 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Streaming Detection of Queried Event Start
Dec 04, 2024



Robotics, autonomous driving, augmented reality, and many embodied computer vision applications must quickly react to user-defined events unfolding in real time. We address this setting by proposing a novel task for multimodal video understanding-Streaming Detection of Queried Event Start (SDQES). The goal of SDQES is to identify the beginning of a complex event as described by a natural language query, with high accuracy and low latency. We introduce a new benchmark based on the Ego4D dataset, as well as new task-specific metrics to study streaming multimodal detection of diverse events in an egocentric video setting. Inspired by parameter-efficient fine-tuning methods in NLP and for video tasks, we propose adapter-based baselines that enable image-to-video transfer learning, allowing for efficient online video modeling. We evaluate three vision-language backbones and three adapter architectures on both short-clip and untrimmed video settings.
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
Jul 29, 2024

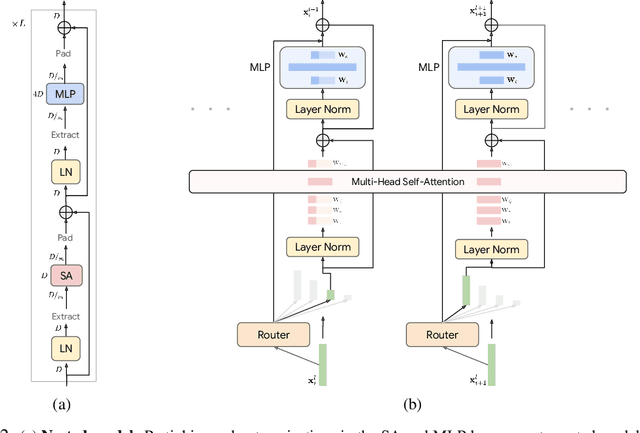
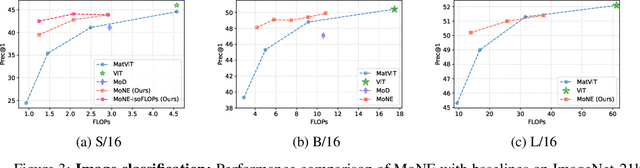
The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing. While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining same inference-time costs, but they come with a larger parameter footprint. We present Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve. Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts. Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets - ImageNet-21K, Kinetics400, and Something-Something-v2. We further highlight MoNE$'$s adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.
MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
Apr 09, 2024This paper addresses the task of video question answering (videoQA) via a decomposed multi-stage, modular reasoning framework. Previous modular methods have shown promise with a single planning stage ungrounded in visual content. However, through a simple and effective baseline, we find that such systems can lead to brittle behavior in practice for challenging videoQA settings. Thus, unlike traditional single-stage planning methods, we propose a multi-stage system consisting of an event parser, a grounding stage, and a final reasoning stage in conjunction with an external memory. All stages are training-free, and performed using few-shot prompting of large models, creating interpretable intermediate outputs at each stage. By decomposing the underlying planning and task complexity, our method, MoReVQA, improves over prior work on standard videoQA benchmarks (NExT-QA, iVQA, EgoSchema, ActivityNet-QA) with state-of-the-art results, and extensions to related tasks (grounded videoQA, paragraph captioning).
Streaming Dense Video Captioning
Apr 01, 2024



