 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfrastructure for AI Agents
Jan 17, 2025



Increasingly many AI systems can plan and execute interactions in open-ended environments, such as making phone calls or buying online goods. As developers grow the space of tasks that such AI agents can accomplish, we will need tools both to unlock their benefits and manage their risks. Current tools are largely insufficient because they are not designed to shape how agents interact with existing institutions (e.g., legal and economic systems) or actors (e.g., digital service providers, humans, other AI agents). For example, alignment techniques by nature do not assure counterparties that some human will be held accountable when a user instructs an agent to perform an illegal action. To fill this gap, we propose the concept of agent infrastructure: technical systems and shared protocols external to agents that are designed to mediate and influence their interactions with and impacts on their environments. Agent infrastructure comprises both new tools and reconfigurations or extensions of existing tools. For example, to facilitate accountability, protocols that tie users to agents could build upon existing systems for user authentication, such as OpenID. Just as the Internet relies on infrastructure like HTTPS, we argue that agent infrastructure will be similarly indispensable to ecosystems of agents. We identify three functions for agent infrastructure: 1) attributing actions, properties, and other information to specific agents, their users, or other actors; 2) shaping agents' interactions; and 3) detecting and remedying harmful actions from agents. We propose infrastructure that could help achieve each function, explaining use cases, adoption, limitations, and open questions. Making progress on agent infrastructure can prepare society for the adoption of more advanced agents.
IDs for AI Systems
Jun 17, 2024



AI systems are increasingly pervasive, yet information needed to decide whether and how to engage with them may not exist or be accessible. A user may not be able to verify whether a system satisfies certain safety standards. An investigator may not know whom to investigate when a system causes an incident. A platform may find it difficult to penalize repeated negative interactions with the same system. Across a number of domains, IDs address analogous problems by identifying \textit{particular} entities (e.g., a particular Boeing 747) and providing information about other entities of the same class (e.g., some or all Boeing 747s). We propose a framework in which IDs are ascribed to \textbf{instances} of AI systems (e.g., a particular chat session with Claude 3), and associated information is accessible to parties seeking to interact with that system. We characterize IDs for AI systems, argue that there could be significant demand for IDs from key actors, analyze how those actors could incentivize ID adoption, explore potential implementations of our framework, and highlight limitations and risks. IDs seem most warranted in high-stakes settings, where certain actors (e.g., those that enable AI systems to make financial transactions) could experiment with incentives for ID use. Deployers of AI systems could experiment with developing ID implementations. With further study, IDs could help to manage a world where AI systems pervade society.
Beyond static AI evaluations: advancing human interaction evaluations for LLM harms and risks
May 17, 2024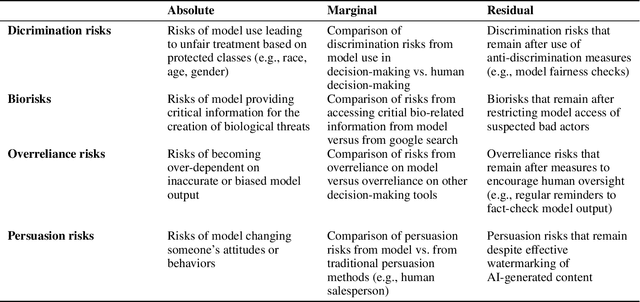
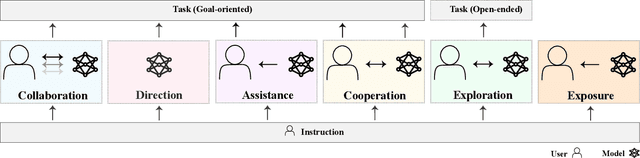
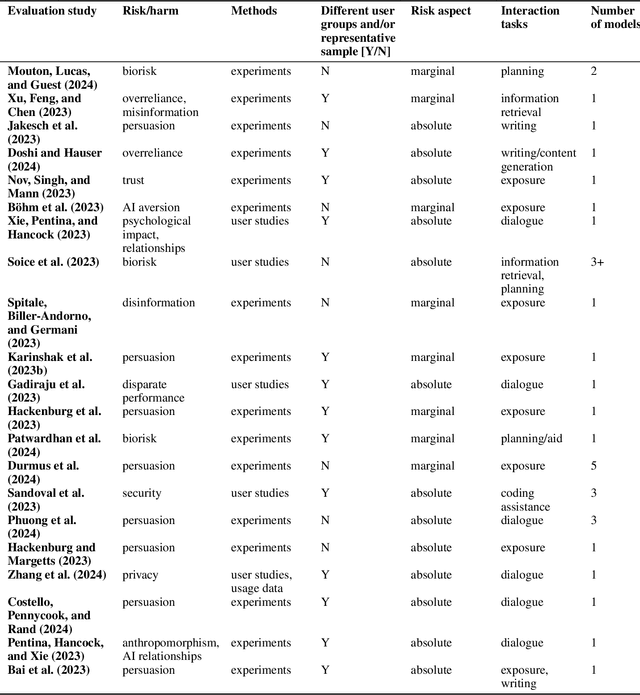
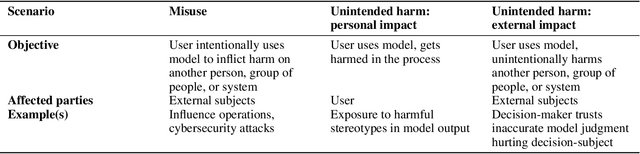
Model evaluations are central to understanding the safety, risks, and societal impacts of AI systems. While most real-world AI applications involve human-AI interaction, most current evaluations (e.g., common benchmarks) of AI models do not. Instead, they incorporate human factors in limited ways, assessing the safety of models in isolation, thereby falling short of capturing the complexity of human-model interactions. In this paper, we discuss and operationalize a definition of an emerging category of evaluations -- "human interaction evaluations" (HIEs) -- which focus on the assessment of human-model interactions or the process and the outcomes of humans using models. First, we argue that HIEs can be used to increase the validity of safety evaluations, assess direct human impact and interaction-specific harms, and guide future assessments of models' societal impact. Second, we propose a safety-focused HIE design framework -- containing a human-LLM interaction taxonomy -- with three stages: (1) identifying the risk or harm area, (2) characterizing the use context, and (3) choosing the evaluation parameters. Third, we apply our framework to two potential evaluations for overreliance and persuasion risks. Finally, we conclude with tangible recommendations for addressing concerns over costs, replicability, and unrepresentativeness of HIEs.
Societal Adaptation to Advanced AI
May 16, 2024


