 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Rewards via LLM-Generated Progress Functions
Oct 11, 2024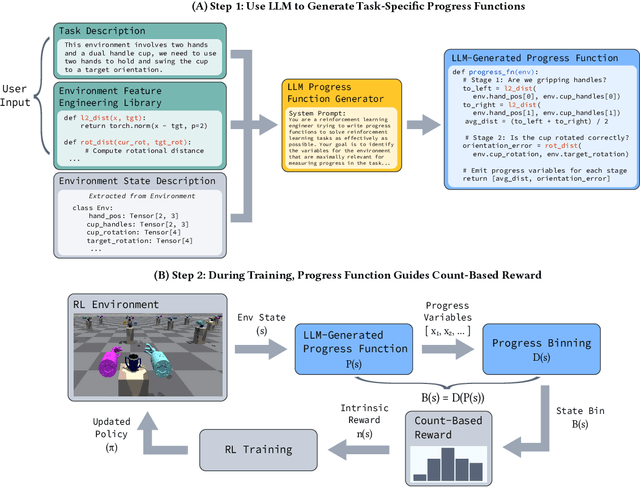
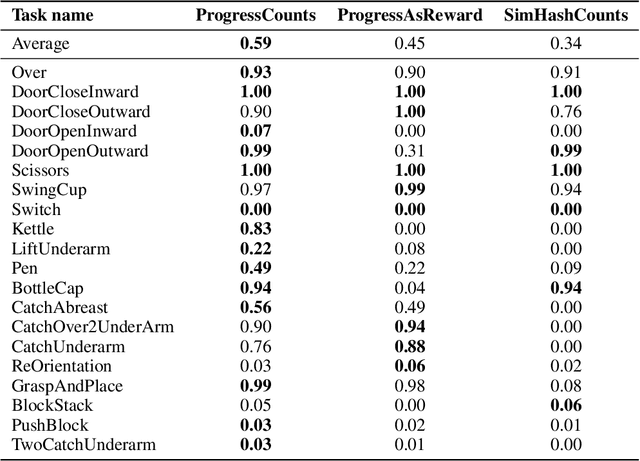
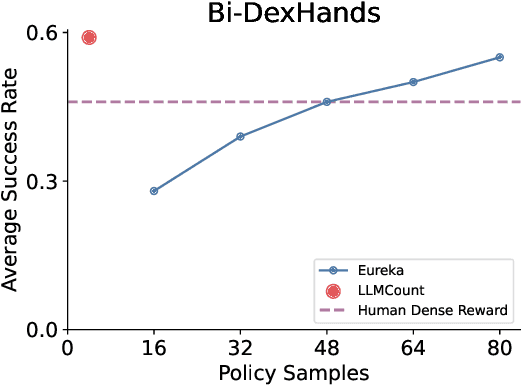

Large Language Models (LLMs) have the potential to automate reward engineering by leveraging their broad domain knowledge across various tasks. However, they often need many iterations of trial-and-error to generate effective reward functions. This process is costly because evaluating every sampled reward function requires completing the full policy optimization process for each function. In this paper, we introduce an LLM-driven reward generation framework that is able to produce state-of-the-art policies on the challenging Bi-DexHands benchmark \textbf{with 20$\times$ fewer reward function samples} than the prior state-of-the-art work. Our key insight is that we reduce the problem of generating task-specific rewards to the problem of coarsely estimating \emph{task progress}. Our two-step solution leverages the task domain knowledge and the code synthesis abilities of LLMs to author \emph{progress functions} that estimate task progress from a given state. Then, we use this notion of progress to discretize states, and generate count-based intrinsic rewards using the low-dimensional state space. We show that the combination of LLM-generated progress functions and count-based intrinsic rewards is essential for our performance gains, while alternatives such as generic hash-based counts or using progress directly as a reward function fall short.
