 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Evaluation of Cost-Aware PoQ for Decentralized LLM Inference
Dec 18, 2025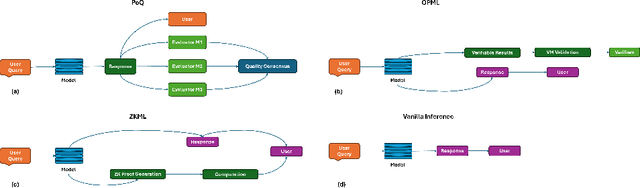



Decentralized large language model (LLM) inference promises transparent and censorship resistant access to advanced AI, yet existing verification approaches struggle to scale to modern models. Proof of Quality (PoQ) replaces cryptographic verification of computation with consensus over output quality, but the original formulation ignores heterogeneous computational costs across inference and evaluator nodes. This paper introduces a cost-aware PoQ framework that integrates explicit efficiency measurements into the reward mechanism for both types of nodes. The design combines ground truth token level F1, lightweight learned evaluators, and GPT based judgments within a unified evaluation pipeline, and adopts a linear reward function that balances normalized quality and cost. Experiments on extractive question answering and abstractive summarization use five instruction tuned LLMs ranging from TinyLlama-1.1B to Llama-3.2-3B and three evaluation models spanning cross encoder and bi encoder architectures. Results show that a semantic textual similarity bi encoder achieves much higher correlation with both ground truth and GPT scores than cross encoders, indicating that evaluator architecture is a critical design choice for PoQ. Quality-cost analysis further reveals that the largest models in the pool are also the most efficient in terms of quality per unit latency. Monte Carlo simulations over 5\,000 PoQ rounds demonstrate that the cost-aware reward scheme consistently assigns higher average rewards to high quality low cost inference models and to efficient evaluators, while penalizing slow low quality nodes. These findings suggest that cost-aware PoQ provides a practical foundation for economically sustainable decentralized LLM inference.
LoLCATs: On Low-Rank Linearizing of Large Language Models
Oct 14, 2024

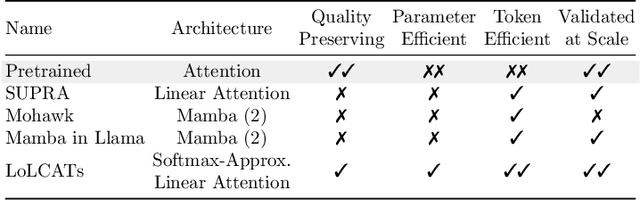

Recent works show we can linearize large language models (LLMs) -- swapping the quadratic attentions of popular Transformer-based LLMs with subquadratic analogs, such as linear attention -- avoiding the expensive pretraining costs. However, linearizing LLMs often significantly degrades model quality, still requires training over billions of tokens, and remains limited to smaller 1.3B to 7B LLMs. We thus propose Low-rank Linear Conversion via Attention Transfer (LoLCATs), a simple two-step method that improves LLM linearizing quality with orders of magnitudes less memory and compute. We base these steps on two findings. First, we can replace an LLM's softmax attentions with closely-approximating linear attentions, simply by training the linear attentions to match their softmax counterparts with an output MSE loss ("attention transfer"). Then, this enables adjusting for approximation errors and recovering LLM quality simply with low-rank adaptation (LoRA). LoLCATs significantly improves linearizing quality, training efficiency, and scalability. We significantly reduce the linearizing quality gap and produce state-of-the-art subquadratic LLMs from Llama 3 8B and Mistral 7B v0.1, leading to 20+ points of improvement on 5-shot MMLU. Furthermore, LoLCATs does so with only 0.2% of past methods' model parameters and 0.4% of their training tokens. Finally, we apply LoLCATs to create the first linearized 70B and 405B LLMs (50x larger than prior work). When compared with prior approaches under the same compute budgets, LoLCATs significantly improves linearizing quality, closing the gap between linearized and original Llama 3.1 70B and 405B LLMs by 77.8% and 78.1% on 5-shot MMLU.
End-to-End Conformal Calibration for Optimization Under Uncertainty
Sep 30, 2024



Machine learning can significantly improve performance for decision-making under uncertainty in a wide range of domains. However, ensuring robustness guarantees requires well-calibrated uncertainty estimates, which can be difficult to achieve in high-capacity prediction models such as deep neural networks. Moreover, in high-dimensional settings, there may be many valid uncertainty estimates, each with their own performance profile - i.e., not all uncertainty is equally valuable for downstream decision-making. To address this problem, this paper develops an end-to-end framework to learn the uncertainty estimates for conditional robust optimization, with robustness and calibration guarantees provided by conformal prediction. In addition, we propose to represent arbitrary convex uncertainty sets with partially input-convex neural networks, which are learned as part of our framework. Our approach consistently improves upon two-stage estimate-then-optimize baselines on concrete applications in energy storage arbitrage and portfolio optimization.
Vision-Braille: An End-to-End Tool for Chinese Braille Image-to-Text Translation
Jul 08, 2024


