 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelKittens: Systematic and Practical Simplification of Multi-GPU AI Kernels
Nov 17, 2025Inter-GPU communication has become a major bottleneck for modern AI workloads as models scale and improvements in hardware compute throughput outpace improvements in interconnect bandwidth. Existing systems mitigate this through compute-communication overlap but often fail to meet theoretical peak performance across heterogeneous workloads and new accelerators. Instead of operator-specific techniques, we ask whether a small set of simple, reusable principles can systematically guide the design of optimal multi-GPU kernels. We present ParallelKittens (PK), a minimal CUDA framework that drastically simplifies the development of overlapped multi-GPU kernels. PK extends the ThunderKittens framework and embodies the principles of multi-GPU kernel design through eight core primitives and a unified programming template, derived from a comprehensive analysis of the factors that govern multi-GPU performance$\unicode{x2014}$data-transfer mechanisms, resource scheduling, and design overheads. We validate PK on both Hopper and Blackwell architectures. With fewer than 50 lines of device code, PK achieves up to $2.33 \times$ speedup for data- and tensor-parallel workloads, $4.08 \times$ for sequence-parallel workloads, and $1.22 \times$ for expert-parallel workloads.
HipKittens: Fast and Furious AMD Kernels
Nov 11, 2025AMD GPUs offer state-of-the-art compute and memory bandwidth; however, peak performance AMD kernels are written in raw assembly. To address the difficulty of mapping AI algorithms to hardware, recent work proposes C++ embedded and PyTorch-inspired domain-specific languages like ThunderKittens (TK) to simplify high performance AI kernel development on NVIDIA hardware. We explore the extent to which such primitives -- for explicit tile-based programming with optimized memory accesses and fine-grained asynchronous execution across workers -- are NVIDIA-specific or general. We provide the first detailed study of the programming primitives that lead to performant AMD AI kernels, and we encapsulate these insights in the HipKittens (HK) programming framework. We find that tile-based abstractions used in prior DSLs generalize to AMD GPUs, however we need to rethink the algorithms that instantiate these abstractions for AMD. We validate the HK primitives across CDNA3 and CDNA4 AMD platforms. In evaluations, HK kernels compete with AMD's hand-optimized assembly kernels for GEMMs and attention, and consistently outperform compiler baselines. Moreover, assembly is difficult to scale to the breadth of AI workloads; reflecting this, in some settings HK outperforms all available kernel baselines by $1.2-2.4\times$ (e.g., $d=64$ attention, GQA backwards, memory-bound kernels). These findings help pave the way for a single, tile-based software layer for high-performance AI kernels that translates across GPU vendors. HipKittens is released at: https://github.com/HazyResearch/HipKittens.
Cartridges: Lightweight and general-purpose long context representations via self-study
Jun 06, 2025



Large language models are often used to answer queries grounded in large text corpora (e.g. codebases, legal documents, or chat histories) by placing the entire corpus in the context window and leveraging in-context learning (ICL). Although current models support contexts of 100K-1M tokens, this setup is costly to serve because the memory consumption of the KV cache scales with input length. We explore an alternative: training a smaller KV cache offline on each corpus. At inference time, we load this trained KV cache, which we call a Cartridge, and decode a response. Critically, the cost of training a Cartridge can be amortized across all the queries referencing the same corpus. However, we find that the naive approach of training the Cartridge with next-token prediction on the corpus is not competitive with ICL. Instead, we propose self-study, a training recipe in which we generate synthetic conversations about the corpus and train the Cartridge with a context-distillation objective. We find that Cartridges trained with self-study replicate the functionality of ICL, while being significantly cheaper to serve. On challenging long-context benchmarks, Cartridges trained with self-study match ICL performance while using 38.6x less memory and enabling 26.4x higher throughput. Self-study also extends the model's effective context length (e.g. from 128k to 484k tokens on MTOB) and surprisingly, leads to Cartridges that can be composed at inference time without retraining.
Towards Learning High-Precision Least Squares Algorithms with Sequence Models
Mar 15, 2025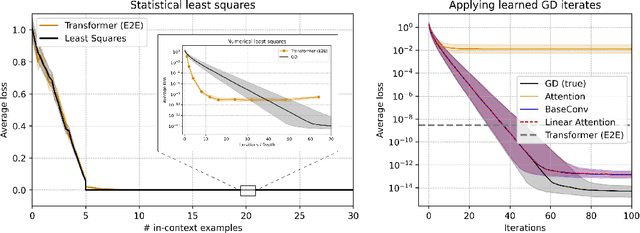