An ideal model for dense video captioning -- predicting captions localized temporally in a video -- should be able to handle long input videos, predict rich, detailed textual descriptions, and be able to produce outputs before processing the entire video. Current state-of-the-art models, however, process a fixed number of downsampled frames, and make a single full prediction after seeing the whole video. We propose a streaming dense video captioning model that consists of two novel components: First, we propose a new memory module, based on clustering incoming tokens, which can handle arbitrarily long videos as the memory is of a fixed size. Second, we develop a streaming decoding algorithm that enables our model to make predictions before the entire video has been processed. Our model achieves this streaming ability, and significantly improves the state-of-the-art on three dense video captioning benchmarks: ActivityNet, YouCook2 and ViTT. Our code is released at https://github.com/google-research/scenic.
Revisiting the "Video" in Video-Language Understanding
Jun 03, 2022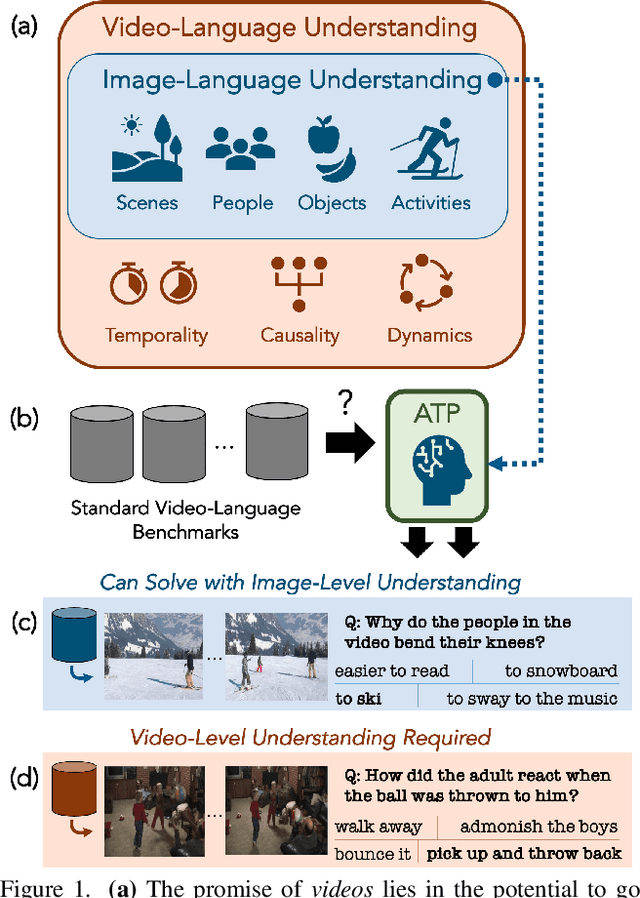



What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments
Aug 06, 2021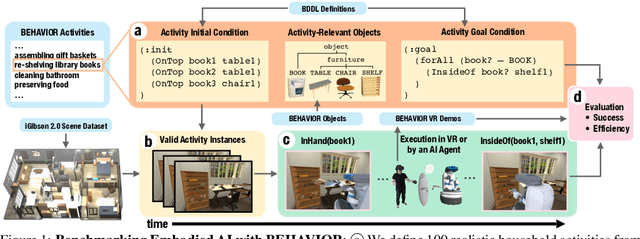
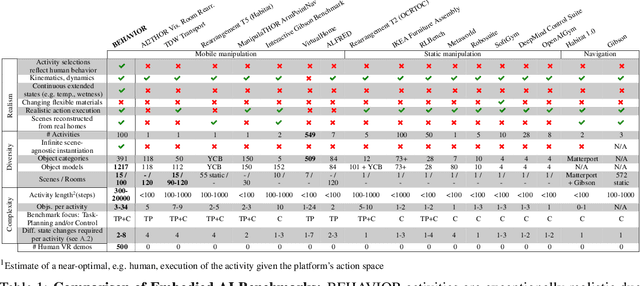

