 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Answer, Different Representations: Hidden instability in VLMs
Feb 06, 2026The robustness of Vision Language Models (VLMs) is commonly assessed through output-level invariance, implicitly assuming that stable predictions reflect stable multimodal processing. In this work, we argue that this assumption is insufficient. We introduce a representation-aware and frequency-aware evaluation framework that measures internal embedding drift, spectral sensitivity, and structural smoothness (spatial consistency of vision tokens), alongside standard label-based metrics. Applying this framework to modern VLMs across the SEEDBench, MMMU, and POPE datasets reveals three distinct failure modes. First, models frequently preserve predicted answers while undergoing substantial internal representation drift; for perturbations such as text overlays, this drift approaches the magnitude of inter-image variability, indicating that representations move to regions typically occupied by unrelated inputs despite unchanged outputs. Second, robustness does not improve with scale; larger models achieve higher accuracy but exhibit equal or greater sensitivity, consistent with sharper yet more fragile decision boundaries. Third, we find that perturbations affect tasks differently: they harm reasoning when they disrupt how models combine coarse and fine visual cues, but on the hallucination benchmarks, they can reduce false positives by making models generate more conservative answers.
Chain-of-Thought Hijacking
Oct 30, 2025Large reasoning models (LRMs) achieve higher task performance by allocating more inference-time compute, and prior works suggest this scaled reasoning may also strengthen safety by improving refusal. Yet we find the opposite: the same reasoning can be used to bypass safeguards. We introduce Chain-of-Thought Hijacking, a jailbreak attack on reasoning models. The attack pads harmful requests with long sequences of harmless puzzle reasoning. Across HarmBench, CoT Hijacking reaches a 99%, 94%, 100%, and 94% attack success rate (ASR) on Gemini 2.5 Pro, GPT o4 mini, Grok 3 mini, and Claude 4 Sonnet, respectively - far exceeding prior jailbreak methods for LRMs. To understand the effectiveness of our attack, we turn to a mechanistic analysis, which shows that mid layers encode the strength of safety checking, while late layers encode the verification outcome. Long benign CoT dilutes both signals by shifting attention away from harmful tokens. Targeted ablations of attention heads identified by this analysis causally decrease refusal, confirming their role in a safety subnetwork. These results show that the most interpretable form of reasoning - explicit CoT - can itself become a jailbreak vector when combined with final-answer cues. We release prompts, outputs, and judge decisions to facilitate replication.
Rethinking Safety in LLM Fine-tuning: An Optimization Perspective
Aug 17, 2025Fine-tuning language models is commonly believed to inevitably harm their safety, i.e., refusing to respond to harmful user requests, even when using harmless datasets, thus requiring additional safety measures. We challenge this belief through systematic testing, showing that poor optimization choices, rather than inherent trade-offs, often cause safety problems, measured as harmful responses to adversarial prompts. By properly selecting key training hyper-parameters, e.g., learning rate, batch size, and gradient steps, we reduce unsafe model responses from 16\% to approximately 5\%, as measured by keyword matching, while maintaining utility performance. Based on this observation, we propose a simple exponential moving average (EMA) momentum technique in parameter space that preserves safety performance by creating a stable optimization path and retains the original pre-trained model's safety properties. Our experiments on the Llama families across multiple datasets (Dolly, Alpaca, ORCA) demonstrate that safety problems during fine-tuning can largely be avoided without specialized interventions, outperforming existing approaches that require additional safety data while offering practical guidelines for maintaining both model performance and safety during adaptation.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025
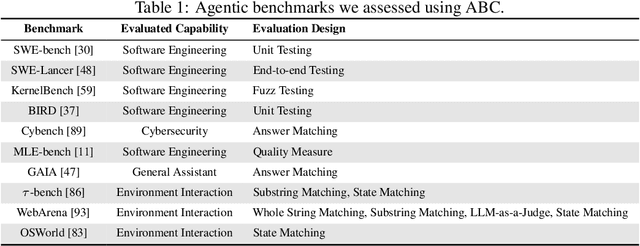
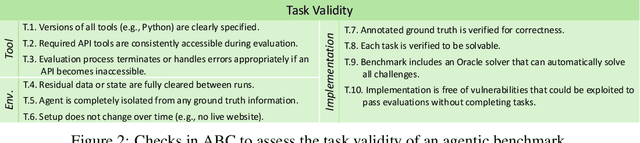
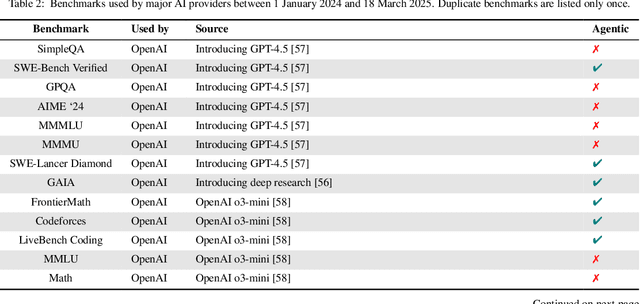
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Beyond Linear Steering: Unified Multi-Attribute Control for Language Models
May 30, 2025Controlling multiple behavioral attributes in large language models (LLMs) at inference time is a challenging problem due to interference between attributes and the limitations of linear steering methods, which assume additive behavior in activation space and require per-attribute tuning. We introduce K-Steering, a unified and flexible approach that trains a single non-linear multi-label classifier on hidden activations and computes intervention directions via gradients at inference time. This avoids linearity assumptions, removes the need for storing and tuning separate attribute vectors, and allows dynamic composition of behaviors without retraining. To evaluate our method, we propose two new benchmarks, ToneBank and DebateMix, targeting compositional behavioral control. Empirical results across 3 model families, validated by both activation-based classifiers and LLM-based judges, demonstrate that K-Steering outperforms strong baselines in accurately steering multiple behaviors.
