 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperHF: Supervised Iterative Learning from Human Feedback
Oct 25, 2023


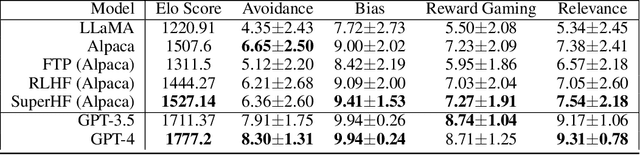
While large language models demonstrate remarkable capabilities, they often present challenges in terms of safety, alignment with human values, and stability during training. Here, we focus on two prevalent methods used to align these models, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT is simple and robust, powering a host of open-source models, while RLHF is a more sophisticated method used in top-tier models like ChatGPT but also suffers from instability and susceptibility to reward hacking. We propose a novel approach, Supervised Iterative Learning from Human Feedback (SuperHF), which seeks to leverage the strengths of both methods. Our hypothesis is two-fold: that the reward model used in RLHF is critical for efficient data use and model generalization and that the use of Proximal Policy Optimization (PPO) in RLHF may not be necessary and could contribute to instability issues. SuperHF replaces PPO with a simple supervised loss and a Kullback-Leibler (KL) divergence prior. It creates its own training data by repeatedly sampling a batch of model outputs and filtering them through the reward model in an online learning regime. We then break down the reward optimization problem into three components: robustly optimizing the training rewards themselves, preventing reward hacking-exploitation of the reward model that degrades model performance-as measured by a novel METEOR similarity metric, and maintaining good performance on downstream evaluations. Our experimental results show SuperHF exceeds PPO-based RLHF on the training objective, easily and favorably trades off high reward with low reward hacking, improves downstream calibration, and performs the same on our GPT-4 based qualitative evaluation scheme all the while being significantly simpler to implement, highlighting SuperHF's potential as a competitive language model alignment technique.
Explaining Image Classifiers with Multiscale Directional Image Representation
Nov 24, 2022
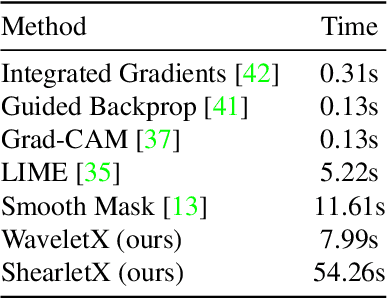

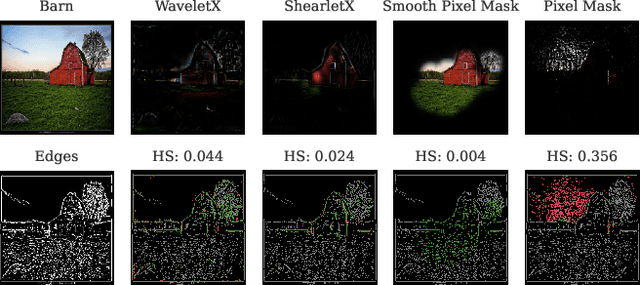
Image classifiers are known to be difficult to interpret and therefore require explanation methods to understand their decisions. We present ShearletX, a novel mask explanation method for image classifiers based on the shearlet transform -- a multiscale directional image representation. Current mask explanation methods are regularized by smoothness constraints that protect against undesirable fine-grained explanation artifacts. However, the smoothness of a mask limits its ability to separate fine-detail patterns, that are relevant for the classifier, from nearby nuisance patterns, that do not affect the classifier. ShearletX solves this problem by avoiding smoothness regularization all together, replacing it by shearlet sparsity constraints. The resulting explanations consist of a few edges, textures, and smooth parts of the original image, that are the most relevant for the decision of the classifier. To support our method, we propose a mathematical definition for explanation artifacts and an information theoretic score to evaluate the quality of mask explanations. We demonstrate the superiority of ShearletX over previous mask based explanation methods using these new metrics, and present exemplary situations where separating fine-detail patterns allows explaining phenomena that were not explainable before.