 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Insights from Simulation Gaming of AI Race Dynamics
Oct 04, 2024

We present insights from "Intelligence Rising", a scenario exploration exercise about possible AI futures. Drawing on the experiences of facilitators who have overseen 43 games over a four-year period, we illuminate recurring patterns, strategies, and decision-making processes observed during gameplay. Our analysis reveals key strategic considerations about AI development trajectories in this simulated environment, including: the destabilising effects of AI races, the crucial role of international cooperation in mitigating catastrophic risks, the challenges of aligning corporate and national interests, and the potential for rapid, transformative change in AI capabilities. We highlight places where we believe the game has been effective in exposing participants to the complexities and uncertainties inherent in AI governance. Key recurring gameplay themes include the emergence of international agreements, challenges to the robustness of such agreements, the critical role of cybersecurity in AI development, and the potential for unexpected crises to dramatically alter AI trajectories. By documenting these insights, we aim to provide valuable foresight for policymakers, industry leaders, and researchers navigating the complex landscape of AI development and governance.
AI Systems of Concern
Oct 09, 2023


Concerns around future dangers from advanced AI often centre on systems hypothesised to have intrinsic characteristics such as agent-like behaviour, strategic awareness, and long-range planning. We label this cluster of characteristics as "Property X". Most present AI systems are low in "Property X"; however, in the absence of deliberate steering, current research directions may rapidly lead to the emergence of highly capable AI systems that are also high in "Property X". We argue that "Property X" characteristics are intrinsically dangerous, and when combined with greater capabilities will result in AI systems for which safety and control is difficult to guarantee. Drawing on several scholars' alternative frameworks for possible AI research trajectories, we argue that most of the proposed benefits of advanced AI can be obtained by systems designed to minimise this property. We then propose indicators and governance interventions to identify and limit the development of systems with risky "Property X" characteristics.
Frontier AI Regulation: Managing Emerging Risks to Public Safety
Jul 11, 2023Advanced AI models hold the promise of tremendous benefits for humanity, but society needs to proactively manage the accompanying risks. In this paper, we focus on what we term "frontier AI" models: highly capable foundation models that could possess dangerous capabilities sufficient to pose severe risks to public safety. Frontier AI models pose a distinct regulatory challenge: dangerous capabilities can arise unexpectedly; it is difficult to robustly prevent a deployed model from being misused; and, it is difficult to stop a model's capabilities from proliferating broadly. To address these challenges, at least three building blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models. Industry self-regulation is an important first step. However, wider societal discussions and government intervention will be needed to create standards and to ensure compliance with them. We consider several options to this end, including granting enforcement powers to supervisory authorities and licensure regimes for frontier AI models. Finally, we propose an initial set of safety standards. These include conducting pre-deployment risk assessments; external scrutiny of model behavior; using risk assessments to inform deployment decisions; and monitoring and responding to new information about model capabilities and uses post-deployment. We hope this discussion contributes to the broader conversation on how to balance public safety risks and innovation benefits from advances at the frontier of AI development.
Model evaluation for extreme risks
May 24, 2023



Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
Filling gaps in trustworthy development of AI
Dec 14, 2021The range of application of artificial intelligence (AI) is vast, as is the potential for harm. Growing awareness of potential risks from AI systems has spurred action to address those risks, while eroding confidence in AI systems and the organizations that develop them. A 2019 study found over 80 organizations that published and adopted "AI ethics principles'', and more have joined since. But the principles often leave a gap between the "what" and the "how" of trustworthy AI development. Such gaps have enabled questionable or ethically dubious behavior, which casts doubts on the trustworthiness of specific organizations, and the field more broadly. There is thus an urgent need for concrete methods that both enable AI developers to prevent harm and allow them to demonstrate their trustworthiness through verifiable behavior. Below, we explore mechanisms (drawn from arXiv:2004.07213) for creating an ecosystem where AI developers can earn trust - if they are trustworthy. Better assessment of developer trustworthiness could inform user choice, employee actions, investment decisions, legal recourse, and emerging governance regimes.
Exploring AI Futures Through Role Play
Dec 19, 2019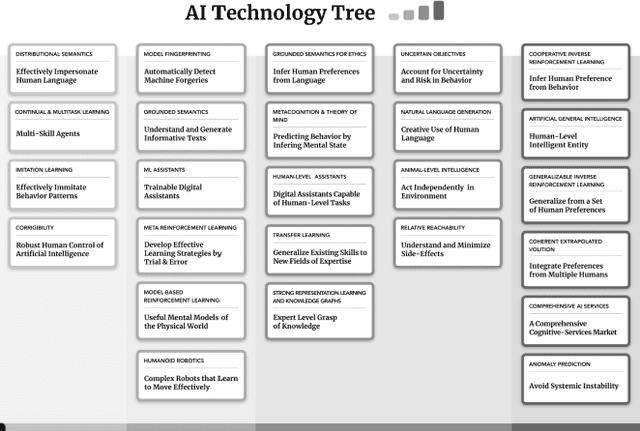
We present an innovative methodology for studying and teaching the impacts of AI through a role play game. The game serves two primary purposes: 1) training AI developers and AI policy professionals to reflect on and prepare for future social and ethical challenges related to AI and 2) exploring possible futures involving AI technology development, deployment, social impacts, and governance. While the game currently focuses on the inter relations between short --, mid and long term impacts of AI, it has potential to be adapted for a broad range of scenarios, exploring in greater depths issues of AI policy research and affording training within organizations. The game presented here has undergone two years of development and has been tested through over 30 events involving between 3 and 70 participants. The game is under active development, but preliminary findings suggest that role play is a promising methodology for both exploring AI futures and training individuals and organizations in thinking about, and reflecting on, the impacts of AI and strategic mistakes that can be avoided today.
Accounting for the Neglected Dimensions of AI Progress
Jun 02, 2018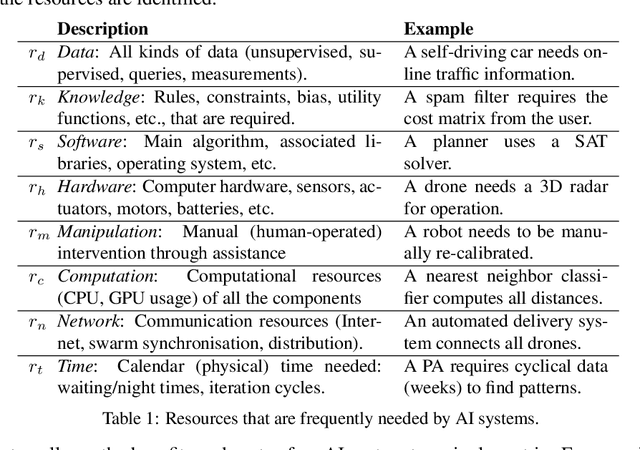
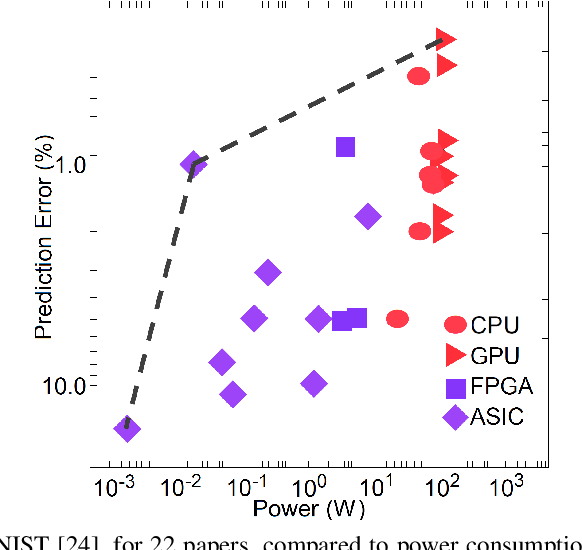
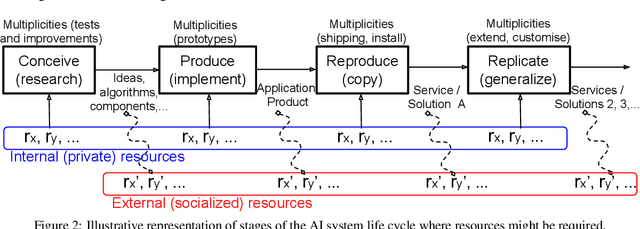
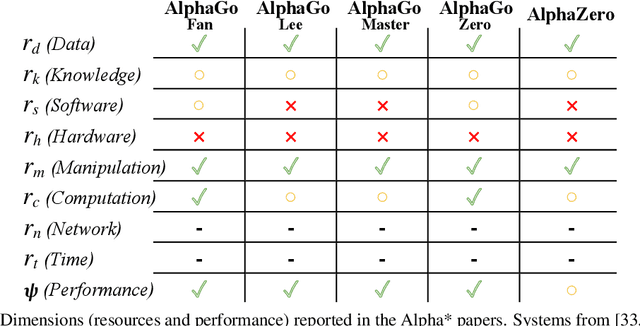
We analyze and reframe AI progress. In addition to the prevailing metrics of performance, we highlight the usually neglected costs paid in the development and deployment of a system, including: data, expert knowledge, human oversight, software resources, computing cycles, hardware and network facilities, development time, etc. These costs are paid throughout the life cycle of an AI system, fall differentially on different individuals, and vary in magnitude depending on the replicability and generality of the AI solution. The multidimensional performance and cost space can be collapsed to a single utility metric for a user with transitive and complete preferences. Even absent a single utility function, AI advances can be generically assessed by whether they expand the Pareto (optimal) surface. We explore a subset of these neglected dimensions using the two case studies of Alpha* and ALE. This broadened conception of progress in AI should lead to novel ways of measuring success in AI, and can help set milestones for future progress.
The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation
Feb 20, 2018
This report surveys the landscape of potential security threats from malicious uses of AI, and proposes ways to better forecast, prevent, and mitigate these threats. After analyzing the ways in which AI may influence the threat landscape in the digital, physical, and political domains, we make four high-level recommendations for AI researchers and other stakeholders. We also suggest several promising areas for further research that could expand the portfolio of defenses, or make attacks less effective or harder to execute. Finally, we discuss, but do not conclusively resolve, the long-term equilibrium of attackers and defenders.