficient Transfer Learning
Oct 21, 2024



Parameter-efficient transfer learning (PETL) aims to adapt pre-trained models to new downstream tasks while minimizing the number of fine-tuned parameters. Adapters, a popular approach in PETL, inject additional capacity into existing networks by incorporating low-rank projections, achieving performance comparable to full fine-tuning with significantly fewer parameters. This paper investigates the relationship between the placement of an adapter and its performance. We observe that adapter location within a network significantly impacts its effectiveness, and that the optimal placement is task-dependent. To exploit this observation, we introduce an extended search space of adapter connections, including long-range and recurrent adapters. We demonstrate that even randomly selected adapter placements from this expanded space yield improved results, and that high-performing placements often correlate with high gradient rank. Our findings reveal that a small number of strategically placed adapters can match or exceed the performance of the common baseline of adding adapters in every block, opening a new avenue for research into optimal adapter placement strategies.
Towards Open-Vocabulary Semantic Segmentation Without Semantic Labels
Sep 30, 2024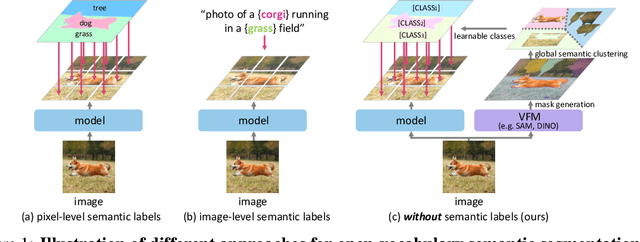
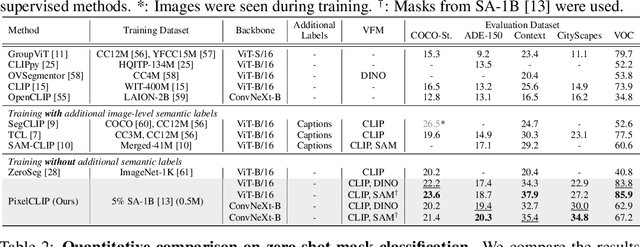

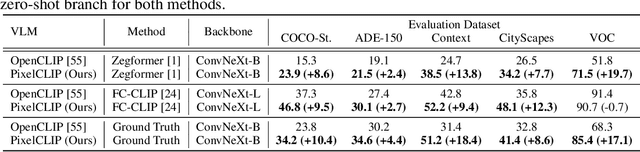
Large-scale vision-language models like CLIP have demonstrated impressive open-vocabulary capabilities for image-level tasks, excelling in recognizing what objects are present. However, they struggle with pixel-level recognition tasks like semantic segmentation, which additionally require understanding where the objects are located. In this work, we propose a novel method, PixelCLIP, to adapt the CLIP image encoder for pixel-level understanding by guiding the model on where, which is achieved using unlabeled images and masks generated from vision foundation models such as SAM and DINO. To address the challenges of leveraging masks without semantic labels, we devise an online clustering algorithm using learnable class names to acquire general semantic concepts. PixelCLIP shows significant performance improvements over CLIP and competitive results compared to caption-supervised methods in open-vocabulary semantic segmentation. Project page is available at https://cvlab-kaist.github.io/PixelCLIP
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
Jul 29, 2024

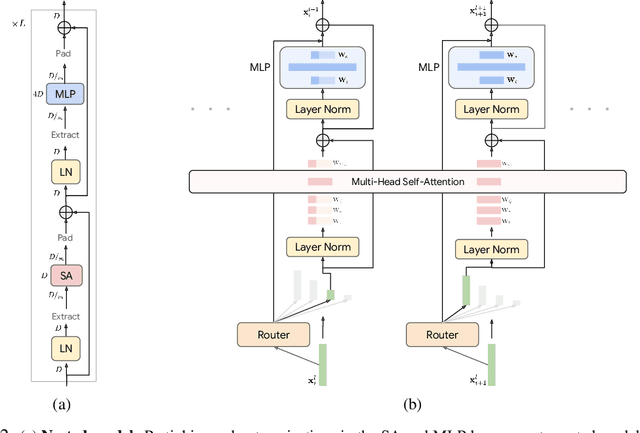
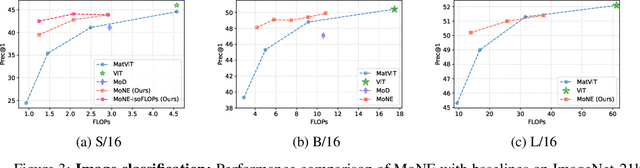
The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing. While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining same inference-time costs, but they come with a larger parameter footprint. We present Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve. Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts. Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets - ImageNet-21K, Kinetics400, and Something-Something-v2. We further highlight MoNE$'$s adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.
Streaming Dense Video Captioning
Apr 01, 2024



An ideal model for dense video captioning -- predicting captions localized temporally in a video -- should be able to handle long input videos, predict rich, detailed textual descriptions, and be able to produce outputs before processing the entire video. Current state-of-the-art models, however, process a fixed number of downsampled frames, and make a single full prediction after seeing the whole video. We propose a streaming dense video captioning model that consists of two novel components: First, we propose a new memory module, based on clustering incoming tokens, which can handle arbitrarily long videos as the memory is of a fixed size. Second, we develop a streaming decoding algorithm that enables our model to make predictions before the entire video has been processed. Our model achieves this streaming ability, and significantly improves the state-of-the-art on three dense video captioning benchmarks: ActivityNet, YouCook2 and ViTT. Our code is released at https://github.com/google-research/scenic.
Time-, Memory- and Parameter-Efficient Visual Adaptation
Feb 05, 2024As foundation models become more popular, there is a growing need to efficiently finetune them for downstream tasks. Although numerous adaptation methods have been proposed, they are designed to be efficient only in terms of how many parameters are trained. They, however, typically still require backpropagating gradients throughout the model, meaning that their training-time and -memory cost does not reduce as significantly. We propose an adaptation method which does not backpropagate gradients through the backbone. We achieve this by designing a lightweight network in parallel that operates on features from the frozen, pretrained backbone. As a result, our method is efficient not only in terms of parameters, but also in training-time and memory usage. Our approach achieves state-of-the-art accuracy-parameter trade-offs on the popular VTAB benchmark, and we further show how we outperform prior works with respect to training-time and -memory usage too. We further demonstrate the training efficiency and scalability of our method by adapting a vision transformer backbone of 4 billion parameters for the computationally demanding task of video classification, without any intricate model parallelism. Here, we outperform a prior adaptor-based method which could only scale to a 1 billion parameter backbone, or fully-finetuning a smaller backbone, with the same GPU and less training time.