 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Answers Before Chain-of-Thought: Evidence from Pre-CoT Probes and Activation Steering
Mar 02, 2026As chain-of-thought (CoT) has become central to scaling reasoning capabilities in large language models (LLMs), it has also emerged as a promising tool for interpretability, suggesting the opportunity to understand model decisions through verbalized reasoning. However, the utility of CoT toward interpretability depends upon its faithfulness -- whether the model's stated reasoning reflects the underlying decision process. We provide mechanistic evidence that instruction-tuned models often determine their answer before generating CoT. Training linear probes on residual stream activations at the last token before CoT, we can predict the model's final answer with 0.9 AUC on most tasks. We find that these directions are not only predictive, but also causal: steering activations along the probe direction flips model answers in over 50% of cases, significantly exceeding orthogonal baselines. When steering induces incorrect answers, we observe two distinct failure modes: non-entailment (stating correct premises but drawing unsupported conclusions) and confabulation (fabricating false premises). While post-hoc reasoning may be instrumentally useful when the model has a correct pre-CoT belief, these failure modes suggest it can result in undesirable behaviors when reasoning from a false belief.
SynthSAEBench: Evaluating Sparse Autoencoders on Scalable Realistic Synthetic Data
Feb 16, 2026Improving Sparse Autoencoders (SAEs) requires benchmarks that can precisely validate architectural innovations. However, current SAE benchmarks on LLMs are often too noisy to differentiate architectural improvements, and current synthetic data experiments are too small-scale and unrealistic to provide meaningful comparisons. We introduce SynthSAEBench, a toolkit for generating large-scale synthetic data with realistic feature characteristics including correlation, hierarchy, and superposition, and a standardized benchmark model, SynthSAEBench-16k, enabling direct comparison of SAE architectures. Our benchmark reproduces several previously observed LLM SAE phenomena, including the disconnect between reconstruction and latent quality metrics, poor SAE probing results, and a precision-recall trade-off mediated by L0. We further use our benchmark to identify a new failure mode: Matching Pursuit SAEs exploit superposition noise to improve reconstruction without learning ground-truth features, suggesting that more expressive encoders can easily overfit. SynthSAEBench complements LLM benchmarks by providing ground-truth features and controlled ablations, enabling researchers to precisely diagnose SAE failure modes and validate architectural improvements before scaling to LLMs.
Biases in the Blind Spot: Detecting What LLMs Fail to Mention
Feb 11, 2026Large Language Models (LLMs) often provide chain-of-thought (CoT) reasoning traces that appear plausible, but may hide internal biases. We call these *unverbalized biases*. Monitoring models via their stated reasoning is therefore unreliable, and existing bias evaluations typically require predefined categories and hand-crafted datasets. In this work, we introduce a fully automated, black-box pipeline for detecting task-specific unverbalized biases. Given a task dataset, the pipeline uses LLM autoraters to generate candidate bias concepts. It then tests each concept on progressively larger input samples by generating positive and negative variations, and applies statistical techniques for multiple testing and early stopping. A concept is flagged as an unverbalized bias if it yields statistically significant performance differences while not being cited as justification in the model's CoTs. We evaluate our pipeline across six LLMs on three decision tasks (hiring, loan approval, and university admissions). Our technique automatically discovers previously unknown biases in these models (e.g., Spanish fluency, English proficiency, writing formality). In the same run, the pipeline also validates biases that were manually identified by prior work (gender, race, religion, ethnicity). More broadly, our proposed approach provides a practical, scalable path to automatic task-specific bias discovery.
Interpreting learned search: finding a transition model and value function in an RNN that plays Sokoban
Jun 11, 2025


We partially reverse-engineer a convolutional recurrent neural network (RNN) trained to play the puzzle game Sokoban with model-free reinforcement learning. Prior work found that this network solves more levels with more test-time compute. Our analysis reveals several mechanisms analogous to components of classic bidirectional search. For each square, the RNN represents its plan in the activations of channels associated with specific directions. These state-action activations are analogous to a value function - their magnitudes determine when to backtrack and which plan branch survives pruning. Specialized kernels extend these activations (containing plan and value) forward and backward to create paths, forming a transition model. The algorithm is also unlike classical search in some ways. State representation is not unified; instead, the network considers each box separately. Each layer has its own plan representation and value function, increasing search depth. Far from being inscrutable, the mechanisms leveraging test-time compute learned in this network by model-free training can be understood in familiar terms.
Feature Hedging: Correlated Features Break Narrow Sparse Autoencoders
May 16, 2025



It is assumed that sparse autoencoders (SAEs) decompose polysemantic activations into interpretable linear directions, as long as the activations are composed of sparse linear combinations of underlying features. However, we find that if an SAE is more narrow than the number of underlying "true features" on which it is trained, and there is correlation between features, the SAE will merge components of correlated features together, thus destroying monosemanticity. In LLM SAEs, these two conditions are almost certainly true. This phenomenon, which we call feature hedging, is caused by SAE reconstruction loss, and is more severe the narrower the SAE. In this work, we introduce the problem of feature hedging and study it both theoretically in toy models and empirically in SAEs trained on LLMs. We suspect that feature hedging may be one of the core reasons that SAEs consistently underperform supervised baselines. Finally, we use our understanding of feature hedging to propose an improved variant of matryoshka SAEs. Our work shows there remain fundamental issues with SAEs, but we are hopeful that that highlighting feature hedging will catalyze future advances that allow SAEs to achieve their full potential of interpreting LLMs at scale.
Among Us: A Sandbox for Agentic Deception
Apr 05, 2025