Cookbook: A framework for improving LLM generative abilities via programmatic data generating templates
Oct 07, 2024



Fine-tuning large language models (LLMs) on instruction datasets is a common way to improve their generative capabilities. However, instruction datasets can be expensive and time-consuming to manually curate, and while LLM-generated data is less labor-intensive, it may violate user privacy agreements or terms of service of LLM providers. Therefore, we seek a way of constructing instruction datasets with samples that are not generated by humans or LLMs but still improve LLM generative capabilities. In this work, we introduce Cookbook, a framework that programmatically generates training data consisting of simple patterns over random tokens, resulting in a scalable, cost-effective approach that avoids legal and privacy issues. First, Cookbook uses a template -- a data generating Python function -- to produce training data that encourages the model to learn an explicit pattern-based rule that corresponds to a desired task. We find that fine-tuning on Cookbook-generated data is able to improve performance on its corresponding task by up to 52.7 accuracy points. Second, since instruction datasets improve performance on multiple downstream tasks simultaneously, Cookbook algorithmically learns how to mix data from various templates to optimize performance on multiple tasks. On the standard multi-task GPT4ALL evaluation suite, Mistral-7B fine-tuned using a Cookbook-generated dataset attains the best accuracy on average compared to other 7B parameter instruction-tuned models and is the best performing model on 3 out of 8 tasks. Finally, we analyze when and why Cookbook improves performance and present a metric that allows us to verify that the improvement is largely explained by the model's generations adhering better to template rules.
The Hedgehog & the Porcupine: Expressive Linear Attentions with Softmax Mimicry
Feb 06, 2024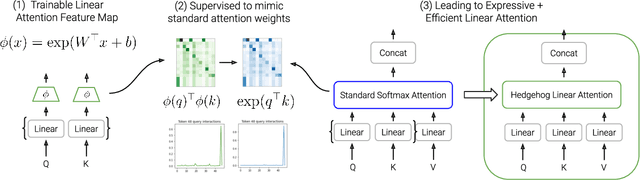

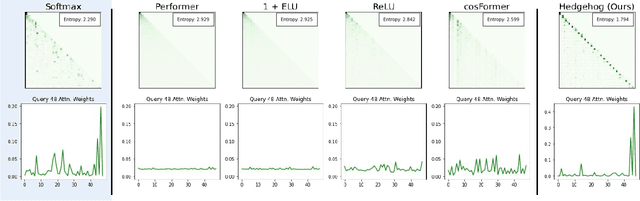
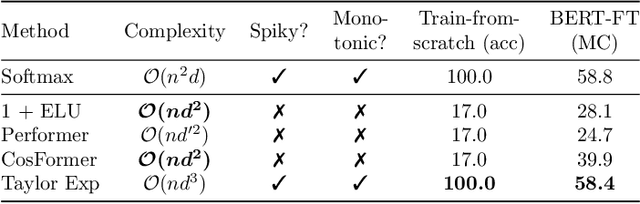
Linear attentions have shown potential for improving Transformer efficiency, reducing attention's quadratic complexity to linear in sequence length. This holds exciting promise for (1) training linear Transformers from scratch, (2) "finetuned-conversion" of task-specific Transformers into linear versions that recover task performance, and (3) "pretrained-conversion" of Transformers such as large language models into linear versions finetunable on downstream tasks. However, linear attentions often underperform standard softmax attention in quality. To close this performance gap, we find prior linear attentions lack key properties of softmax attention tied to good performance: low-entropy (or "spiky") weights and dot-product monotonicity. We further observe surprisingly simple feature maps that retain these properties and match softmax performance, but are inefficient to compute in linear attention. We thus propose Hedgehog, a learnable linear attention that retains the spiky and monotonic properties of softmax attention while maintaining linear complexity. Hedgehog uses simple trainable MLPs to produce attention weights mimicking softmax attention. Experiments show Hedgehog recovers over 99% of standard Transformer quality in train-from-scratch and finetuned-conversion settings, outperforming prior linear attentions up to 6 perplexity points on WikiText-103 with causal GPTs, and up to 8.7 GLUE score points on finetuned bidirectional BERTs. Hedgehog also enables pretrained-conversion. Converting a pretrained GPT-2 into a linear attention variant achieves state-of-the-art 16.7 perplexity on WikiText-103 for 125M subquadratic decoder models. We finally turn a pretrained Llama-2 7B into a viable linear attention Llama. With low-rank adaptation, Hedgehog-Llama2 7B achieves 28.1 higher ROUGE-1 points over the base standard attention model, where prior linear attentions lead to 16.5 point drops.
