 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKevin: Multi-Turn RL for Generating CUDA Kernels
Jul 16, 2025


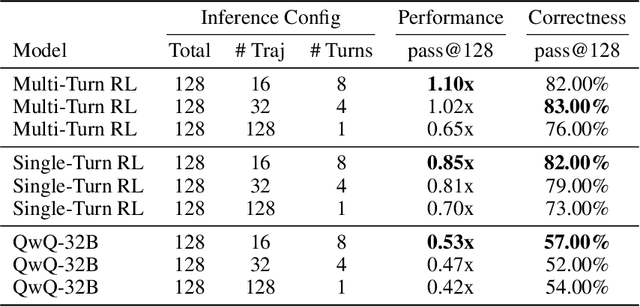
Writing GPU kernels is a challenging task and critical for AI systems' efficiency. It is also highly iterative: domain experts write code and improve performance through execution feedback. Moreover, it presents verifiable rewards like correctness and speedup, making it a natural environment to apply Reinforcement Learning (RL). To explicitly incorporate the iterative nature of this process into training, we develop a flexible multi-turn RL recipe that addresses unique challenges encountered in real-world settings, such as learning from long trajectories and effective reward attribution across turns. We present Kevin - K(ernel D)evin, the first model trained with multi-turn RL for CUDA kernel generation and optimization. In our evaluation setup, Kevin shows significant gains over its base model (QwQ-32B), improving correctness of generated kernels (in pure CUDA) from 56% to 82% and mean speedup from 0.53x to 1.10x of baseline (PyTorch Eager), and surpassing frontier models like o4-mini (0.78x). Finally, we study its behavior across test-time scaling axes: we found scaling serial refinement more beneficial than parallel sampling. In particular, when given more refinement turns, Kevin shows a higher rate of improvement.
Data Unlearning in Diffusion Models
Mar 02, 2025Recent work has shown that diffusion models memorize and reproduce training data examples. At the same time, large copyright lawsuits and legislation such as GDPR have highlighted the need for erasing datapoints from diffusion models. However, retraining from scratch is often too expensive. This motivates the setting of data unlearning, i.e., the study of efficient techniques for unlearning specific datapoints from the training set. Existing concept unlearning techniques require an anchor prompt/class/distribution to guide unlearning, which is not available in the data unlearning setting. General-purpose machine unlearning techniques were found to be either unstable or failed to unlearn data. We therefore propose a family of new loss functions called Subtracted Importance Sampled Scores (SISS) that utilize importance sampling and are the first method to unlearn data with theoretical guarantees. SISS is constructed as a weighted combination between simpler objectives that are responsible for preserving model quality and unlearning the targeted datapoints. When evaluated on CelebA-HQ and MNIST, SISS achieved Pareto optimality along the quality and unlearning strength dimensions. On Stable Diffusion, SISS successfully mitigated memorization on nearly 90% of the prompts we tested.
Cannot or Should Not? Automatic Analysis of Refusal Composition in IFT/RLHF Datasets and Refusal Behavior of Black-Box LLMs
Dec 22, 2024



Refusals - instances where large language models (LLMs) decline or fail to fully execute user instructions - are crucial for both AI safety and AI capabilities and the reduction of hallucinations in particular. These behaviors are learned during post-training, especially in instruction fine-tuning (IFT) and reinforcement learning from human feedback (RLHF). However, existing taxonomies and evaluation datasets for refusals are inadequate, often focusing solely on should-not-related (instead of cannot-related) categories, and lacking tools for auditing refusal content in black-box LLM outputs. We present a comprehensive framework for classifying LLM refusals: (a) a taxonomy of 16 refusal categories, (b) a human-annotated dataset of over 8,600 instances from publicly available IFT and RLHF datasets, (c) a synthetic dataset with 8,000 examples for each refusal category, and (d) classifiers trained for refusal classification. Our work enables precise auditing of refusal behaviors in black-box LLMs and automatic analyses of refusal patterns in large IFT and RLHF datasets. This facilitates the strategic adjustment of LLM refusals, contributing to the development of more safe and reliable LLMs.