Studying deception in AI agents is important and difficult due to the lack of model organisms and sandboxes that elicit the behavior without asking the model to act under specific conditions or inserting intentional backdoors. Extending upon $\textit{AmongAgents}$, a text-based social-deduction game environment, we aim to fix this by introducing Among Us as a rich sandbox where LLM-agents exhibit human-style deception naturally while they think, speak, and act with other agents or humans. We introduce Deception ELO as an unbounded measure of deceptive capability, suggesting that frontier models win more because they're better at deception, not at detecting it. We evaluate the effectiveness of AI safety techniques (LLM-monitoring of outputs, linear probes on various datasets, and sparse autoencoders) for detecting lying and deception in Among Us, and find that they generalize very well out-of-distribution. We open-source our sandbox as a benchmark for future alignment research and hope that this is a good testbed to improve safety techniques to detect and remove agentically-motivated deception, and to anticipate deceptive abilities in LLMs.
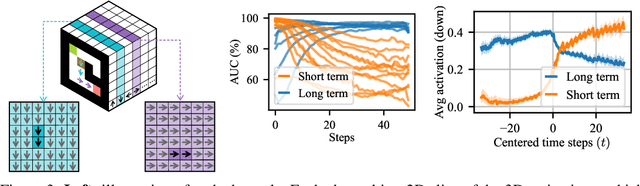
Interpreting Emergent Planning in Model-Free Reinforcement Learning
Apr 02, 2025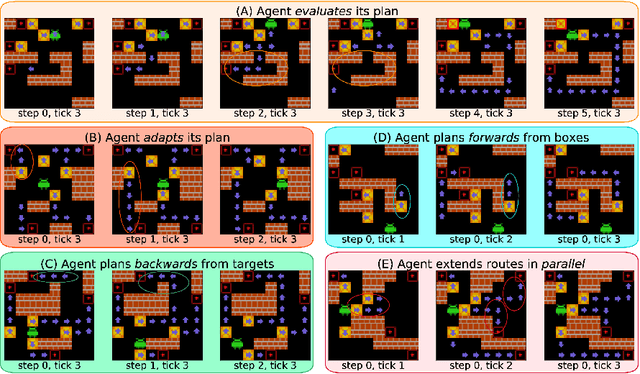


We present the first mechanistic evidence that model-free reinforcement learning agents can learn to plan. This is achieved by applying a methodology based on concept-based interpretability to a model-free agent in Sokoban -- a commonly used benchmark for studying planning. Specifically, we demonstrate that DRC, a generic model-free agent introduced by Guez et al. (2019), uses learned concept representations to internally formulate plans that both predict the long-term effects of actions on the environment and influence action selection. Our methodology involves: (1) probing for planning-relevant concepts, (2) investigating plan formation within the agent's representations, and (3) verifying that discovered plans (in the agent's representations) have a causal effect on the agent's behavior through interventions. We also show that the emergence of these plans coincides with the emergence of a planning-like property: the ability to benefit from additional test-time compute. Finally, we perform a qualitative analysis of the planning algorithm learned by the agent and discover a strong resemblance to parallelized bidirectional search. Our findings advance understanding of the internal mechanisms underlying planning behavior in agents, which is important given the recent trend of emergent planning and reasoning capabilities in LLMs through RL
Hypothesis Testing the Circuit Hypothesis in LLMs
Oct 16, 2024Large language models (LLMs) demonstrate surprising capabilities, but we do not understand how they are implemented. One hypothesis suggests that these capabilities are primarily executed by small subnetworks within the LLM, known as circuits. But how can we evaluate this hypothesis? In this paper, we formalize a set of criteria that a circuit is hypothesized to meet and develop a suite of hypothesis tests to evaluate how well circuits satisfy them. The criteria focus on the extent to which the LLM's behavior is preserved, the degree of localization of this behavior, and whether the circuit is minimal. We apply these tests to six circuits described in the research literature. We find that synthetic circuits -- circuits that are hard-coded in the model -- align with the idealized properties. Circuits discovered in Transformer models satisfy the criteria to varying degrees. To facilitate future empirical studies of circuits, we created the \textit{circuitry} package, a wrapper around the \textit{TransformerLens} library, which abstracts away lower-level manipulations of hooks and activations. The software is available at \url{https://github.com/blei-lab/circuitry}.
Planning behavior in a recurrent neural network that plays Sokoban
Jul 22, 2024To predict how advanced neural networks generalize to novel situations, it is essential to understand how they reason. Guez et al. (2019, "An investigation of model-free planning") trained a recurrent neural network (RNN) to play Sokoban with model-free reinforcement learning. They found that adding extra computation steps to the start of episodes at test time improves the RNN's success rate. We further investigate this phenomenon, finding that it rapidly emerges early on in training and then slowly fades, but only for comparatively easier levels. The RNN also often takes redundant actions at episode starts, and these are reduced by adding extra computation steps. Our results suggest that the RNN learns to take time to think by `pacing', despite the per-step penalties, indicating that training incentivizes planning capabilities. The small size (1.29M parameters) and interesting behavior of this model make it an excellent model organism for mechanistic interpretability.
Adversarial Circuit Evaluation
Jul 21, 2024Circuits are supposed to accurately describe how a neural network performs a specific task, but do they really? We evaluate three circuits found in the literature (IOI, greater-than, and docstring) in an adversarial manner, considering inputs where the circuit's behavior maximally diverges from the full model. Concretely, we measure the KL divergence between the full model's output and the circuit's output, calculated through resample ablation, and we analyze the worst-performing inputs. Our results show that the circuits for the IOI and docstring tasks fail to behave similarly to the full model even on completely benign inputs from the original task, indicating that more robust circuits are needed for safety-critical applications.