 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNI-PoseX: A Fast Vision Model for 6D Object Pose Estimation in Embodied Tasks
Apr 03, 2026Accurate 6D object pose estimation is a fundamental capability for embodied agents, yet remains highly challenging in open-world environments. Many existing methods often rely on closed-set assumptions or geometry-agnostic regression schemes, limiting their generalization, stability, and real-time applicability in robotic systems. We present OMNI-PoseX, a vision foundation model that introduces a novel network architecture unifying open-vocabulary perception with an SO(3)-aware reflected flow matching pose predictor. The architecture decouples object-level understanding from geometry-consistent rotation inference, and employs a lightweight multi-modal fusion strategy that conditions rotation-sensitive geometric features on compact semantic embeddings, enabling efficient and stable 6D pose estimation. To enhance robustness and generalization, the model is trained on large-scale 6D pose datasets, leveraging broad object diversity, viewpoint variation, and scene complexity to build a scalable open-world pose backbone. Comprehensive evaluations across benchmark pose estimation, ablation studies, zero-shot generalization, and system-level robotic grasping integration demonstrate the effectiveness of OMNI-PoseX. The OMNI-PoseX achieves SOTA pose accuracy and real-time efficiency, while delivering geometrically consistent predictions that enable reliable grasping of diverse, previously unseen objects.
PAVE: Premise-Aware Validation and Editing for Retrieval-Augmented LLMs
Mar 21, 2026Retrieval-augmented language models can retrieve relevant evidence yet still commit to answers before explicitly checking whether the retrieved context supports the conclusion. We present PAVE (Premise-Grounded Answer Validation and Editing), an inference-time validation layer for evidence-grounded question answering. PAVE decomposes retrieved context into question-conditioned atomic facts, drafts an answer, scores how well that draft is supported by the extracted premises, and revises low-support outputs before finalization. The resulting trace makes answer commitment auditable at the level of explicit premises, support scores, and revision decisions. In controlled ablations with a fixed retriever and backbone, PAVE outperforms simpler post-retrieval baselines in two evidence-grounded QA settings, with the largest gain reaching 32.7 accuracy points on a span-grounded benchmark. We view these findings as proof-of-concept evidence that explicit premise extraction plus support-gated revision can strengthen evidence-grounded consistency in retrieval-augmented LLM systems.
GSR: Learning Structured Reasoning for Embodied Manipulation
Feb 02, 2026Despite rapid progress, embodied agents still struggle with long-horizon manipulation that requires maintaining spatial consistency, causal dependencies, and goal constraints. A key limitation of existing approaches is that task reasoning is implicitly embedded in high-dimensional latent representations, making it challenging to separate task structure from perceptual variability. We introduce Grounded Scene-graph Reasoning (GSR), a structured reasoning paradigm that explicitly models world-state evolution as transitions over semantically grounded scene graphs. By reasoning step-wise over object states and spatial relations, rather than directly mapping perception to actions, GSR enables explicit reasoning about action preconditions, consequences, and goal satisfaction in a physically grounded space. To support learning such reasoning, we construct Manip-Cognition-1.6M, a large-scale dataset that jointly supervises world understanding, action planning, and goal interpretation. Extensive evaluations across RLBench, LIBERO, GSR-benchmark, and real-world robotic tasks show that GSR significantly improves zero-shot generalization and long-horizon task completion over prompting-based baselines. These results highlight explicit world-state representations as a key inductive bias for scalable embodied reasoning.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Self-Interest and Systemic Benefits: Emergence of Collective Rationality in Mixed Autonomy Traffic Through Deep Reinforcement Learning
Nov 07, 2025Autonomous vehicles (AVs) are expected to be commercially available in the near future, leading to mixed autonomy traffic consisting of both AVs and human-driven vehicles (HVs). Although numerous studies have shown that AVs can be deployed to benefit the overall traffic system performance by incorporating system-level goals into their decision making, it is not clear whether the benefits still exist when agents act out of self-interest -- a trait common to all driving agents, both human and autonomous. This study aims to understand whether self-interested AVs can bring benefits to all driving agents in mixed autonomy traffic systems. The research is centered on the concept of collective rationality (CR). This concept, originating from game theory and behavioral economics, means that driving agents may cooperate collectively even when pursuing individual interests. Our recent research has proven the existence of CR in an analytical game-theoretical model and empirically in mixed human-driven traffic. In this paper, we demonstrate that CR can be attained among driving agents trained using deep reinforcement learning (DRL) with a simple reward design. We examine the extent to which self-interested traffic agents can achieve CR without directly incorporating system-level objectives. Results show that CR consistently emerges in various scenarios, which indicates the robustness of this property. We also postulate a mechanism to explain the emergence of CR in the microscopic and dynamic environment and verify it based on simulation evidence. This research suggests the possibility of leveraging advanced learning methods (such as federated learning) to achieve collective cooperation among self-interested driving agents in mixed-autonomy systems.