Simple linear attention language models balance the recall-throughput tradeoff
Feb 28, 2024



Recent work has shown that attention-based language models excel at recall, the ability to ground generations in tokens previously seen in context. However, the efficiency of attention-based models is bottle-necked during inference by the KV-cache's aggressive memory consumption. In this work, we explore whether we can improve language model efficiency (e.g. by reducing memory consumption) without compromising on recall. By applying experiments and theory to a broad set of architectures, we identify a key tradeoff between a model's state size and recall ability. We show that efficient alternatives to attention (e.g. H3, Mamba, RWKV) maintain a fixed-size recurrent state, but struggle at recall. We propose BASED a simple architecture combining linear and sliding window attention. By varying BASED window size and linear attention feature dimension, we can dial the state size and traverse the pareto frontier of the recall-memory tradeoff curve, recovering the full quality of attention on one end and the small state size of attention-alternatives on the other. We train language models up to 1.3b parameters and show that BASED matches the strongest sub-quadratic models (e.g. Mamba) in perplexity and outperforms them on real-world recall-intensive tasks by 6.22 accuracy points. Implementations of linear attention are often less efficient than optimized standard attention implementations. To make BASED competitive, we develop IO-aware algorithms that enable 24x higher throughput on language generation than FlashAttention-2, when generating 1024 tokens using 1.3b parameter models. Code for this work is provided at: https://github.com/HazyResearch/based.
Black-Box Access is Insufficient for Rigorous AI Audits
Jan 25, 2024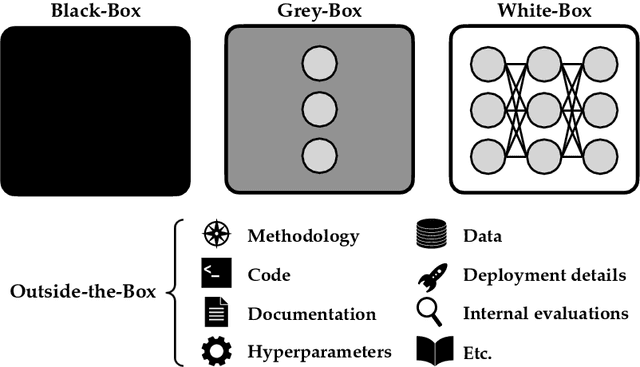
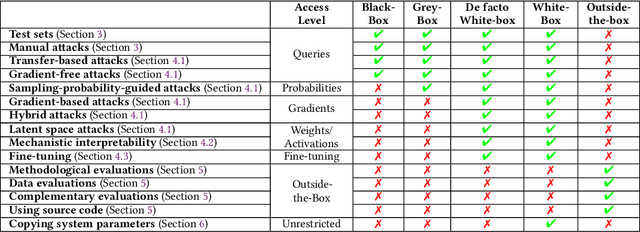
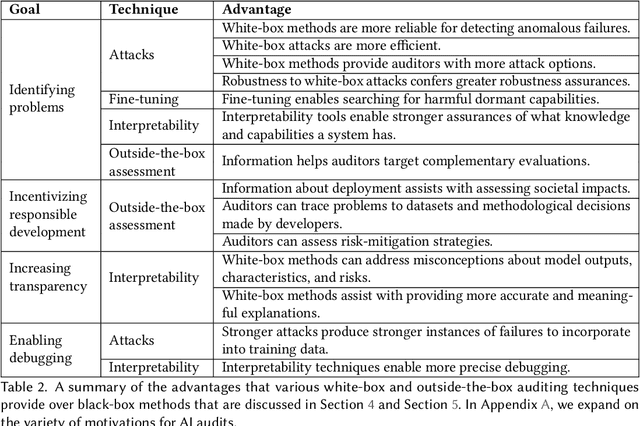
External audits of AI systems are increasingly recognized as a key mechanism for AI governance. The effectiveness of an audit, however, depends on the degree of system access granted to auditors. Recent audits of state-of-the-art AI systems have primarily relied on black-box access, in which auditors can only query the system and observe its outputs. However, white-box access to the system's inner workings (e.g., weights, activations, gradients) allows an auditor to perform stronger attacks, more thoroughly interpret models, and conduct fine-tuning. Meanwhile, outside-the-box access to its training and deployment information (e.g., methodology, code, documentation, hyperparameters, data, deployment details, findings from internal evaluations) allows for auditors to scrutinize the development process and design more targeted evaluations. In this paper, we examine the limitations of black-box audits and the advantages of white- and outside-the-box audits. We also discuss technical, physical, and legal safeguards for performing these audits with minimal security risks. Given that different forms of access can lead to very different levels of evaluation, we conclude that (1) transparency regarding the access and methods used by auditors is necessary to properly interpret audit results, and (2) white- and outside-the-box access allow for substantially more scrutiny than black-box access alone.
