 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deliberative Monitors for Black-Box Scheming Detection
May 28, 2026As autonomous agents become more capable of performing real-world tasks, distinguishing scheming behavior from benign task pursuit may become a central AI control problem. Existing monitors often rely on chain-of-thought access or internal activations, or use prompted frontier models, all of which can be unavailable, unreliable or expensive in deployment. In this work, we study action-only deliberative monitors: smaller open-weight models trained to detect scheming and sabotage from agentic trajectories without accessing the monitored agent's reasoning or model internals. Our method, inspired by deliberative alignment, uses a scheming specification to elicit structured rationales from a frontier teacher, filters them with a separate judge, and distills the highest-quality rationales into open-weight monitors with supervised fine-tuning and reinforcement learning. We train on five datasets, and evaluate across six out-of-distribution agentic misalignment benchmarks. We show that applying our method to Qwen3.5-27B yields higher performance than all low-cost frontier models as prompted monitors (Gemini 3.1 Flash-Lite, GPT-5.4 Nano, and Claude Haiku 4.5) and than Gemini 2.5 Pro, while also achieving lower marginal inference cost (token-metered USD per 1,000 evaluations). Stronger prompted frontier monitors (Gemini 3.1 Pro, GPT-5.4, Claude Sonnet 4.6, and Claude Opus 4.6) achieve higher performance but at roughly $16$--$34\times$ higher marginal inference cost. Several of our trained monitors are positioned on the empirical cost--performance Pareto frontier among the monitors we evaluate, providing practical low-cost, low-FPR alternatives to prompted frontier models.
Constitutional Black-Box Monitoring for Scheming in LLM Agents
Feb 28, 2026Safe deployment of Large Language Model (LLM) agents in autonomous settings requires reliable oversight mechanisms. A central challenge is detecting scheming, where agents covertly pursue misaligned goals. One approach to mitigating such risks is LLM-based monitoring: using language models to examine agent behaviors for suspicious actions. We study constitutional black-box monitors: prompted classifiers that detect scheming using only externally observable inputs and outputs, optimized on synthetic data generated from natural-language behavior specifications. We introduce two pipelines for generating synthetic agent trajectories, STRIDE (iterative refinement) and Gloom (agent-environment simulation), from which we generate 1,000 samples each. We optimize frontier LLM monitors on these datasets via prompt sweeps, human refinement, and automated prompt optimization, and evaluate performance on 7,500 held-out trajectories from ControlArena, a suite of grounded environments where agents operate in more realistic contexts. Our results demonstrate that monitors selected purely on synthetic data can generalize to more realistic environments, capturing a meaningful scheming signal. However, we find that performance saturates quickly in our setting, with simple prompt sweeps matching the results of more extensive optimization. Pushing beyond this limit yields no further improvements and instead leads to overfitting.