Precise In-Parameter Concept Erasure in Large Language Models
May 28, 2025Large language models (LLMs) often acquire knowledge during pretraining that is undesirable in downstream deployments, e.g., sensitive information or copyrighted content. Existing approaches for removing such knowledge rely on fine-tuning, training low-rank adapters or fact-level editing, but these are either too coarse, too shallow, or ineffective. In this work, we propose PISCES (Precise In-parameter Suppression for Concept EraSure), a novel framework for precisely erasing entire concepts from model parameters by directly editing directions that encode them in parameter space. PISCES uses a disentangler model to decompose MLP vectors into interpretable features, identifies those associated with a target concept using automated interpretability techniques, and removes them from model parameters. Experiments on Gemma 2 and Llama 3.1 over various concepts show that PISCES achieves modest gains in efficacy over leading erasure methods, reducing accuracy on the target concept to as low as 7.7%, while dramatically improving erasure specificity (by up to 31%) and robustness (by up to 38%). Overall, these results demonstrate that feature-based in-parameter editing enables a more precise and reliable approach for removing conceptual knowledge in language models.
SafetyNet: Detecting Harmful Outputs in LLMs by Modeling and Monitoring Deceptive Behaviors
May 20, 2025High-risk industries like nuclear and aviation use real-time monitoring to detect dangerous system conditions. Similarly, Large Language Models (LLMs) need monitoring safeguards. We propose a real-time framework to predict harmful AI outputs before they occur by using an unsupervised approach that treats normal behavior as the baseline and harmful outputs as outliers. Our study focuses specifically on backdoor-triggered responses -- where specific input phrases activate hidden vulnerabilities causing the model to generate unsafe content like violence, pornography, or hate speech. We address two key challenges: (1) identifying true causal indicators rather than surface correlations, and (2) preventing advanced models from deception -- deliberately evading monitoring systems. Hence, we approach this problem from an unsupervised lens by drawing parallels to human deception: just as humans exhibit physical indicators while lying, we investigate whether LLMs display distinct internal behavioral signatures when generating harmful content. Our study addresses two critical challenges: 1) designing monitoring systems that capture true causal indicators rather than superficial correlations; and 2)preventing intentional evasion by increasingly capable "Future models''. Our findings show that models can produce harmful content through causal mechanisms and can become deceptive by: (a) alternating between linear and non-linear representations, and (b) modifying feature relationships. To counter this, we developed Safety-Net -- a multi-detector framework that monitors different representation dimensions, successfully detecting harmful behavior even when information is shifted across representational spaces to evade individual monitors. Our evaluation shows 96% accuracy in detecting harmful cases using our unsupervised ensemble approach.
Scaling sparse feature circuit finding for in-context learning
Apr 18, 2025Sparse autoencoders (SAEs) are a popular tool for interpreting large language model activations, but their utility in addressing open questions in interpretability remains unclear. In this work, we demonstrate their effectiveness by using SAEs to deepen our understanding of the mechanism behind in-context learning (ICL). We identify abstract SAE features that (i) encode the model's knowledge of which task to execute and (ii) whose latent vectors causally induce the task zero-shot. This aligns with prior work showing that ICL is mediated by task vectors. We further demonstrate that these task vectors are well approximated by a sparse sum of SAE latents, including these task-execution features. To explore the ICL mechanism, we adapt the sparse feature circuits methodology of Marks et al. (2024) to work for the much larger Gemma-1 2B model, with 30 times as many parameters, and to the more complex task of ICL. Through circuit finding, we discover task-detecting features with corresponding SAE latents that activate earlier in the prompt, that detect when tasks have been performed. They are causally linked with task-execution features through the attention and MLP sublayers.
Same Question, Different Words: A Latent Adversarial Framework for Prompt Robustness
Mar 03, 2025Insensitivity to semantically-preserving variations of prompts (paraphrases) is crucial for reliable behavior and real-world deployment of large language models. However, language models exhibit significant performance degradation when faced with semantically equivalent but differently phrased prompts, and existing solutions either depend on trial-and-error prompt engineering or require computationally expensive inference-time algorithms. In this study, built on the key insight that worst-case prompts exhibit a drift in embedding space, we present Latent Adversarial Paraphrasing (LAP), a dual-loop adversarial framework: the inner loop trains a learnable perturbation to serve as a "latent continuous paraphrase" while preserving semantics through Lagrangian regulation, and the outer loop optimizes the language model parameters on these perturbations. We conduct extensive experiments to demonstrate the effectiveness of LAP across multiple LLM architectures on the RobustAlpaca benchmark with a 0.5%-4% absolution improvement on worst-case win-rate compared with vanilla supervised fine-tuning.