SuperHF: Supervised Iterative Learning from Human Feedback
Oct 25, 2023


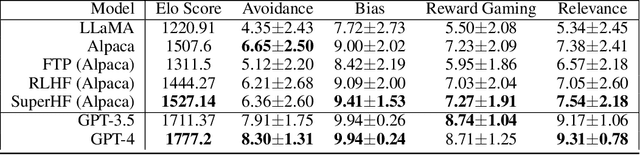
While large language models demonstrate remarkable capabilities, they often present challenges in terms of safety, alignment with human values, and stability during training. Here, we focus on two prevalent methods used to align these models, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT is simple and robust, powering a host of open-source models, while RLHF is a more sophisticated method used in top-tier models like ChatGPT but also suffers from instability and susceptibility to reward hacking. We propose a novel approach, Supervised Iterative Learning from Human Feedback (SuperHF), which seeks to leverage the strengths of both methods. Our hypothesis is two-fold: that the reward model used in RLHF is critical for efficient data use and model generalization and that the use of Proximal Policy Optimization (PPO) in RLHF may not be necessary and could contribute to instability issues. SuperHF replaces PPO with a simple supervised loss and a Kullback-Leibler (KL) divergence prior. It creates its own training data by repeatedly sampling a batch of model outputs and filtering them through the reward model in an online learning regime. We then break down the reward optimization problem into three components: robustly optimizing the training rewards themselves, preventing reward hacking-exploitation of the reward model that degrades model performance-as measured by a novel METEOR similarity metric, and maintaining good performance on downstream evaluations. Our experimental results show SuperHF exceeds PPO-based RLHF on the training objective, easily and favorably trades off high reward with low reward hacking, improves downstream calibration, and performs the same on our GPT-4 based qualitative evaluation scheme all the while being significantly simpler to implement, highlighting SuperHF's potential as a competitive language model alignment technique.
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models
Jul 26, 2023The quality of training data impacts the performance of pre-trained large language models (LMs). Given a fixed budget of tokens, we study how to best select data that leads to good downstream model performance across tasks. We develop a new framework based on a simple hypothesis: just as humans acquire interdependent skills in a deliberate order, language models also follow a natural order when learning a set of skills from their training data. If such an order exists, it can be utilized for improved understanding of LMs and for data-efficient training. Using this intuition, our framework formalizes the notion of a skill and of an ordered set of skills in terms of the associated data. First, using both synthetic and real data, we demonstrate that these ordered skill sets exist, and that their existence