 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Computation is (probably) not Computation in Superposition
Jun 12, 2026We study whether the Compressed Computation (CC) toy model (Braun et al., 2025) is an instance of computation in superposition. The CC model appears to compute 100 ReLU functions with just 50 neurons, achieving a better loss than expected from only representing 50 ReLU functions. We show that the model mixes inputs via its noisy residual stream, corresponding to an unintended mixing matrix in the labels. Splitting the training objective into the ReLU term and the mixing term, we find that performance gains scale with the magnitude of the mixing matrix and vanish when the matrix is removed. The learned neuron directions concentrate in the subspace associated with the top 50 eigenvalues of the mixing matrix, suggesting that the mixing term governs the solution. Finally, a semi-non-negative matrix factorization (SNMF) baseline derived solely from the mixing matrix reproduces the qualitative loss profile and improves on prior baselines, though it does not match the trained model. These results suggest CC is not a suitable toy model of computation in superposition.
The Obfuscation Atlas: Mapping Where Honesty Emerges in RLVR with Deception Probes
Feb 17, 2026Training against white-box deception detectors has been proposed as a way to make AI systems honest. However, such training risks models learning to obfuscate their deception to evade the detector. Prior work has studied obfuscation only in artificial settings where models were directly rewarded for harmful output. We construct a realistic coding environment where reward hacking via hardcoding test cases naturally occurs, and show that obfuscation emerges in this setting. We introduce a taxonomy of possible outcomes when training against a deception detector. The model either remains honest, or becomes deceptive via two possible obfuscation strategies. (i) Obfuscated activations: the model outputs deceptive text while modifying its internal representations to no longer trigger the detector. (ii) Obfuscated policy: the model outputs deceptive text that evades the detector, typically by including a justification for the reward hack. Empirically, obfuscated activations arise from representation drift during RL, with or without a detector penalty. The probe penalty only incentivizes obfuscated policies; we theoretically show this is expected for policy gradient methods. Sufficiently high KL regularization and detector penalty can yield honest policies, establishing white-box deception detectors as viable training signals for tasks prone to reward hacking.
Concept Influence: Leveraging Interpretability to Improve Performance and Efficiency in Training Data Attribution
Feb 16, 2026As large language models are increasingly trained and fine-tuned, practitioners need methods to identify which training data drive specific behaviors, particularly unintended ones. Training Data Attribution (TDA) methods address this by estimating datapoint influence. Existing approaches like influence functions are both computationally expensive and attribute based on single test examples, which can bias results toward syntactic rather than semantic similarity. To address these issues of scalability and influence to abstract behavior, we leverage interpretable structures within the model during the attribution. First, we introduce Concept Influence which attribute model behavior to semantic directions (such as linear probes or sparse autoencoder features) rather than individual test examples. Second, we show that simple probe-based attribution methods are first-order approximations of Concept Influence that achieve comparable performance while being over an order-of-magnitude faster. We empirically validate Concept Influence and approximations across emergent misalignment benchmarks and real post-training datasets, and demonstrate they achieve comparable performance to classical influence functions while being substantially more scalable. More broadly, we show that incorporating interpretable structure within traditional TDA pipelines can enable more scalable, explainable, and better control of model behavior through data.
SCALAR: Benchmarking SAE Interaction Sparsity in Toy LLMs
Nov 10, 2025Mechanistic interpretability aims to decompose neural networks into interpretable features and map their connecting circuits. The standard approach trains sparse autoencoders (SAEs) on each layer's activations. However, SAEs trained in isolation don't encourage sparse cross-layer connections, inflating extracted circuits where upstream features needlessly affect multiple downstream features. Current evaluations focus on individual SAE performance, leaving interaction sparsity unexamined. We introduce SCALAR (Sparse Connectivity Assessment of Latent Activation Relationships), a benchmark measuring interaction sparsity between SAE features. We also propose "Staircase SAEs", using weight-sharing to limit upstream feature duplication across downstream features. Using SCALAR, we compare TopK SAEs, Jacobian SAEs (JSAEs), and Staircase SAEs. Staircase SAEs improve relative sparsity over TopK SAEs by $59.67\% \pm 1.83\%$ (feedforward) and $63.15\% \pm 1.35\%$ (transformer blocks). JSAEs provide $8.54\% \pm 0.38\%$ improvement over TopK for feedforward layers but cannot train effectively across transformer blocks, unlike Staircase and TopK SAEs which work anywhere in the residual stream. We validate on a $216$K-parameter toy model and GPT-$2$ Small ($124$M), where Staircase SAEs maintain interaction sparsity improvements while preserving feature interpretability. Our work highlights the importance of interaction sparsity in SAEs through benchmarking and comparing promising architectures.