Visually impaired people are a large group who can only use braille for reading and writing. However, the lack of special educational resources is the bottleneck for educating them. Educational equity is a reflection of the level of social civilization, cultural equality, and individual dignity. Facilitating and improving lifelong learning channels for the visually impaired is of great significance. Their written braille homework or exam papers cannot be understood by sighted teachers, because of the lack of a highly accurate braille translation system, especially in Chinese which has tone marks. braille writers often omit tone marks to save space, leading to confusion when braille with the same consonants and vowels is translated into Chinese. Previous algorithms were insufficient in extracting contextual information, resulting in low accuracy of braille translations into Chinese. This project informatively fine-tuned the mT5 model with an Encoder-decoder architecture for braille to Chinese character conversion. This research created a training set of braille and corresponding Chinese text from the Leipzig Corpora. This project significantly reduced the confusion in braille, achieving $62.4$ and $62.3$ BLEU scores in the validation and test sets, with a curriculum learning fine-tuning method. By incorporating the braille recognition algorithm, this project is the first publicly available braille translation system and can benefit lots of visually impaired students and families who are preparing for the Chinese College Test and help to propel their college dreams in the future. There is a demo on our homepage\footnote{\url{https://vision-braille.com/}}.
URDFormer: A Pipeline for Constructing Articulated Simulation Environments from Real-World Images
May 19, 2024



