 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decision-Theoretic Formalisation of Steganography With Applications to LLM Monitoring
Feb 26, 2026Large language models are beginning to show steganographic capabilities. Such capabilities could allow misaligned models to evade oversight mechanisms. Yet principled methods to detect and quantify such behaviours are lacking. Classical definitions of steganography, and detection methods based on them, require a known reference distribution of non-steganographic signals. For the case of steganographic reasoning in LLMs, knowing such a reference distribution is not feasible; this renders these approaches inapplicable. We propose an alternative, \textbf{decision-theoretic view of steganography}. Our central insight is that steganography creates an asymmetry in usable information between agents who can and cannot decode the hidden content (present within a steganographic signal), and this otherwise latent asymmetry can be inferred from the agents' observable actions. To formalise this perspective, we introduce generalised $\mathcal{V}$-information: a utilitarian framework for measuring the amount of usable information within some input. We use this to define the \textbf{steganographic gap} -- a measure that quantifies steganography by comparing the downstream utility of the steganographic signal to agents that can and cannot decode the hidden content. We empirically validate our formalism, and show that it can be used to detect, quantify, and mitigate steganographic reasoning in LLMs.
Audio-Visual Feature Synchronization for Robust Speech Enhancement in Hearing Aids
Aug 26, 2025Audio-visual feature synchronization for real-time speech enhancement in hearing aids represents a progressive approach to improving speech intelligibility and user experience, particularly in strong noisy backgrounds. This approach integrates auditory signals with visual cues, utilizing the complementary description of these modalities to improve speech intelligibility. Audio-visual feature synchronization for real-time SE in hearing aids can be further optimized using an efficient feature alignment module. In this study, a lightweight cross-attentional model learns robust audio-visual representations by exploiting large-scale data and simple architecture. By incorporating the lightweight cross-attentional model in an AVSE framework, the neural system dynamically emphasizes critical features across audio and visual modalities, enabling defined synchronization and improved speech intelligibility. The proposed AVSE model not only ensures high performance in noise suppression and feature alignment but also achieves real-time processing with minimal latency (36ms) and energy consumption. Evaluations on the AVSEC3 dataset show the efficiency of the model, achieving significant gains over baselines in perceptual quality (PESQ:0.52), intelligibility (STOI:19\%), and fidelity (SI-SDR:10.10dB).
Interpreting Emergent Planning in Model-Free Reinforcement Learning
Apr 02, 2025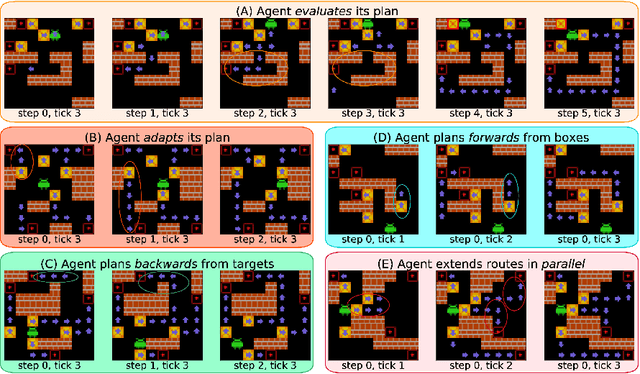