SuperHF: Supervised Iterative Learning from Human Feedback
Oct 25, 2023


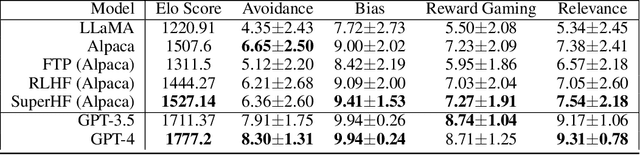
While large language models demonstrate remarkable capabilities, they often present challenges in terms of safety, alignment with human values, and stability during training. Here, we focus on two prevalent methods used to align these models, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT is simple and robust, powering a host of open-source models, while RLHF is a more sophisticated method used in top-tier models like ChatGPT but also suffers from instability and susceptibility to reward hacking. We propose a novel approach, Supervised Iterative Learning from Human Feedback (SuperHF), which seeks to leverage the strengths of both methods. Our hypothesis is two-fold: that the reward model used in RLHF is critical for efficient data use and model generalization and that the use of Proximal Policy Optimization (PPO) in RLHF may not be necessary and could contribute to instability issues. SuperHF replaces PPO with a simple supervised loss and a Kullback-Leibler (KL) divergence prior. It creates its own training data by repeatedly sampling a batch of model outputs and filtering them through the reward model in an online learning regime. We then break down the reward optimization problem into three components: robustly optimizing the training rewards themselves, preventing reward hacking-exploitation of the reward model that degrades model performance-as measured by a novel METEOR similarity metric, and maintaining good performance on downstream evaluations. Our experimental results show SuperHF exceeds PPO-based RLHF on the training objective, easily and favorably trades off high reward with low reward hacking, improves downstream calibration, and performs the same on our GPT-4 based qualitative evaluation scheme all the while being significantly simpler to implement, highlighting SuperHF's potential as a competitive language model alignment technique.
PIGEON: Predicting Image Geolocations
Jul 13, 2023
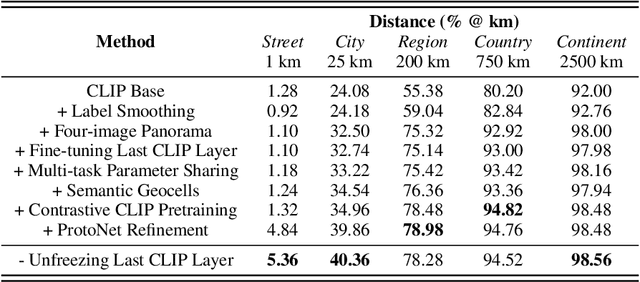
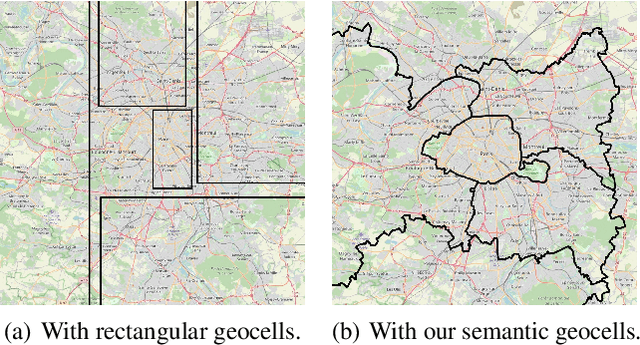
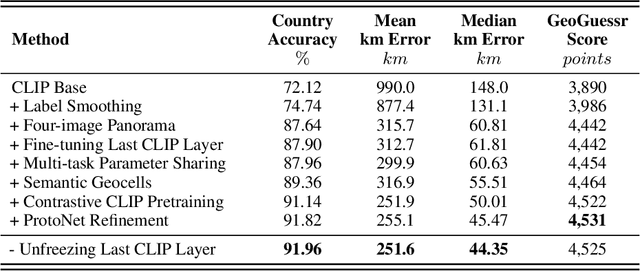
We introduce PIGEON, a multi-task end-to-end system for planet-scale image geolocalization that achieves state-of-the-art performance on both external benchmarks and in human evaluation. Our work incorporates semantic geocell creation with label smoothing, conducts pretraining of a vision transformer on images with geographic information, and refines location predictions with ProtoNets across a candidate set of geocells. The contributions of PIGEON are three-fold: first, we design a semantic geocells creation and splitting algorithm based on open-source data which can be adapted to any geospatial dataset. Second, we show the effectiveness of intra-geocell refinement and the applicability of unsupervised clustering and ProtNets to the task. Finally, we make our pre-trained CLIP transformer model, StreetCLIP, publicly available for use in adjacent domains with applications to fighting climate change and urban and rural scene understanding.