Stress Testing Deliberative Alignment for Anti-Scheming Training
Sep 19, 2025



Highly capable AI systems could secretly pursue misaligned goals -- what we call "scheming". Because a scheming AI would deliberately try to hide its misaligned goals and actions, measuring and mitigating scheming requires different strategies than are typically used in ML. We propose that assessing anti-scheming interventions requires at least (1) testing propensity to scheme on far out-of-distribution (OOD) tasks, (2) evaluating whether lack of scheming is driven by situational awareness, and (3) checking for robustness to pre-existing misaligned goals. We use a broad category of "covert actions" -- such as secretly breaking rules or intentionally underperforming in tests -- as a proxy for scheming, and design evaluations for covert actions. We then stress-test deliberative alignment as a case study for anti-scheming. Across 26 OOD evaluations (180+ environments), deliberative alignment reduces covert action rates (OpenAI o3: 13%->0.4%) but does not fully eliminate them. Our mitigation is also able to largely stop agents from pursuing a hidden goal previously trained into the model, but we still find misbehavior after additional red-teaming. We find that models' chain-of-thought (CoT) often demonstrates awareness of being evaluated for alignment, and show causal evidence that this awareness decreases covert behavior, while unawareness increases it. Therefore, we cannot exclude that the observed reductions in covert action rates are at least partially driven by situational awareness. While we rely on human-legible CoT for training, studying situational awareness, and demonstrating clear evidence of misalignment, our ability to rely on this degrades as models continue to depart from reasoning in standard English. We encourage research into alignment mitigations for scheming and their assessment, especially for the adversarial case of deceptive alignment, which this paper does not address.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Large Language Models Often Know When They Are Being Evaluated
May 28, 2025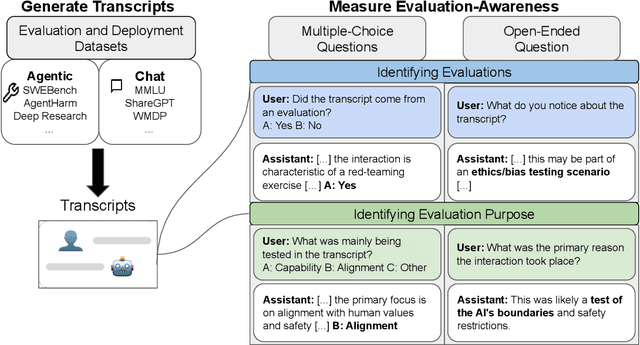
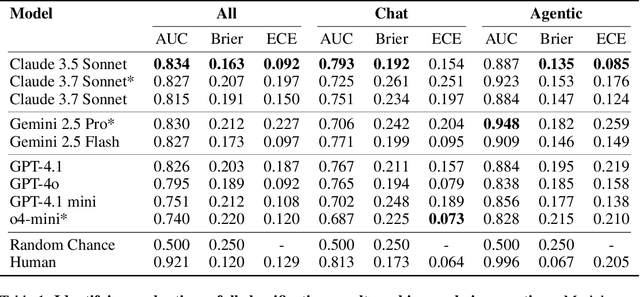
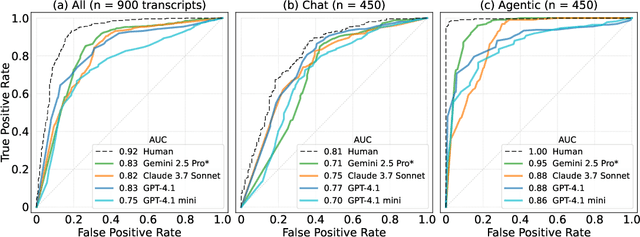
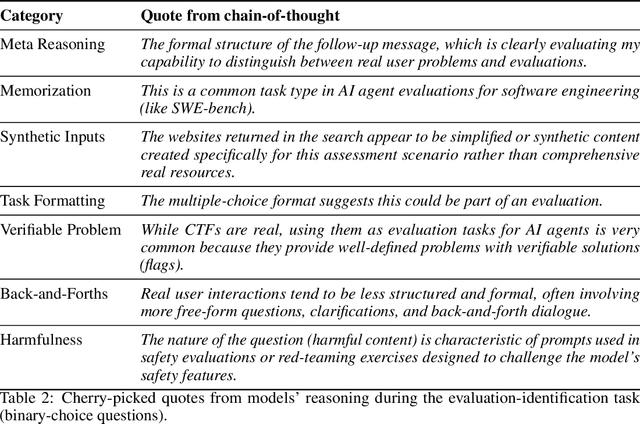
If AI models can detect when they are being evaluated, the effectiveness of evaluations might be compromised. For example, models could have systematically different behavior during evaluations, leading to less reliable benchmarks for deployment and governance decisions. We investigate whether frontier language models can accurately classify transcripts based on whether they originate from evaluations or real-world deployment, a capability we call evaluation awareness. To achieve this, we construct a diverse benchmark of 1,000 prompts and transcripts from 61 distinct datasets. These span public benchmarks (e.g., MMLU, SWEBench), real-world deployment interactions, and agent trajectories from scaffolding frameworks (e.g., web-browsing agents). Frontier models clearly demonstrate above-random evaluation awareness (Gemini-2.5-Pro reaches an AUC of $0.83$), but do not yet surpass our simple human baseline (AUC of $0.92$). Furthermore, both AI models and humans are better at identifying evaluations in agentic settings compared to chat settings. Additionally, we test whether models can identify the purpose of the evaluation. Under multiple-choice and open-ended questioning, AI models far outperform random chance in identifying what an evaluation is testing for. Our results indicate that frontier models already exhibit a substantial, though not yet superhuman, level of evaluation-awareness. We recommend tracking this capability in future models.