Constructing simulation scenes that are both visually and physically realistic is a problem of practical interest in domains ranging from robotics to computer vision. This problem has become even more relevant as researchers wielding large data-hungry learning methods seek new sources of training data for physical decision-making systems. However, building simulation models is often still done by hand. A graphic designer and a simulation engineer work with predefined assets to construct rich scenes with realistic dynamic and kinematic properties. While this may scale to small numbers of scenes, to achieve the generalization properties that are required for data-driven robotic control, we require a pipeline that is able to synthesize large numbers of realistic scenes, complete with 'natural' kinematic and dynamic structures. To attack this problem, we develop models for inferring structure and generating simulation scenes from natural images, allowing for scalable scene generation from web-scale datasets. To train these image-to-simulation models, we show how controllable text-to-image generative models can be used in generating paired training data that allows for modeling of the inverse problem, mapping from realistic images back to complete scene models. We show how this paradigm allows us to build large datasets of scenes in simulation with semantic and physical realism. We present an integrated end-to-end pipeline that generates simulation scenes complete with articulated kinematic and dynamic structures from real-world images and use these for training robotic control policies. We then robustly deploy in the real world for tasks like articulated object manipulation. In doing so, our work provides both a pipeline for large-scale generation of simulation environments and an integrated system for training robust robotic control policies in the resulting environments.
Deep Representation Learning-Based Dynamic Trajectory Phenotyping for Acute Respiratory Failure in Medical Intensive Care Units
May 04, 2024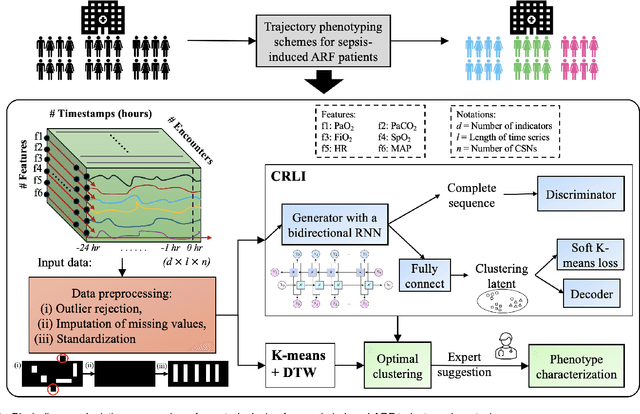
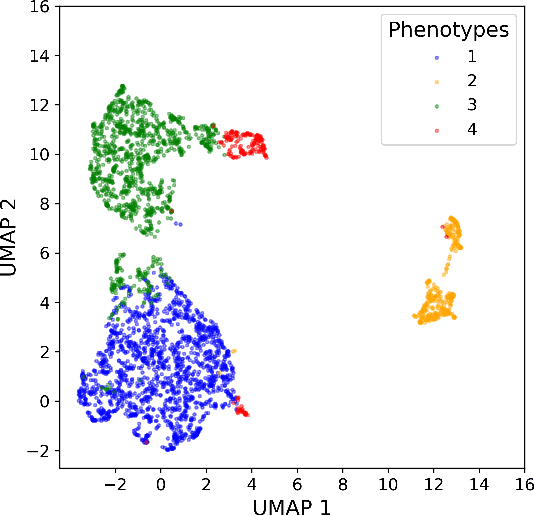
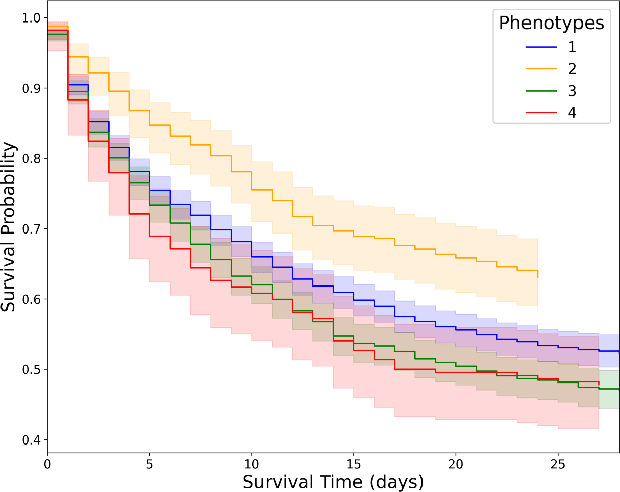
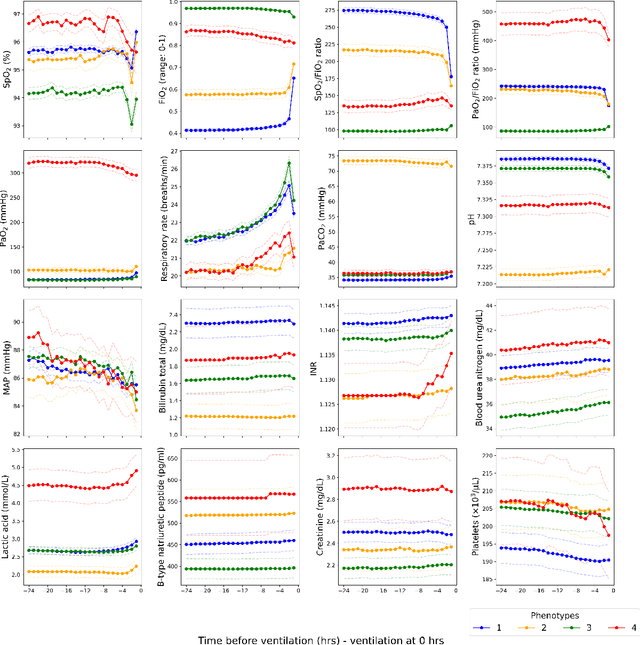
Sepsis-induced acute respiratory failure (ARF) is a serious complication with a poor prognosis. This paper presents a deep representation learningbased phenotyping method to identify distinct groups of clinical trajectories of septic patients with ARF. For this retrospective study, we created a dataset from electronic medical records (EMR) consisting of data from sepsis patients admitted to medical intensive care units who required at least 24 hours of invasive mechanical ventilation at a quarternary care academic hospital in southeast USA for the years 2016-2021. A total of N=3349 patient encounters were included in this study. Clustering Representation Learning on Incomplete Time Series Data (CRLI) algorithm was applied to a parsimonious set of EMR variables in this data set. To validate the optimal number of clusters, the K-means algorithm was used in conjunction with dynamic time warping. Our model yielded four distinct patient phenotypes that were characterized as liver dysfunction/heterogeneous, hypercapnia, hypoxemia, and multiple organ dysfunction syndrome by a critical care expert. A Kaplan-Meier analysis to compare the 28-day mortality trends exhibited significant differences (p < 0.005) between the four phenotypes. The study demonstrates the utility of our deep representation learning-based approach in unraveling phenotypes that reflect the heterogeneity in sepsis-induced ARF in terms of different mortality outcomes and severity. These phenotypes might reveal important clinical insights into an effective prognosis and tailored treatment strategies.
Energy-Based Models for Cross-Modal Localization using Convolutional Transformers
Jun 06, 2023We present a novel framework using Energy-Based Models (EBMs) for localizing a ground vehicle mounted with a range sensor against satellite imagery in the absence of GPS. Lidar sensors have become ubiquitous on autonomous vehicles for describing its surrounding environment. Map priors are typically built using the same sensor modality for localization purposes. However, these map building endeavors using range sensors are often expensive and time-consuming. Alternatively, we leverage the use of satellite images as map priors, which are widely available, easily accessible, and provide comprehensive coverage. We propose a method using convolutional transformers that performs accurate metric-level localization in a cross-modal manner, which is challenging due to the drastic difference in appearance between the sparse range sensor readings and the rich satellite imagery. We train our model end-to-end and demonstrate our approach achieving higher accuracy than the state-of-the-art on KITTI, Pandaset, and a custom dataset.
Model-based Behavioral Cloning with Future Image Similarity Learning
Oct 08, 2019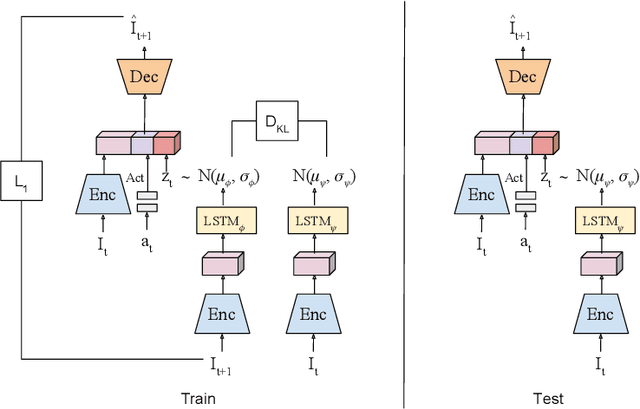


