 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Circuit Discovery for Mechanistic Interpretability
Paper and Code
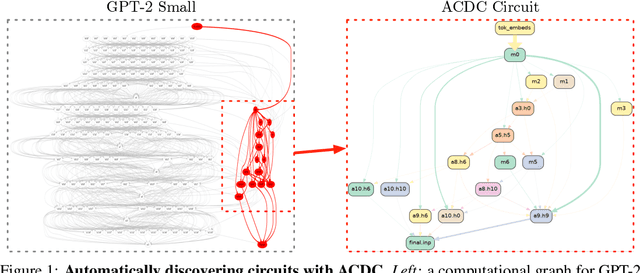

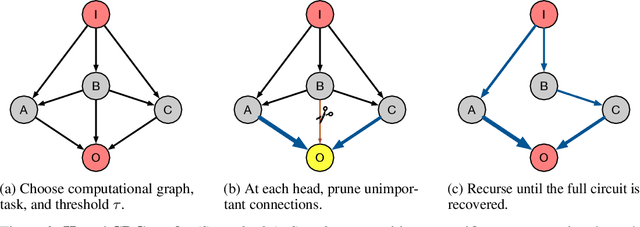
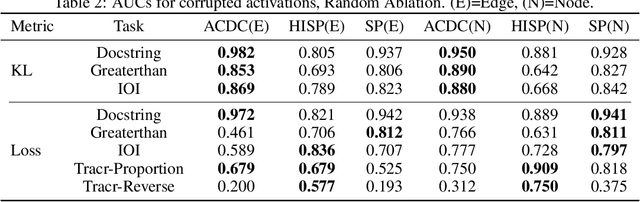
Recent work in mechanistic interpretability has reverse-engineered nontrivial behaviors of transformer models. These contributions required considerable effort and researcher intuition, which makes it difficult to apply the same methods to understand the complex behavior that current models display. At their core however, the workflow for these discoveries is surprisingly similar. Researchers create a data set and metric that elicit the desired model behavior, subdivide the network into appropriate abstract units, replace activations of those units to identify which are involved in the behavior, and then interpret the functions that these units implement. By varying the data set, metric, and units under investigation, researchers can understand the functionality of each neural network region and the circuits they compose. This work proposes a novel algorithm, Automatic Circuit DisCovery (ACDC), to automate the identification of the important units in the network. Given a model's computational graph, ACDC finds subgraphs that explain a behavior of the model. ACDC was able to reproduce a previously identified circuit for Python docstrings in a small transformer, identifying 6/7 important attention heads that compose up to 3 layers deep, while including 91% fewer the connections.