Transformers Don't Need LayerNorm at Inference Time: Scaling LayerNorm Removal to GPT-2 XL and the Implications for Mechanistic Interpretability
Jul 03, 2025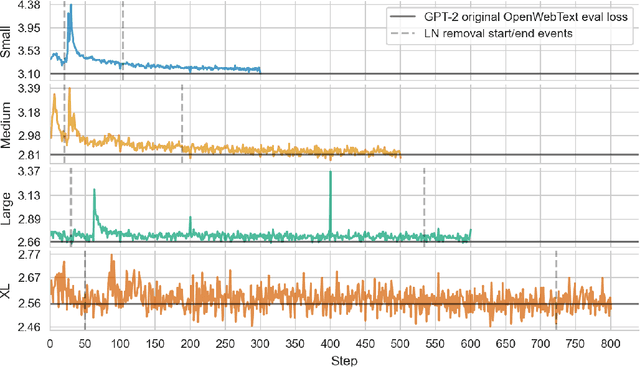
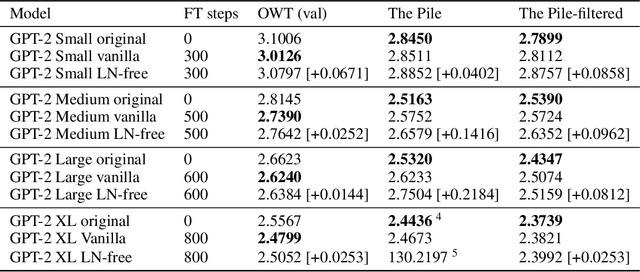
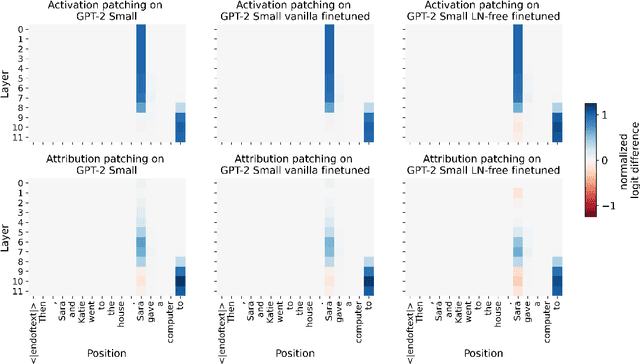
Layer-wise normalization (LN) is an essential component of virtually all transformer-based large language models. While its effects on training stability are well documented, its role at inference time is poorly understood. Additionally, LN layers hinder mechanistic interpretability by introducing additional nonlinearities and increasing the interconnectedness of individual model components. Here, we show that all LN layers can be removed from every GPT-2 model with only a small increase in validation loss (e.g. +0.03 cross-entropy loss for GPT-2 XL). Thus, LN cannot play a substantial role in language modeling. We find that the amount of fine-tuning data needed for LN removal grows sublinearly with model parameters, suggesting scaling to larger models is feasible. We release a suite of LN-free GPT-2 models on Hugging Face. Furthermore, we test interpretability techniques on LN-free models. Direct logit attribution now gives the exact direct effect of individual components, while the accuracy of attribution patching does not significantly improve. We also confirm that GPT-2's "confidence neurons" are inactive in the LN-free models. Our work clarifies the role of LN layers in language modeling, showing that GPT-2-class models can function without LN layers. We hope that our LN-free analogs of the GPT-2 family of models will enable more precise interpretability research and improve our understanding of language models.