enables more advanced skills to be learned with less data when we train on their prerequisite skills. Second, using our proposed framework, we introduce an online data sampling algorithm, Skill-It, over mixtures of skills for both continual pre-training and fine-tuning regimes, where the objective is to efficiently learn multiple skills in the former and an individual skill in the latter. On the LEGO synthetic in the continual pre-training setting, Skill-It obtains 36.5 points higher accuracy than random sampling. On the Natural Instructions dataset in the fine-tuning setting, Skill-It reduces the validation loss on the target skill by 13.6% versus training on data associated with the target skill itself. We apply our skills framework on the recent RedPajama dataset to continually pre-train a 3B-parameter LM, achieving higher accuracy on the LM Evaluation Harness with 1B tokens than the baseline approach of sampling uniformly over data sources with 3B tokens.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification
Jul 20, 2023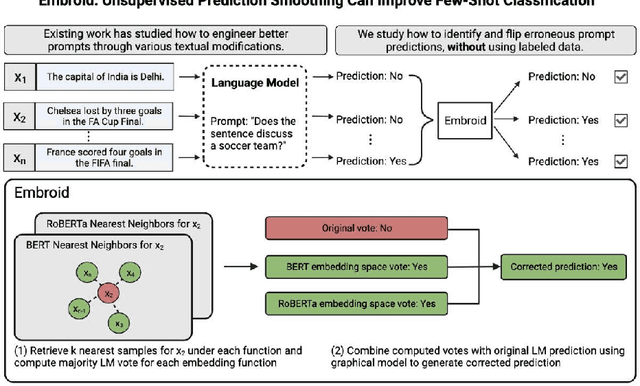
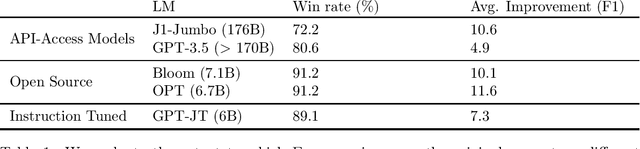
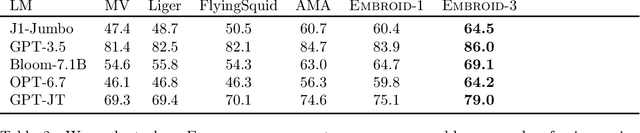
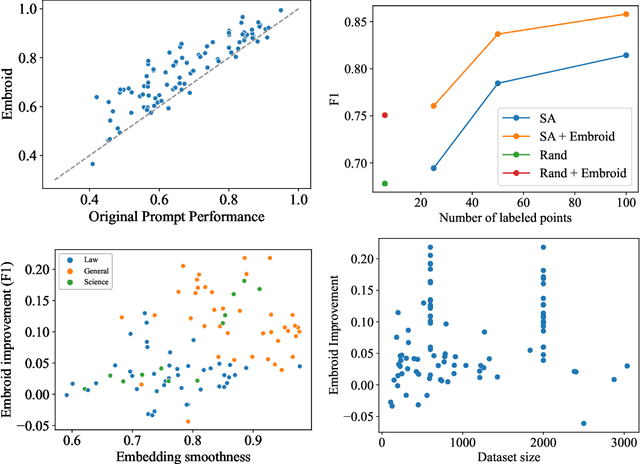
Recent work has shown that language models' (LMs) prompt-based learning capabilities make them well suited for automating data labeling in domains where manual annotation is expensive. The challenge is that while writing an initial prompt is cheap, improving a prompt is costly -- practitioners often require significant labeled data in order to evaluate the impact of prompt modifications. Our work asks whether it is possible to improve prompt-based learning without additional labeled data. We approach this problem by attempting to modify the predictions of a prompt, rather than the prompt itself. Our intuition is that accurate predictions should also be consistent: samples which are similar under some feature representation should receive the same prompt prediction. We propose Embroid, a method which computes multiple representations of a dataset under different embedding functions, and uses the consistency between the LM predictions for neighboring samples to identify mispredictions. Embroid then uses these neighborhoods to create additional predictions for each sample, and combines these predictions with a simple latent variable graphical model in order to generate a final corrected prediction. In addition to providing a theoretical analysis of Embroid, we conduct a rigorous empirical evaluation across six different LMs and up to 95 different tasks. We find that (1) Embroid substantially improves performance over original prompts (e.g., by an average of 7.3 points on GPT-JT), (2) also realizes improvements for more sophisticated prompting strategies (e.g., chain-of-thought), and (3) can be specialized to domains like law through the embedding functions.