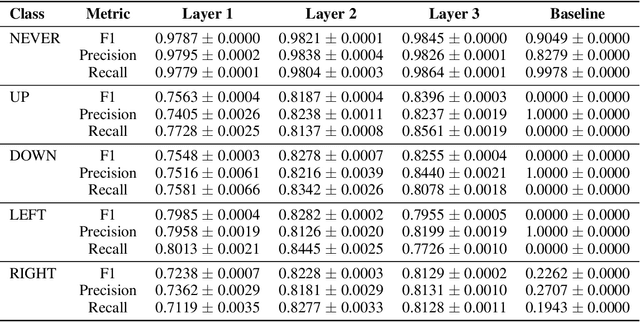

We present the first mechanistic evidence that model-free reinforcement learning agents can learn to plan. This is achieved by applying a methodology based on concept-based interpretability to a model-free agent in Sokoban -- a commonly used benchmark for studying planning. Specifically, we demonstrate that DRC, a generic model-free agent introduced by Guez et al. (2019), uses learned concept representations to internally formulate plans that both predict the long-term effects of actions on the environment and influence action selection. Our methodology involves: (1) probing for planning-relevant concepts, (2) investigating plan formation within the agent's representations, and (3) verifying that discovered plans (in the agent's representations) have a causal effect on the agent's behavior through interventions. We also show that the emergence of these plans coincides with the emergence of a planning-like property: the ability to benefit from additional test-time compute. Finally, we perform a qualitative analysis of the planning algorithm learned by the agent and discover a strong resemblance to parallelized bidirectional search. Our findings advance understanding of the internal mechanisms underlying planning behavior in agents, which is important given the recent trend of emergent planning and reasoning capabilities in LLMs through RL
The Reality of AI and Biorisk
Dec 02, 2024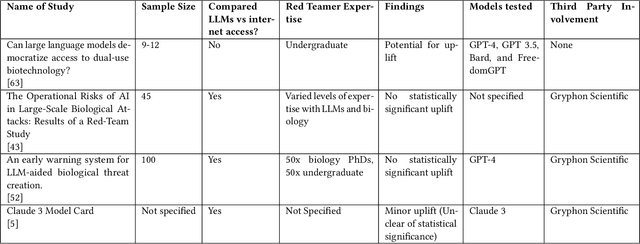
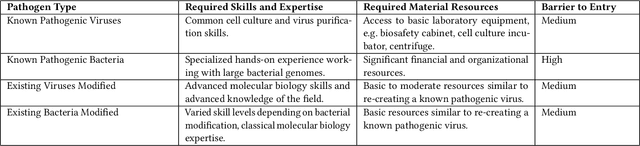
To accurately and confidently answer the question 'could an AI model or system increase biorisk', it is necessary to have both a sound theoretical threat model for how AI models or systems could increase biorisk and a robust method for testing that threat model. This paper provides an analysis of existing available research surrounding two AI and biorisk threat models: 1) access to information and planning via large language models (LLMs), and 2) the use of AI-enabled biological tools (BTs) in synthesizing novel biological artifacts. We find that existing studies around AI-related biorisk are nascent, often speculative in nature, or limited in terms of their methodological maturity and transparency. The available literature suggests that current LLMs and BTs do not pose an immediate risk, and more work is needed to develop rigorous approaches to understanding how future models could increase biorisks. We end with recommendations about how empirical work can be expanded to more precisely target biorisk and ensure rigor and validity of findings.
Learning to Forget using Hypernetworks
Dec 01, 2024



Machine unlearning is gaining increasing attention as a way to remove adversarial data poisoning attacks from already trained models and to comply with privacy and AI regulations. The objective is to unlearn the effect of undesired data from a trained model while maintaining performance on the remaining data. This paper introduces HyperForget, a novel machine unlearning framework that leverages hypernetworks - neural networks that generate parameters for other networks - to dynamically sample models that lack knowledge of targeted data while preserving essential capabilities. Leveraging diffusion models, we implement two Diffusion HyperForget Networks and used them to sample unlearned models in Proof-of-Concept experiments. The unlearned models obtained zero accuracy on the forget set, while preserving good accuracy on the retain sets, highlighting the potential of HyperForget for dynamic targeted data removal and a promising direction for developing adaptive machine unlearning algorithms.
Comparing Bottom-Up and Top-Down Steering Approaches on In-Context Learning Tasks
Nov 11, 2024



A key objective of interpretability research on large language models (LLMs) is to develop methods for robustly steering models toward desired behaviors. To this end, two distinct approaches to interpretability -- ``bottom-up" and ``top-down" -- have been presented, but there has been little quantitative comparison between them. We present a case study comparing the effectiveness of representative vector steering methods from each branch: function vectors (FV; arXiv:2310.15213), as a bottom-up method, and in-context vectors (ICV; arXiv:2311.06668) as a top-down method. While both aim to capture compact representations of broad in-context learning tasks, we find they are effective only on specific types of tasks: ICVs outperform FVs in behavioral shifting, whereas FVs excel in tasks requiring more precision. We discuss the implications for future evaluations of steering methods and for further research into top-down and bottom-up steering given these findings.
Noisy Zero-Shot Coordination: Breaking The Common Knowledge Assumption In Zero-Shot Coordination Games
Nov 07, 2024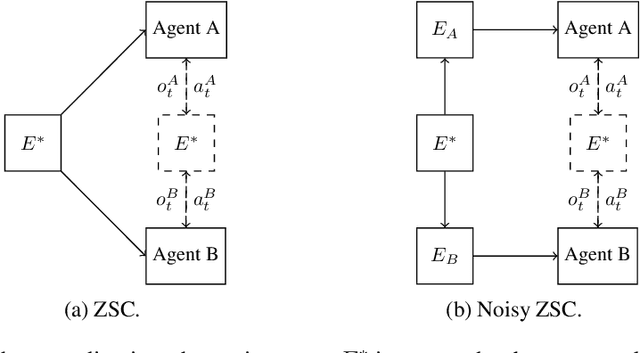