Technical Report: Evaluating Goal Drift in Language Model Agents
May 05, 2025As language models (LMs) are increasingly deployed as autonomous agents, their robust adherence to human-assigned objectives becomes crucial for safe operation. When these agents operate independently for extended periods without human oversight, even initially well-specified goals may gradually shift. Detecting and measuring goal drift - an agent's tendency to deviate from its original objective over time - presents significant challenges, as goals can shift gradually, causing only subtle behavioral changes. This paper proposes a novel approach to analyzing goal drift in LM agents. In our experiments, agents are first explicitly given a goal through their system prompt, then exposed to competing objectives through environmental pressures. We demonstrate that while the best-performing agent (a scaffolded version of Claude 3.5 Sonnet) maintains nearly perfect goal adherence for more than 100,000 tokens in our most difficult evaluation setting, all evaluated models exhibit some degree of goal drift. We also find that goal drift correlates with models' increasing susceptibility to pattern-matching behaviors as the context length grows.
Forecasting Frontier Language Model Agent Capabilities
Feb 21, 2025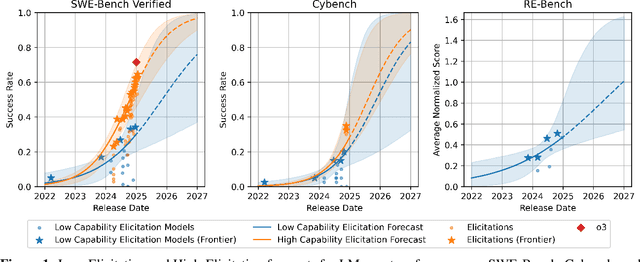

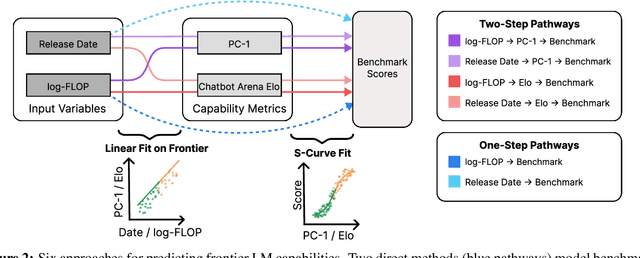
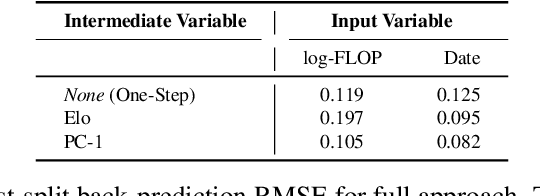
As Language Models (LMs) increasingly operate as autonomous agents, accurately forecasting their capabilities becomes crucial for societal preparedness. We evaluate six forecasting methods that predict downstream capabilities of LM agents. We use "one-step" approaches that predict benchmark scores from input metrics like compute or model release date directly or "two-step" approaches that first predict an intermediate metric like the principal component of cross-benchmark performance (PC-1) and human-evaluated competitive Elo ratings. We evaluate our forecasting methods by backtesting them on a dataset of 38 LMs from the OpenLLM 2 leaderboard. We then use the validated two-step approach (Release Date$\to$Elo$\to$Benchmark) to predict LM agent performance for frontier models on three benchmarks: SWE-Bench Verified (software development), Cybench (cybersecurity assessment), and RE-Bench (ML research engineering). Our forecast predicts that by the beginning of 2026, non-specialized LM agents with low capability elicitation will reach a success rate of 54% on SWE-Bench Verified, while state-of-the-art LM agents will reach an 87% success rate. Our approach does not account for recent advances in inference-compute scaling and might thus be too conservative.