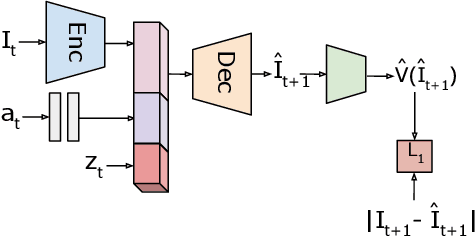
We present a visual imitation learning framework that enables learning of robot action policies solely based on expert samples without any robot trials. Robot exploration and on-policy trials in a real-world environment could often be expensive/dangerous. We present a new approach to address this problem by learning a future scene prediction model solely on a collection of expert trajectories consisting of unlabeled example videos and actions, and by enabling generalized action cloning using future image similarity. The robot learns to visually predict the consequences of taking an action, and obtains the policy by evaluating how similar the predicted future image is to an expert image. We develop a stochastic action-conditioned convolutional autoencoder, and present how we take advantage of future images for robot learning. We conduct experiments in simulated and real-life environments using a ground mobility robot with and without obstacles, and compare our models to multiple baseline methods.
Learning Real-World Robot Policies by Dreaming
Sep 11, 2018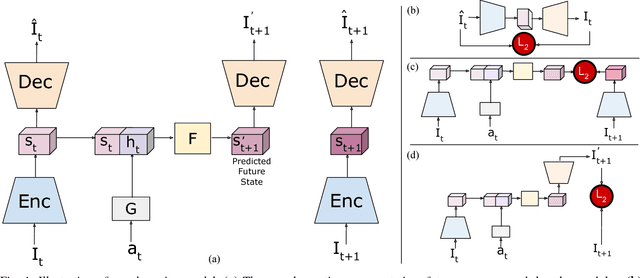
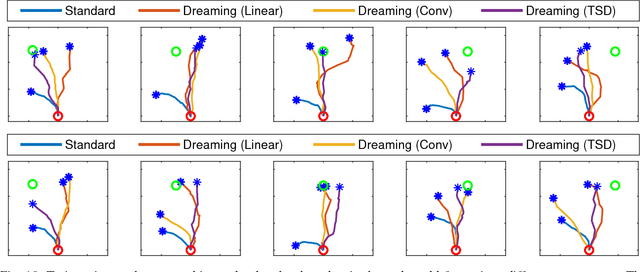

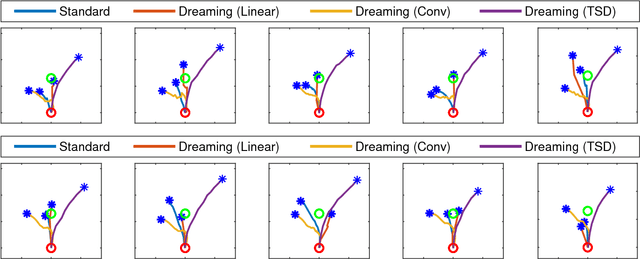
Learning to control robots directly based on images is a primary challenge in robotics. However, many existing reinforcement learning approaches require iteratively obtaining millions of samples to learn a policy which can take significant time. In this paper, we focus on the problem of learning real-world robot action policies solely based on a few random off-policy initial samples. We learn a realistic dreaming model that can emulate samples equivalent to a sequence of images from the actual environment, and make the agent learn action policies by interacting with the dreaming model rather than the real-world. We experimentally confirm that our dreaming model can learn realistic policies that transfer to the real-world.