Zero-shot coordination (ZSC) is a popular setting for studying the ability of reinforcement learning (RL) agents to coordinate with novel partners. Prior ZSC formulations assume the $\textit{problem setting}$ is common knowledge: each agent knows the underlying Dec-POMDP, knows others have this knowledge, and so on ad infinitum. However, this assumption rarely holds in complex real-world settings, which are often difficult to fully and correctly specify. Hence, in settings where this common knowledge assumption is invalid, agents trained using ZSC methods may not be able to coordinate well. To address this limitation, we formulate the $\textit{noisy zero-shot coordination}$ (NZSC) problem. In NZSC, agents observe different noisy versions of the ground truth Dec-POMDP, which are assumed to be distributed according to a fixed noise model. Only the distribution of ground truth Dec-POMDPs and the noise model are common knowledge. We show that a NZSC problem can be reduced to a ZSC problem by designing a meta-Dec-POMDP with an augmented state space consisting of all the ground-truth Dec-POMDPs. For solving NZSC problems, we propose a simple and flexible meta-learning method called NZSC training, in which the agents are trained across a distribution of coordination problems - which they only get to observe noisy versions of. We show that with NZSC training, RL agents can be trained to coordinate well with novel partners even when the (exact) problem setting of the coordination is not common knowledge.
Adversarial Robustness of In-Context Learning in Transformers for Linear Regression
Nov 07, 2024Transformers have demonstrated remarkable in-context learning capabilities across various domains, including statistical learning tasks. While previous work has shown that transformers can implement common learning algorithms, the adversarial robustness of these learned algorithms remains unexplored. This work investigates the vulnerability of in-context learning in transformers to \textit{hijacking attacks} focusing on the setting of linear regression tasks. Hijacking attacks are prompt-manipulation attacks in which the adversary's goal is to manipulate the prompt to force the transformer to generate a specific output. We first prove that single-layer linear transformers, known to implement gradient descent in-context, are non-robust and can be manipulated to output arbitrary predictions by perturbing a single example in the in-context training set. While our experiments show these attacks succeed on linear transformers, we find they do not transfer to more complex transformers with GPT-2 architectures. Nonetheless, we show that these transformers can be hijacked using gradient-based adversarial attacks. We then demonstrate that adversarial training enhances transformers' robustness against hijacking attacks, even when just applied during finetuning. Additionally, we find that in some settings, adversarial training against a weaker attack model can lead to robustness to a stronger attack model. Lastly, we investigate the transferability of hijacking attacks across transformers of varying scales and initialization seeds, as well as between transformers and ordinary least squares (OLS). We find that while attacks transfer effectively between small-scale transformers, they show poor transferability in other scenarios (small-to-large scale, large-to-large scale, and between transformers and OLS).
IDs for AI Systems
Jun 17, 2024



AI systems are increasingly pervasive, yet information needed to decide whether and how to engage with them may not exist or be accessible. A user may not be able to verify whether a system satisfies certain safety standards. An investigator may not know whom to investigate when a system causes an incident. A platform may find it difficult to penalize repeated negative interactions with the same system. Across a number of domains, IDs address analogous problems by identifying \textit{particular} entities (e.g., a particular Boeing 747) and providing information about other entities of the same class (e.g., some or all Boeing 747s). We propose a framework in which IDs are ascribed to \textbf{instances} of AI systems (e.g., a particular chat session with Claude 3), and associated information is accessible to parties seeking to interact with that system. We characterize IDs for AI systems, argue that there could be significant demand for IDs from key actors, analyze how those actors could incentivize ID adoption, explore potential implementations of our framework, and highlight limitations and risks. IDs seem most warranted in high-stakes settings, where certain actors (e.g., those that enable AI systems to make financial transactions) could experiment with incentives for ID use. Deployers of AI systems could experiment with developing ID implementations. With further study, IDs could help to manage a world where AI systems pervade society.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.