TART: A plug-and-play Transformer module for task-agnostic reasoning
Jun 13, 2023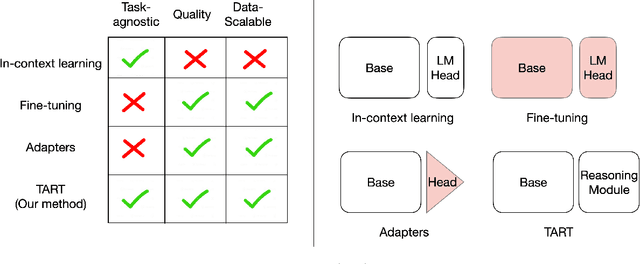

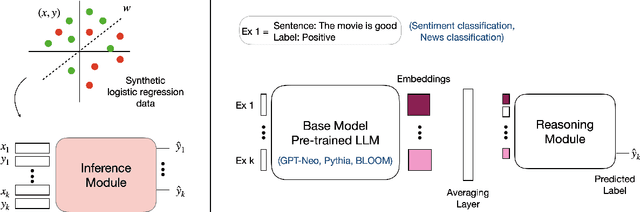
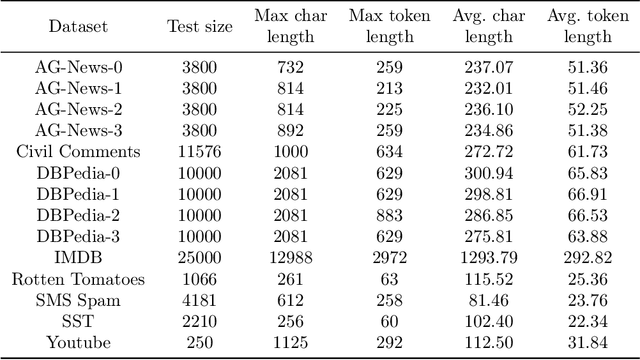
Large language models (LLMs) exhibit in-context learning abilities which enable the same model to perform several tasks without any task-specific training. In contrast, traditional adaptation approaches, such as fine-tuning, modify the underlying models for each specific task. In-context learning, however, consistently underperforms task-specific tuning approaches even when presented with the same examples. While most existing approaches (e.g., prompt engineering) focus on the LLM's learned representations to patch this performance gap, our analysis actually reveal that LLM representations contain sufficient information to make good predictions. As such, we focus on the LLM's reasoning abilities and demonstrate that this performance gap exists due to their inability to perform simple probabilistic reasoning tasks. This raises an intriguing question: Are LLMs actually capable of learning how to reason in a task-agnostic manner? We answer this in the affirmative and propose TART which generically improves an LLM's reasoning abilities using a synthetically trained Transformer-based reasoning module. TART trains this reasoning module in a task-agnostic manner using only synthetic logistic regression tasks and composes it with an arbitrary real-world pre-trained model without any additional training. With a single inference module, TART improves performance across different model families (GPT-Neo, Pythia, BLOOM), model sizes (100M - 6B), tasks (14 NLP binary classification tasks), and even across different modalities (audio and vision). Additionally, on the RAFT Benchmark, TART improves GPT-Neo (125M)'s performance such that it outperforms BLOOM (176B), and is within 4% of GPT-3 (175B). Our code and models are available at https://github.com/HazyResearch/TART .
Reward Learning as Doubly Nonparametric Bandits: Optimal Design and Scaling Laws
Feb 23, 2023
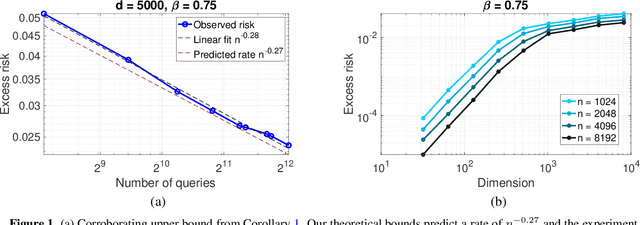
Specifying reward functions for complex tasks like object manipulation or driving is challenging to do by hand. Reward learning seeks to address this by learning a reward model using human feedback on selected query policies. This shifts the burden of reward specification to the optimal design of the queries. We propose a theoretical framework for studying reward learning and the associated optimal experiment design problem. Our framework models rewards and policies as nonparametric functions belonging to subsets of Reproducing Kernel Hilbert Spaces (RKHSs). The learner receives (noisy) oracle access to a true reward and must output a policy that performs well under the true reward. For this setting, we first derive non-asymptotic excess risk bounds for a simple plug-in estimator based on ridge regression. We then solve the query design problem by optimizing these risk bounds with respect to the choice of query set and obtain a finite sample statistical rate, which depends primarily on the eigenvalue spectrum of a certain linear operator on the RKHSs. Despite the generality of these results, our bounds are stronger than previous bounds developed for more specialized problems. We specifically show that the well-studied problem of Gaussian process (GP) bandit optimization is a special case of our framework, and that our bounds either improve or are competitive with known regret guarantees for the Mat\'ern kernel.