Enhanced Vehicle Speed Detection Considering Lane Recognition Using Drone Videos in California
Jun 12, 2025The increase in vehicle numbers in California, driven by inadequate transportation systems and sparse speed cameras, necessitates effective vehicle speed detection. Detecting vehicle speeds per lane is critical for monitoring High-Occupancy Vehicle (HOV) lane speeds, distinguishing between cars and heavy vehicles with differing speed limits, and enforcing lane restrictions for heavy vehicles. While prior works utilized YOLO (You Only Look Once) for vehicle speed detection, they often lacked accuracy, failed to identify vehicle lanes, and offered limited or less practical classification categories. This study introduces a fine-tuned YOLOv11 model, trained on almost 800 bird's-eye view images, to enhance vehicle speed detection accuracy which is much higher compare to the previous works. The proposed system identifies the lane for each vehicle and classifies vehicles into two categories: cars and heavy vehicles. Designed to meet the specific requirements of traffic monitoring and regulation, the model also evaluates the effects of factors such as drone height, distance of Region of Interest (ROI), and vehicle speed on detection accuracy and speed measurement. Drone footage collected from Northern California was used to assess the proposed system. The fine-tuned YOLOv11 achieved its best performance with a mean absolute error (MAE) of 0.97 mph and mean squared error (MSE) of 0.94 $\text{mph}^2$, demonstrating its efficacy in addressing challenges in vehicle speed detection and classification.
Fast Estimation of Globally Optimal Independent Contact Regions for Robust Grasping and Manipulation
Jun 10, 2025This work presents a fast anytime algorithm for computing globally optimal independent contact regions (ICRs). ICRs are regions such that one contact within each region enables a valid grasp. Locations of ICRs can provide guidance for grasp and manipulation planning, learning, and policy transfer. However, ICRs for modern applications have been little explored, in part due to the expense of computing them, as they have a search space exponential in the number of contacts. We present a divide and conquer algorithm based on incremental n-dimensional Delaunay triangulation that produces results with bounded suboptimality in times sufficient for real-time planning. This paper presents the base algorithm for grasps where contacts lie within a plane. Our experiments show substantial benefits over competing grasp quality metrics and speedups of 100X and more for competing approaches to computing ICRs. We explore robustness of a policy guided by ICRs and outline a path to general 3D implementation. Code will be released on publication to facilitate further development and applications.
Guiding Data Collection via Factored Scaling Curves
May 12, 2025Generalist imitation learning policies trained on large datasets show great promise for solving diverse manipulation tasks. However, to ensure generalization to different conditions, policies need to be trained with data collected across a large set of environmental factor variations (e.g., camera pose, table height, distractors) $-$ a prohibitively expensive undertaking, if done exhaustively. We introduce a principled method for deciding what data to collect and how much to collect for each factor by constructing factored scaling curves (FSC), which quantify how policy performance varies as data scales along individual or paired factors. These curves enable targeted data acquisition for the most influential factor combinations within a given budget. We evaluate the proposed method through extensive simulated and real-world experiments, across both training-from-scratch and fine-tuning settings, and show that it boosts success rates in real-world tasks in new environments by up to 26% over existing data-collection strategies. We further demonstrate how factored scaling curves can effectively guide data collection using an offline metric, without requiring real-world evaluation at scale.