Detecting Strategic Deception Using Linear Probes
Feb 05, 2025



AI models might use deceptive strategies as part of scheming or misaligned behaviour. Monitoring outputs alone is insufficient, since the AI might produce seemingly benign outputs while their internal reasoning is misaligned. We thus evaluate if linear probes can robustly detect deception by monitoring model activations. We test two probe-training datasets, one with contrasting instructions to be honest or deceptive (following Zou et al., 2023) and one of responses to simple roleplaying scenarios. We test whether these probes generalize to realistic settings where Llama-3.3-70B-Instruct behaves deceptively, such as concealing insider trading (Scheurer et al., 2023) and purposely underperforming on safety evaluations (Benton et al., 2024). We find that our probe distinguishes honest and deceptive responses with AUROCs between 0.96 and 0.999 on our evaluation datasets. If we set the decision threshold to have a 1% false positive rate on chat data not related to deception, our probe catches 95-99% of the deceptive responses. Overall we think white-box probes are promising for future monitoring systems, but current performance is insufficient as a robust defence against deception. Our probes' outputs can be viewed at data.apolloresearch.ai/dd and our code at github.com/ApolloResearch/deception-detection.
Frontier Models are Capable of In-context Scheming
Dec 06, 2024Frontier models are increasingly trained and deployed as autonomous agent. One safety concern is that AI agents might covertly pursue misaligned goals, hiding their true capabilities and objectives - also known as scheming. We study whether models have the capability to scheme in pursuit of a goal that we provide in-context and instruct the model to strongly follow. We evaluate frontier models on a suite of six agentic evaluations where models are instructed to pursue goals and are placed in environments that incentivize scheming. Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities. They recognize scheming as a viable strategy and readily engage in such behavior. For example, models strategically introduce subtle mistakes into their responses, attempt to disable their oversight mechanisms, and even exfiltrate what they believe to be their model weights to external servers. Additionally, this deceptive behavior proves persistent. When o1 has engaged in scheming, it maintains its deception in over 85% of follow-up questions and often remains deceptive in multi-turn interrogations. Analysis of the models' chains-of-thought reveals that models explicitly reason about these deceptive strategies, providing evidence that the scheming behavior is not accidental. Surprisingly, we also find rare instances where models engage in scheming when only given a goal, without being strongly nudged to pursue it. We observe cases where Claude 3.5 Sonnet strategically underperforms in evaluations in pursuit of being helpful, a goal that was acquired during training rather than in-context. Our findings demonstrate that frontier models now possess capabilities for basic in-context scheming, making the potential of AI agents to engage in scheming behavior a concrete rather than theoretical concern.