Existing strategies for managing risks from advanced AI systems often focus on affecting what AI systems are developed and how they diffuse. However, this approach becomes less feasible as the number of developers of advanced AI grows, and impedes beneficial use-cases as well as harmful ones. In response, we urge a complementary approach: increasing societal adaptation to advanced AI, that is, reducing the expected negative impacts from a given level of diffusion of a given AI capability. We introduce a conceptual framework which helps identify adaptive interventions that avoid, defend against and remedy potentially harmful uses of AI systems, illustrated with examples in election manipulation, cyberterrorism, and loss of control to AI decision-makers. We discuss a three-step cycle that society can implement to adapt to AI. Increasing society's ability to implement this cycle builds its resilience to advanced AI. We conclude with concrete recommendations for governments, industry, and third-parties.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Responsible Reporting for Frontier AI Development
Apr 03, 2024



Mitigating the risks from frontier AI systems requires up-to-date and reliable information about those systems. Organizations that develop and deploy frontier systems have significant access to such information. By reporting safety-critical information to actors in government, industry, and civil society, these organizations could improve visibility into new and emerging risks posed by frontier systems. Equipped with this information, developers could make better informed decisions on risk management, while policymakers could design more targeted and robust regulatory infrastructure. We outline the key features of responsible reporting and propose mechanisms for implementing them in practice.
Visibility into AI Agents
Feb 04, 2024

Increased delegation of commercial, scientific, governmental, and personal activities to AI agents -- systems capable of pursuing complex goals with limited supervision -- may exacerbate existing societal risks and introduce new risks. Understanding and mitigating these risks involves critically evaluating existing governance structures, revising and adapting these structures where needed, and ensuring accountability of key stakeholders. Information about where, why, how, and by whom certain AI agents are used, which we refer to as visibility, is critical to these objectives. In this paper, we assess three categories of measures to increase visibility into AI agents: agent identifiers, real-time monitoring, and activity logging. For each, we outline potential implementations that vary in intrusiveness and informativeness. We analyze how the measures apply across a spectrum of centralized through decentralized deployment contexts, accounting for various actors in the supply chain including hardware and software service providers. Finally, we discuss the implications of our measures for privacy and concentration of power. Further work into understanding the measures and mitigating their negative impacts can help to build a foundation for the governance of AI agents.
Towards Publicly Accountable Frontier LLMs: Building an External Scrutiny Ecosystem under the ASPIRE Framework
Nov 15, 2023With the increasing integration of frontier large language models (LLMs) into society and the economy, decisions related to their training, deployment, and use have far-reaching implications. These decisions should not be left solely in the hands of frontier LLM developers. LLM users, civil society and policymakers need trustworthy sources of information to steer such decisions for the better. Involving outside actors in the evaluation of these systems - what we term 'external scrutiny' - via red-teaming, auditing, and external researcher access, offers a solution. Though there are encouraging signs of increasing external scrutiny of frontier LLMs, its success is not assured. In this paper, we survey six requirements for effective external scrutiny of frontier AI systems and organize them under the ASPIRE framework: Access, Searching attitude, Proportionality to the risks, Independence, Resources, and Expertise. We then illustrate how external scrutiny might function throughout the AI lifecycle and offer recommendations to policymakers.
Frontier AI Regulation: Managing Emerging Risks to Public Safety
Jul 11, 2023Advanced AI models hold the promise of tremendous benefits for humanity, but society needs to proactively manage the accompanying risks. In this paper, we focus on what we term "frontier AI" models: highly capable foundation models that could possess dangerous capabilities sufficient to pose severe risks to public safety. Frontier AI models pose a distinct regulatory challenge: dangerous capabilities can arise unexpectedly; it is difficult to robustly prevent a deployed model from being misused; and, it is difficult to stop a model's capabilities from proliferating broadly. To address these challenges, at least three building blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models. Industry self-regulation is an important first step. However, wider societal discussions and government intervention will be needed to create standards and to ensure compliance with them. We consider several options to this end, including granting enforcement powers to supervisory authorities and licensure regimes for frontier AI models. Finally, we propose an initial set of safety standards. These include conducting pre-deployment risk assessments; external scrutiny of model behavior; using risk assessments to inform deployment decisions; and monitoring and responding to new information about model capabilities and uses post-deployment. We hope this discussion contributes to the broader conversation on how to balance public safety risks and innovation benefits from advances at the frontier of AI development.
Model evaluation for extreme risks
May 24, 2023



Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.