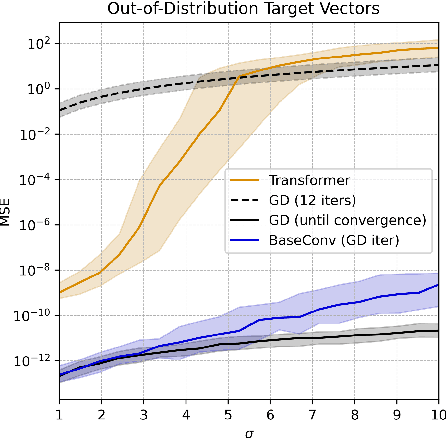
This paper investigates whether sequence models can learn to perform numerical algorithms, e.g. gradient descent, on the fundamental problem of least squares. Our goal is to inherit two properties of standard algorithms from numerical analysis: (1) machine precision, i.e. we want to obtain solutions that are accurate to near floating point error, and (2) numerical generality, i.e. we want them to apply broadly across problem instances. We find that prior approaches using Transformers fail to meet these criteria, and identify limitations present in existing architectures and training procedures. First, we show that softmax Transformers struggle to perform high-precision multiplications, which prevents them from precisely learning numerical algorithms. Second, we identify an alternate class of architectures, comprised entirely of polynomials, that can efficiently represent high-precision gradient descent iterates. Finally, we investigate precision bottlenecks during training and address them via a high-precision training recipe that reduces stochastic gradient noise. Our recipe enables us to train two polynomial architectures, gated convolutions and linear attention, to perform gradient descent iterates on least squares problems. For the first time, we demonstrate the ability to train to near machine precision. Applied iteratively, our models obtain 100,000x lower MSE than standard Transformers trained end-to-end and they incur a 10,000x smaller generalization gap on out-of-distribution problems. We make progress towards end-to-end learning of numerical algorithms for least squares.
ThunderKittens: Simple, Fast, and Adorable AI Kernels
Oct 27, 2024The challenge of mapping AI architectures to GPU hardware is creating a critical bottleneck in AI progress. Despite substantial efforts, hand-written custom kernels fail to meet their theoretical performance thresholds, even on well-established operations like linear attention. The diverse hardware capabilities of GPUs might suggest that we need a wide variety of techniques to achieve high performance. However, our work explores whether a small number of key abstractions can drastically simplify the process. We present ThunderKittens (TK), a framework for writing performant AI kernels while remaining easy to use and maintain. Our abstractions map to the three levels of the GPU hierarchy: (1) at the warp-level, we provide 16x16 matrix tiles as basic data structures and PyTorch-like parallel compute operations over tiles, (2) at the thread-block level, we provide a template for overlapping asynchronous operations across parallel warps, and (3) at the grid-level, we provide support to help hide the block launch and tear-down, and memory costs. We show the value of TK by providing kernels that match or outperform prior kernels for a range of AI operations. We match CuBLAS and FlashAttention-3 on GEMM and attention inference performance and outperform the strongest baselines by $10-40\%$ on attention backwards, $8\times$ on state space models, and $14\times$ on linear attention.
LoLCATs: On Low-Rank Linearizing of Large Language Models
Oct 14, 2024

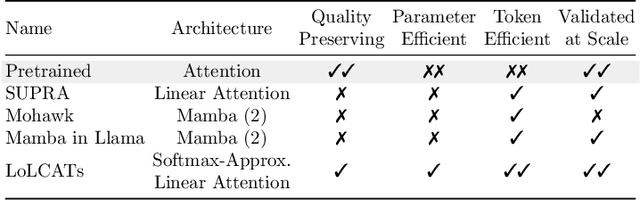

Recent works show we can linearize large language models (LLMs) -- swapping the quadratic attentions of popular Transformer-based LLMs with subquadratic analogs, such as linear attention -- avoiding the expensive pretraining costs. However, linearizing LLMs often significantly degrades model quality, still requires training over billions of tokens, and remains limited to smaller 1.3B to 7B LLMs. We thus propose Low-rank Linear Conversion via Attention Transfer (LoLCATs), a simple two-step method that improves LLM linearizing quality with orders of magnitudes less memory and compute. We base these steps on two findings. First, we can replace an LLM's softmax attentions with closely-approximating linear attentions, simply by training the linear attentions to match their softmax counterparts with an output MSE loss ("attention transfer"). Then, this enables adjusting for approximation errors and recovering LLM quality simply with low-rank adaptation (LoRA). LoLCATs significantly improves linearizing quality, training efficiency, and scalability. We significantly reduce the linearizing quality gap and produce state-of-the-art subquadratic LLMs from Llama 3 8B and Mistral 7B v0.1, leading to 20+ points of improvement on 5-shot MMLU. Furthermore, LoLCATs does so with only 0.2% of past methods' model parameters and 0.4% of their training tokens. Finally, we apply LoLCATs to create the first linearized 70B and 405B LLMs (50x larger than prior work). When compared with prior approaches under the same compute budgets, LoLCATs significantly improves linearizing quality, closing the gap between linearized and original Llama 3.1 70B and 405B LLMs by 77.8% and 78.1% on 5-shot MMLU.
Just read twice: closing the recall gap for recurrent language models
Jul 07, 2024



Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to brittle in-context learning (ICL) quality. A key challenge for efficient LMs is selecting what information to store versus discard. In this work, we observe the order in which information is shown to the LM impacts the selection difficulty. To formalize this, we show that the hardness of information recall reduces to the hardness of a problem called set disjointness (SD), a quintessential problem in communication complexity that requires a streaming algorithm (e.g., recurrent model) to decide whether inputted sets are disjoint. We empirically and theoretically show that the recurrent memory required to solve SD changes with set order, i.e., whether the smaller set appears first in-context. Our analysis suggests, to mitigate the reliance on data order, we can put information in the right order in-context or process prompts non-causally. Towards that end, we propose: (1) JRT-Prompt, where context gets repeated multiple times in the prompt, effectively showing the model all data orders. This gives $11.0 \pm 1.3$ points of improvement, averaged across $16$ recurrent LMs and the $6$ ICL tasks, with $11.9\times$ higher throughput than FlashAttention-2 for generation prefill (length $32$k, batch size $16$, NVidia H100). We then propose (2) JRT-RNN, which uses non-causal prefix-linear-attention to process prompts and provides $99\%$ of Transformer quality at $360$M params., $30$B tokens and $96\%$ at $1.3$B params., $50$B tokens on average across the tasks, with $19.2\times$ higher throughput for prefill than FA2.
Optimistic Verifiable Training by Controlling Hardware Nondeterminism
Mar 16, 2024



The increasing compute demands of AI systems has led to the emergence of services that train models on behalf of clients lacking necessary resources. However, ensuring correctness of training and guarding against potential training-time attacks, such as data poisoning, poses challenges. Existing works on verifiable training largely fall into two classes: proof-based systems, which struggle to scale due to requiring cryptographic techniques, and "optimistic" methods that consider a trusted third-party auditor who replicates the training process. A key challenge with the latter is that hardware nondeterminism between GPU types during training prevents an auditor from replicating the training process exactly, and such schemes are therefore non-robust. We propose a method that combines training in a higher precision than the target model, rounding after intermediate computation steps, and storing rounding decisions based on an adaptive thresholding procedure, to successfully control for nondeterminism. Across three different NVIDIA GPUs (A40, Titan XP, RTX 2080 Ti), we achieve exact training replication at FP32 precision for both full-training and fine-tuning of ResNet-50 (23M) and GPT-2 (117M) models. Our verifiable training scheme significantly decreases the storage and time costs compared to proof-based systems.
Simple linear attention language models balance the recall-throughput tradeoff
Feb 28, 2024



Recent work has shown that attention-based language models excel at recall, the ability to ground generations in tokens previously seen in context. However, the efficiency of attention-based models is bottle-necked during inference by the KV-cache's aggressive memory consumption. In this work, we explore whether we can improve language model efficiency (e.g. by reducing memory consumption) without compromising on recall. By applying experiments and theory to a broad set of architectures, we identify a key tradeoff between a model's state size and recall ability. We show that efficient alternatives to attention (e.g. H3, Mamba, RWKV) maintain a fixed-size recurrent state, but struggle at recall. We propose BASED a simple architecture combining linear and sliding window attention. By varying BASED window size and linear attention feature dimension, we can dial the state size and traverse the pareto frontier of the recall-memory tradeoff curve, recovering the full quality of attention on one end and the small state size of attention-alternatives on the other. We train language models up to 1.3b parameters and show that BASED matches the strongest sub-quadratic models (e.g. Mamba) in perplexity and outperforms them on real-world recall-intensive tasks by 6.22 accuracy points. Implementations of linear attention are often less efficient than optimized standard attention implementations. To make BASED competitive, we develop IO-aware algorithms that enable 24x higher throughput on language generation than FlashAttention-2, when generating 1024 tokens using 1.3b parameter models. Code for this work is provided at: https://github.com/HazyResearch/based.
Benchmarking and Building Long-Context Retrieval Models with LoCo and M2-BERT
Feb 14, 2024Retrieval pipelines-an integral component of many machine learning systems-perform poorly in domains where documents are long (e.g., 10K tokens or more) and where identifying the relevant document requires synthesizing information across the entire text. Developing long-context retrieval encoders suitable for these domains raises three challenges: (1) how to evaluate long-context retrieval performance, (2) how to pretrain a base language model to represent both short contexts (corresponding to queries) and long contexts (corresponding to documents), and (3) how to fine-tune this model for retrieval under the batch size limitations imposed by GPU memory constraints. To address these challenges, we first introduce LoCoV1, a novel 12 task benchmark constructed to measure long-context retrieval where chunking is not possible or not effective. We next present the M2-BERT retrieval encoder, an 80M parameter state-space encoder model built from the Monarch Mixer architecture, capable of scaling to documents up to 32K tokens long. We describe a pretraining data mixture which allows this encoder to process both short and long context sequences, and a finetuning approach that adapts this base model to retrieval with only single-sample batches. Finally, we validate the M2-BERT retrieval encoder on LoCoV1, finding that it outperforms competitive Transformer-based models by at least 23.3 points, despite containing upwards of 90x fewer parameters.