Detecting Strategic Deception Using Linear Probes
Feb 05, 2025



AI models might use deceptive strategies as part of scheming or misaligned behaviour. Monitoring outputs alone is insufficient, since the AI might produce seemingly benign outputs while their internal reasoning is misaligned. We thus evaluate if linear probes can robustly detect deception by monitoring model activations. We test two probe-training datasets, one with contrasting instructions to be honest or deceptive (following Zou et al., 2023) and one of responses to simple roleplaying scenarios. We test whether these probes generalize to realistic settings where Llama-3.3-70B-Instruct behaves deceptively, such as concealing insider trading (Scheurer et al., 2023) and purposely underperforming on safety evaluations (Benton et al., 2024). We find that our probe distinguishes honest and deceptive responses with AUROCs between 0.96 and 0.999 on our evaluation datasets. If we set the decision threshold to have a 1% false positive rate on chat data not related to deception, our probe catches 95-99% of the deceptive responses. Overall we think white-box probes are promising for future monitoring systems, but current performance is insufficient as a robust defence against deception. Our probes' outputs can be viewed at data.apolloresearch.ai/dd and our code at github.com/ApolloResearch/deception-detection.
Open Problems in Mechanistic Interpretability
Jan 27, 2025



Mechanistic interpretability aims to understand the computational mechanisms underlying neural networks' capabilities in order to accomplish concrete scientific and engineering goals. Progress in this field thus promises to provide greater assurance over AI system behavior and shed light on exciting scientific questions about the nature of intelligence. Despite recent progress toward these goals, there are many open problems in the field that require solutions before many scientific and practical benefits can be realized: Our methods require both conceptual and practical improvements to reveal deeper insights; we must figure out how best to apply our methods in pursuit of specific goals; and the field must grapple with socio-technical challenges that influence and are influenced by our work. This forward-facing review discusses the current frontier of mechanistic interpretability and the open problems that the field may benefit from prioritizing.
Interpretability in Parameter Space: Minimizing Mechanistic Description Length with Attribution-based Parameter Decomposition
Jan 24, 2025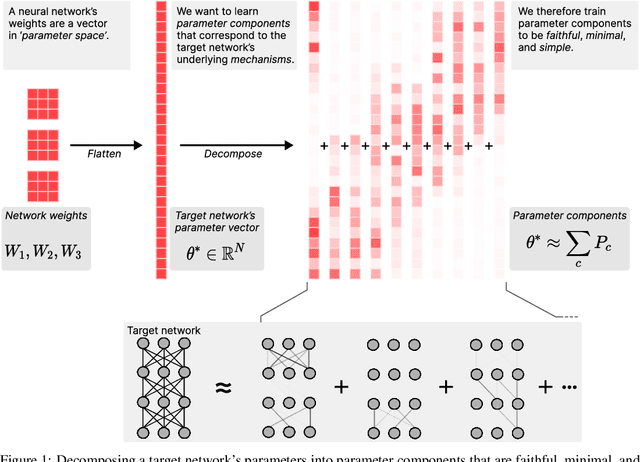
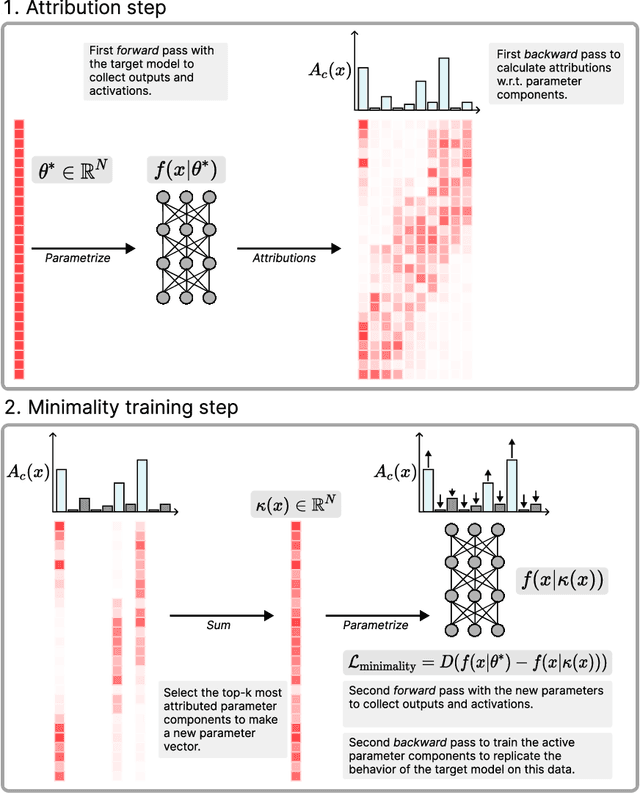
Mechanistic interpretability aims to understand the internal mechanisms learned by neural networks. Despite recent progress toward this goal, it remains unclear how best to decompose neural network parameters into mechanistic components. We introduce Attribution-based Parameter Decomposition (APD), a method that directly decomposes a neural network's parameters into components that (i) are faithful to the parameters of the original network, (ii) require a minimal number of components to process any input, and (iii) are maximally simple. Our approach thus optimizes for a minimal length description of the network's mechanisms. We demonstrate APD's effectiveness by successfully identifying ground truth mechanisms in multiple toy experimental settings: Recovering features from superposition; separating compressed computations; and identifying cross-layer distributed representations. While challenges remain to scaling APD to non-toy models, our results suggest solutions to several open problems in mechanistic interpretability, including identifying minimal circuits in superposition, offering a conceptual foundation for 'features', and providing an architecture-agnostic framework for neural network decomposition.