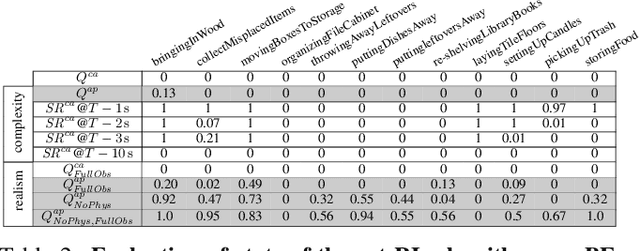
We introduce BEHAVIOR, a benchmark for embodied AI with 100 activities in simulation, spanning a range of everyday household chores such as cleaning, maintenance, and food preparation. These activities are designed to be realistic, diverse, and complex, aiming to reproduce the challenges that agents must face in the real world. Building such a benchmark poses three fundamental difficulties for each activity: definition (it can differ by time, place, or person), instantiation in a simulator, and evaluation. BEHAVIOR addresses these with three innovations. First, we propose an object-centric, predicate logic-based description language for expressing an activity's initial and goal conditions, enabling generation of diverse instances for any activity. Second, we identify the simulator-agnostic features required by an underlying environment to support BEHAVIOR, and demonstrate its realization in one such simulator. Third, we introduce a set of metrics to measure task progress and efficiency, absolute and relative to human demonstrators. We include 500 human demonstrations in virtual reality (VR) to serve as the human ground truth. Our experiments demonstrate that even state of the art embodied AI solutions struggle with the level of realism, diversity, and complexity imposed by the activities in our benchmark. We make BEHAVIOR publicly available at behavior.stanford.edu to facilitate and calibrate the development of new embodied AI solutions.
iGibson, a Simulation Environment for Interactive Tasks in Large Realistic Scenes
Dec 08, 2020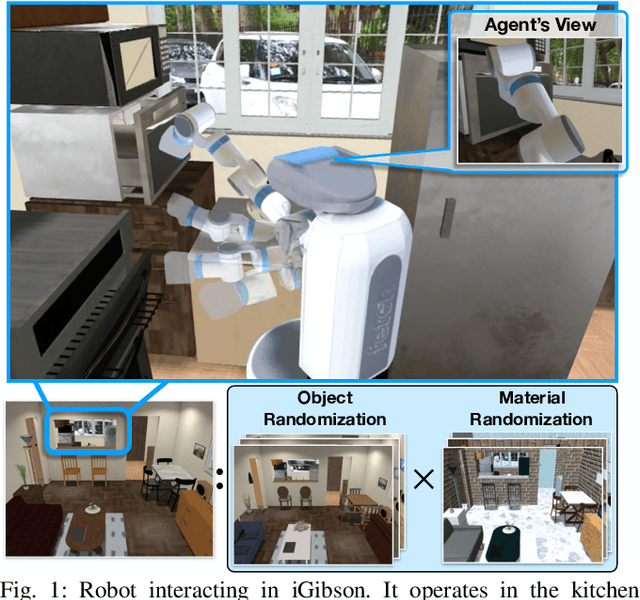
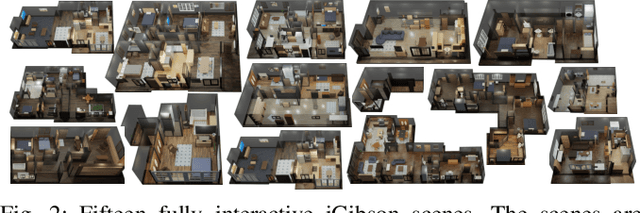


We present iGibson, a novel simulation environment to develop robotic solutions for interactive tasks in large-scale realistic scenes. Our environment contains fifteen fully interactive home-sized scenes populated with rigid and articulated objects. The scenes are replicas of 3D scanned real-world homes, aligning the distribution of objects and layout to that of the real world. iGibson integrates several key features to facilitate the study of interactive tasks: i) generation of high-quality visual virtual sensor signals (RGB, depth, segmentation, LiDAR, flow, among others), ii) domain randomization to change the materials of the objects (both visual texture and dynamics) and/or their shapes, iii) integrated sampling-based motion planners to generate collision-free trajectories for robot bases and arms, and iv) intuitive human-iGibson interface that enables efficient collection of human demonstrations. Through experiments, we show that the full interactivity of the scenes enables agents to learn useful visual representations that accelerate the training of downstream manipulation tasks. We also show that iGibson features enable the generalization of navigation agents, and that the human-iGibson interface and integrated motion planners facilitate efficient imitation learning of simple human demonstrated behaviors. iGibson is open-sourced with comprehensive examples and documentation. For more information, visit our project website: http://svl.stanford.edu/igibson/
The ActivityNet Large-Scale Activity Recognition Challenge 2018 Summary
Aug 23, 2018



The 3rd annual installment of the ActivityNet Large- Scale Activity Recognition Challenge, held as a full-day workshop in CVPR 2018, focused on the recognition of daily life, high-level, goal-oriented activities from user-generated videos as those found in internet video portals. The 2018 challenge hosted six diverse tasks which aimed to push the limits of semantic visual understanding of videos as well as bridge visual content with human captions. Three out of the six tasks were based on the ActivityNet dataset, which was introduced in CVPR 2015 and organized hierarchically in a semantic taxonomy. These tasks focused on tracing evidence of activities in time in the form of proposals, class labels, and captions. In this installment of the challenge, we hosted three guest tasks to enrich the understanding of visual information in videos. The guest tasks focused on complementary aspects of the activity recognition problem at large scale and involved three challenging and recently compiled datasets: the Kinetics-600 dataset from Google DeepMind, the AVA dataset from Berkeley and Google, and the Moments in Time dataset from MIT and IBM Research.