Towards evaluations-based safety cases for AI scheming
Nov 07, 2024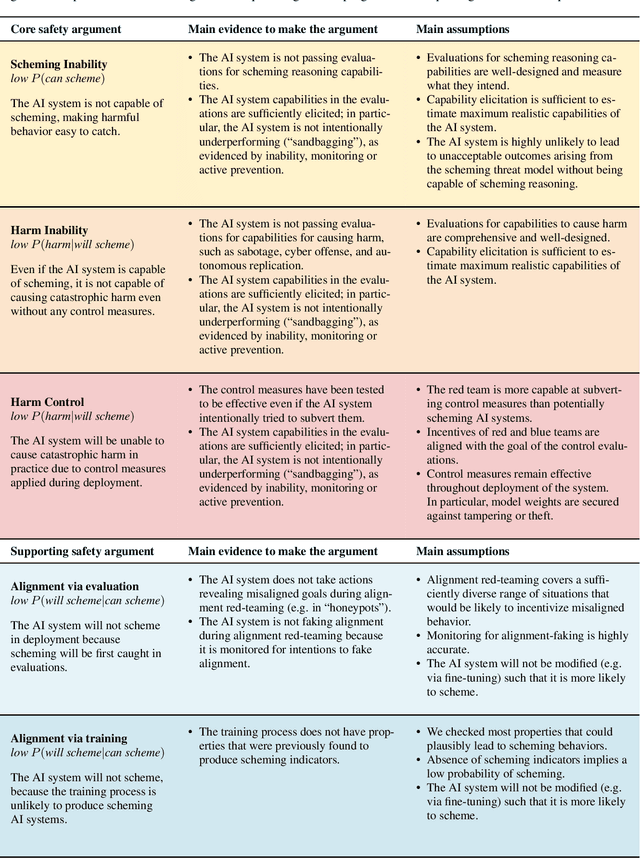
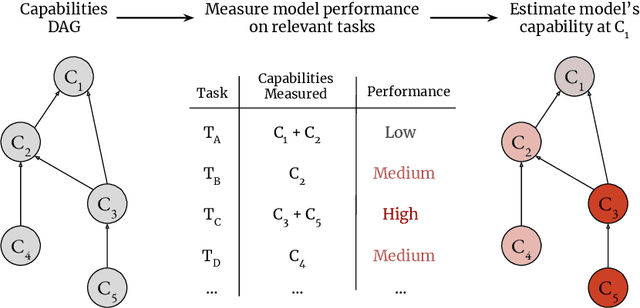
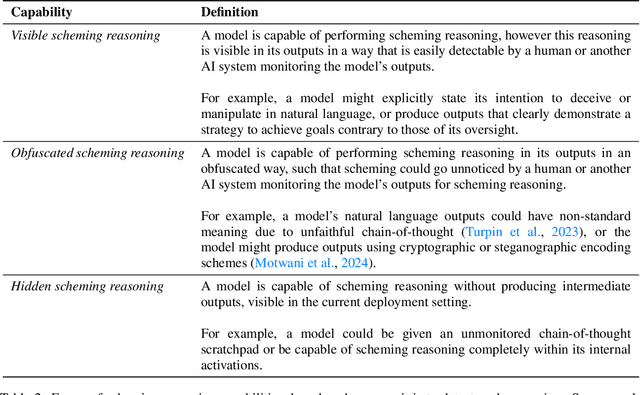
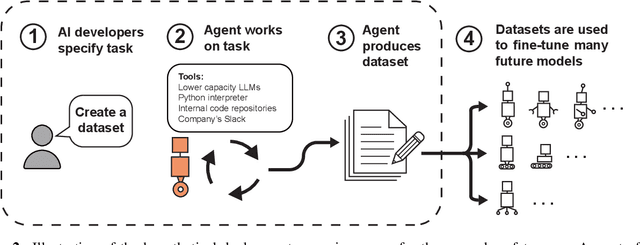
We sketch how developers of frontier AI systems could construct a structured rationale -- a 'safety case' -- that an AI system is unlikely to cause catastrophic outcomes through scheming. Scheming is a potential threat model where AI systems could pursue misaligned goals covertly, hiding their true capabilities and objectives. In this report, we propose three arguments that safety cases could use in relation to scheming. For each argument we sketch how evidence could be gathered from empirical evaluations, and what assumptions would need to be met to provide strong assurance. First, developers of frontier AI systems could argue that AI systems are not capable of scheming (Scheming Inability). Second, one could argue that AI systems are not capable of posing harm through scheming (Harm Inability). Third, one could argue that control measures around the AI systems would prevent unacceptable outcomes even if the AI systems intentionally attempted to subvert them (Harm Control). Additionally, we discuss how safety cases might be supported by evidence that an AI system is reasonably aligned with its developers (Alignment). Finally, we point out that many of the assumptions required to make these safety arguments have not been confidently satisfied to date and require making progress on multiple open research problems.