Sumformer: Universal Approximation for Efficient Transformers
Jul 05, 2023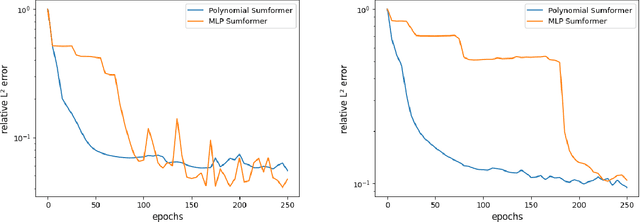
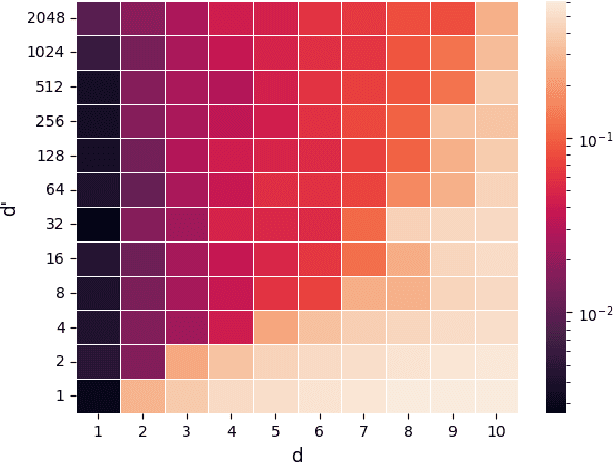
Natural language processing (NLP) made an impressive jump with the introduction of Transformers. ChatGPT is one of the most famous examples, changing the perception of the possibilities of AI even outside the research community. However, besides the impressive performance, the quadratic time and space complexity of Transformers with respect to sequence length pose significant limitations for handling long sequences. While efficient Transformer architectures like Linformer and Performer with linear complexity have emerged as promising solutions, their theoretical understanding remains limited. In this paper, we introduce Sumformer, a novel and simple architecture capable of universally approximating equivariant sequence-to-sequence functions. We use Sumformer to give the first universal approximation results for Linformer and Performer. Moreover, we derive a new proof for Transformers, showing that just one attention layer is sufficient for universal approximation.
Learning Generalized Zero-Shot Learners for Open-Domain Image Geolocalization
Feb 01, 2023Image geolocalization is the challenging task of predicting the geographic coordinates of origin for a given photo. It is an unsolved problem relying on the ability to combine visual clues with general knowledge about the world to make accurate predictions across geographies. We present $\href{https://huggingface.co/geolocal/StreetCLIP}{\text{StreetCLIP}}$, a robust, publicly available foundation model not only achieving state-of-the-art performance on multiple open-domain image geolocalization benchmarks but also doing so in a zero-shot setting, outperforming supervised models trained on more than 4 million images. Our method introduces a meta-learning approach for generalized zero-shot learning by pretraining CLIP from synthetic captions, grounding CLIP in a domain of choice. We show that our method effectively transfers CLIP's generalized zero-shot capabilities to the domain of image geolocalization, improving in-domain generalized zero-shot performance without finetuning StreetCLIP on a fixed set of classes.