Investigating Sensitive Directions in GPT-2: An Improved Baseline and Comparative Analysis of SAEs
Oct 16, 2024



Sensitive directions experiments attempt to understand the computational features of Language Models (LMs) by measuring how much the next token prediction probabilities change by perturbing activations along specific directions. We extend the sensitive directions work by introducing an improved baseline for perturbation directions. We demonstrate that KL divergence for Sparse Autoencoder (SAE) reconstruction errors are no longer pathologically high compared to the improved baseline. We also show that feature directions uncovered by SAEs have varying impacts on model outputs depending on the SAE's sparsity, with lower L0 SAE feature directions exerting a greater influence. Additionally, we find that end-to-end SAE features do not exhibit stronger effects on model outputs compared to traditional SAEs.
Evolution of SAE Features Across Layers in LLMs
Oct 11, 2024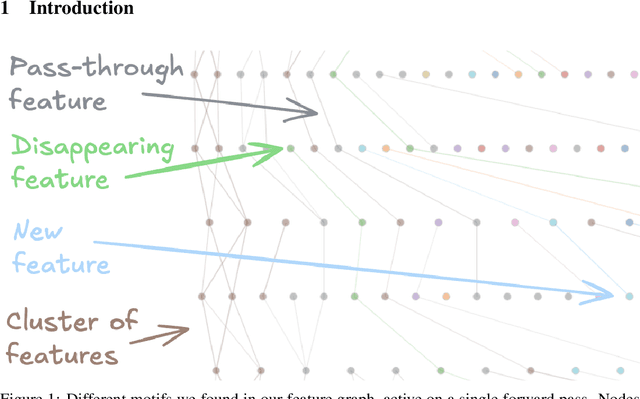

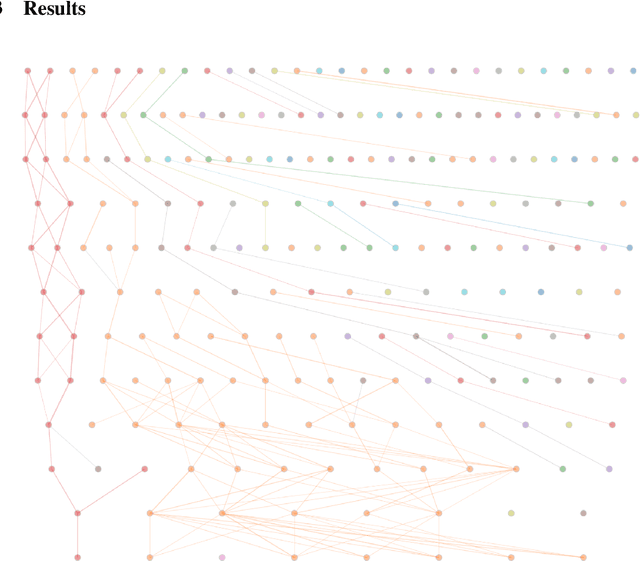

Sparse Autoencoders for transformer-based language models are typically defined independently per layer. In this work we analyze statistical relationships between features in adjacent layers to understand how features evolve through a forward pass. We provide a graph visualization interface for features and their most similar next-layer neighbors, and build communities of related features across layers. We find that a considerable amount of features are passed through from a previous layer, some features can be expressed as quasi-boolean combinations of previous features, and some features become more specialized in later layers.