LoLCATs: On Low-Rank Linearizing of Large Language Models
Oct 14, 2024

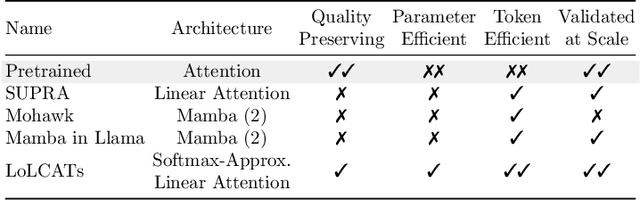

Recent works show we can linearize large language models (LLMs) -- swapping the quadratic attentions of popular Transformer-based LLMs with subquadratic analogs, such as linear attention -- avoiding the expensive pretraining costs. However, linearizing LLMs often significantly degrades model quality, still requires training over billions of tokens, and remains limited to smaller 1.3B to 7B LLMs. We thus propose Low-rank Linear Conversion via Attention Transfer (LoLCATs), a simple two-step method that improves LLM linearizing quality with orders of magnitudes less memory and compute. We base these steps on two findings. First, we can replace an LLM's softmax attentions with closely-approximating linear attentions, simply by training the linear attentions to match their softmax counterparts with an output MSE loss ("attention transfer"). Then, this enables adjusting for approximation errors and recovering LLM quality simply with low-rank adaptation (LoRA). LoLCATs significantly improves linearizing quality, training efficiency, and scalability. We significantly reduce the linearizing quality gap and produce state-of-the-art subquadratic LLMs from Llama 3 8B and Mistral 7B v0.1, leading to 20+ points of improvement on 5-shot MMLU. Furthermore, LoLCATs does so with only 0.2% of past methods' model parameters and 0.4% of their training tokens. Finally, we apply LoLCATs to create the first linearized 70B and 405B LLMs (50x larger than prior work). When compared with prior approaches under the same compute budgets, LoLCATs significantly improves linearizing quality, closing the gap between linearized and original Llama 3.1 70B and 405B LLMs by 77.8% and 78.1% on 5-shot MMLU.
Simple linear attention language models balance the recall-throughput tradeoff
Feb 28, 2024



Recent work has shown that attention-based language models excel at recall, the ability to ground generations in tokens previously seen in context. However, the efficiency of attention-based models is bottle-necked during inference by the KV-cache's aggressive memory consumption. In this work, we explore whether we can improve language model efficiency (e.g. by reducing memory consumption) without compromising on recall. By applying experiments and theory to a broad set of architectures, we identify a key tradeoff between a model's state size and recall ability. We show that efficient alternatives to attention (e.g. H3, Mamba, RWKV) maintain a fixed-size recurrent state, but struggle at recall. We propose BASED a simple architecture combining linear and sliding window attention. By varying BASED window size and linear attention feature dimension, we can dial the state size and traverse the pareto frontier of the recall-memory tradeoff curve, recovering the full quality of attention on one end and the small state size of attention-alternatives on the other. We train language models up to 1.3b parameters and show that BASED matches the strongest sub-quadratic models (e.g. Mamba) in perplexity and outperforms them on real-world recall-intensive tasks by 6.22 accuracy points. Implementations of linear attention are often less efficient than optimized standard attention implementations. To make BASED competitive, we develop IO-aware algorithms that enable 24x higher throughput on language generation than FlashAttention-2, when generating 1024 tokens using 1.3b parameter models. Code for this work is provided at: https://github.com/HazyResearch/based.