Congested Bandits: Optimal Routing via Short-term Resets
Jan 23, 2023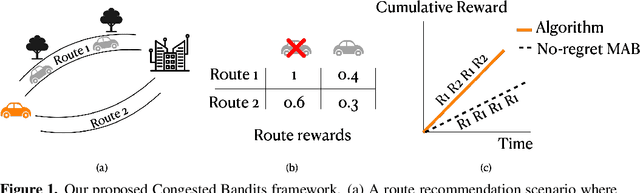
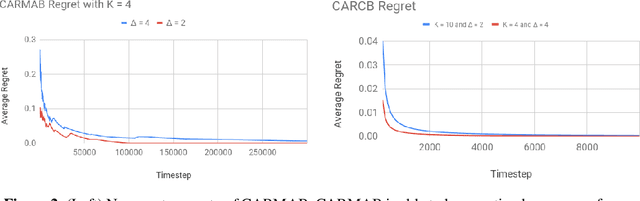
For traffic routing platforms, the choice of which route to recommend to a user depends on the congestion on these routes -- indeed, an individual's utility depends on the number of people using the recommended route at that instance. Motivated by this, we introduce the problem of Congested Bandits where each arm's reward is allowed to depend on the number of times it was played in the past $\Delta$ timesteps. This dependence on past history of actions leads to a dynamical system where an algorithm's present choices also affect its future pay-offs, and requires an algorithm to plan for this. We study the congestion aware formulation in the multi-armed bandit (MAB) setup and in the contextual bandit setup with linear rewards. For the multi-armed setup, we propose a UCB style algorithm and show that its policy regret scales as $\tilde{O}(\sqrt{K \Delta T})$. For the linear contextual bandit setup, our algorithm, based on an iterative least squares planner, achieves policy regret $\tilde{O}(\sqrt{dT} + \Delta)$. From an experimental standpoint, we corroborate the no-regret properties of our algorithms via a simulation study.
On the Sensitivity of Reward Inference to Misspecified Human Models
Dec 09, 2022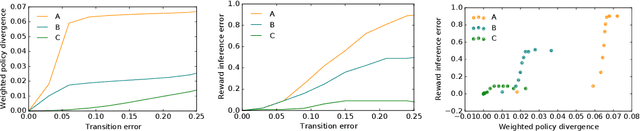
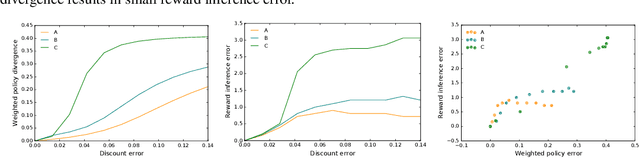
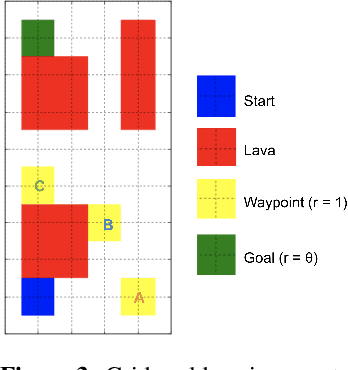
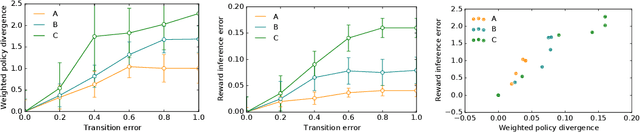
Inferring reward functions from human behavior is at the center of value alignment - aligning AI objectives with what we, humans, actually want. But doing so relies on models of how humans behave given their objectives. After decades of research in cognitive science, neuroscience, and behavioral economics, obtaining accurate human models remains an open research topic. This begs the question: how accurate do these models need to be in order for the reward inference to be accurate? On the one hand, if small errors in the model can lead to catastrophic error in inference, the entire framework of reward learning seems ill-fated, as we will never have perfect models of human behavior. On the other hand, if as our models improve, we can have a guarantee that reward accuracy also improves, this would show the benefit of more work on the modeling side. We study this question both theoretically and empirically. We do show that it is unfortunately possible to construct small adversarial biases in behavior that lead to arbitrarily large errors in the inferred reward. However, and arguably more importantly, we are also able to identify reasonable assumptions under which the reward inference error can be bounded linearly in the error in the human model. Finally, we verify our theoretical insights in discrete and continuous control tasks with simulated and human data.