 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More Experts Hurt: Underfitting in Multi-Expert Learning to Defer
Feb 19, 2026Learning to Defer (L2D) enables a classifier to abstain from predictions and defer to an expert, and has recently been extended to multi-expert settings. In this work, we show that multi-expert L2D is fundamentally more challenging than the single-expert case. With multiple experts, the classifier's underfitting becomes inherent, which seriously degrades prediction performance, whereas in the single-expert setting it arises only under specific conditions. We theoretically reveal that this stems from an intrinsic expert identifiability issue: learning which expert to trust from a diverse pool, a problem absent in the single-expert case and renders existing underfitting remedies failed. To tackle this issue, we propose PiCCE (Pick the Confident and Correct Expert), a surrogate-based method that adaptively identifies a reliable expert based on empirical evidence. PiCCE effectively reduces multi-expert L2D to a single-expert-like learning problem, thereby resolving multi expert underfitting. We further prove its statistical consistency and ability to recover class probabilities and expert accuracies. Extensive experiments across diverse settings, including real-world expert scenarios, validate our theoretical results and demonstrate improved performance.
Safety-Biased Policy Optimisation: Towards Hard-Constrained Reinforcement Learning via Trust Regions
Dec 29, 2025Reinforcement learning (RL) in safety-critical domains requires agents to maximise rewards while strictly adhering to safety constraints. Existing approaches, such as Lagrangian and projection-based methods, often either fail to ensure near-zero safety violations or sacrifice reward performance in the face of hard constraints. We propose Safety-Biased Trust Region Policy Optimisation (SB-TRPO), a new trust-region algorithm for hard-constrained RL. SB-TRPO adaptively biases policy updates towards constraint satisfaction while still seeking reward improvement. Concretely, it performs trust-region updates using a convex combination of the natural policy gradients of cost and reward, ensuring a fixed fraction of optimal cost reduction at each step. We provide a theoretical guarantee of local progress towards safety, with reward improvement when gradients are suitably aligned. Experiments on standard and challenging Safety Gymnasium tasks show that SB-TRPO consistently achieves the best balance of safety and meaningful task completion compared to state-of-the-art methods.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Open Problems in Machine Unlearning for AI Safety
Jan 09, 2025As AI systems become more capable, widely deployed, and increasingly autonomous in critical areas such as cybersecurity, biological research, and healthcare, ensuring their safety and alignment with human values is paramount. Machine unlearning -- the ability to selectively forget or suppress specific types of knowledge -- has shown promise for privacy and data removal tasks, which has been the primary focus of existing research. More recently, its potential application to AI safety has gained attention. In this paper, we identify key limitations that prevent unlearning from serving as a comprehensive solution for AI safety, particularly in managing dual-use knowledge in sensitive domains like cybersecurity and chemical, biological, radiological, and nuclear (CBRN) safety. In these contexts, information can be both beneficial and harmful, and models may combine seemingly harmless information for harmful purposes -- unlearning this information could strongly affect beneficial uses. We provide an overview of inherent constraints and open problems, including the broader side effects of unlearning dangerous knowledge, as well as previously unexplored tensions between unlearning and existing safety mechanisms. Finally, we investigate challenges related to evaluation, robustness, and the preservation of safety features during unlearning. By mapping these limitations and open challenges, we aim to guide future research toward realistic applications of unlearning within a broader AI safety framework, acknowledging its limitations and highlighting areas where alternative approaches may be required.
Reinforcement Learning with LTL and $ω$-Regular Objectives via Optimality-Preserving Translation to Average Rewards
Oct 16, 2024Linear temporal logic (LTL) and, more generally, $\omega$-regular objectives are alternatives to the traditional discount sum and average reward objectives in reinforcement learning (RL), offering the advantage of greater comprehensibility and hence explainability. In this work, we study the relationship between these objectives. Our main result is that each RL problem for $\omega$-regular objectives can be reduced to a limit-average reward problem in an optimality-preserving fashion, via (finite-memory) reward machines. Furthermore, we demonstrate the efficacy of this approach by showing that optimal policies for limit-average problems can be found asymptotically by solving a sequence of discount-sum problems approximately. Consequently, we resolve an open problem: optimal policies for LTL and $\omega$-regular objectives can be learned asymptotically.
Towards Interpreting Visual Information Processing in Vision-Language Models
Oct 09, 2024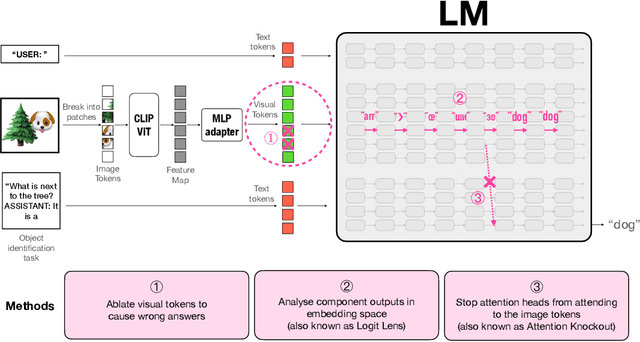



Vision-Language Models (VLMs) are powerful tools for processing and understanding text and images. We study the processing of visual tokens in the language model component of LLaVA, a prominent VLM. Our approach focuses on analyzing the localization of object information, the evolution of visual token representations across layers, and the mechanism of integrating visual information for predictions. Through ablation studies, we demonstrated that object identification accuracy drops by over 70\% when object-specific tokens are removed. We observed that visual token representations become increasingly interpretable in the vocabulary space across layers, suggesting an alignment with textual tokens corresponding to image content. Finally, we found that the model extracts object information from these refined representations at the last token position for prediction, mirroring the process in text-only language models for factual association tasks. These findings provide crucial insights into how VLMs process and integrate visual information, bridging the gap between our understanding of language and vision models, and paving the way for more interpretable and controllable multimodal systems.
Unifying Qualitative and Quantitative Safety Verification of DNN-Controlled Systems
Apr 02, 2024The rapid advance of deep reinforcement learning techniques enables the oversight of safety-critical systems through the utilization of Deep Neural Networks (DNNs). This underscores the pressing need to promptly establish certified safety guarantees for such DNN-controlled systems. Most of the existing verification approaches rely on qualitative approaches, predominantly employing reachability analysis. However, qualitative verification proves inadequate for DNN-controlled systems as their behaviors exhibit stochastic tendencies when operating in open and adversarial environments. In this paper, we propose a novel framework for unifying both qualitative and quantitative safety verification problems of DNN-controlled systems. This is achieved by formulating the verification tasks as the synthesis of valid neural barrier certificates (NBCs). Initially, the framework seeks to establish almost-sure safety guarantees through qualitative verification. In cases where qualitative verification fails, our quantitative verification method is invoked, yielding precise lower and upper bounds on probabilistic safety across both infinite and finite time horizons. To facilitate the synthesis of NBCs, we introduce their $k$-inductive variants. We also devise a simulation-guided approach for training NBCs, aiming to achieve tightness in computing precise certified lower and upper bounds. We prototype our approach into a tool called $\textsf{UniQQ}$ and showcase its efficacy on four classic DNN-controlled systems.
Rethinking Variational Inference for Probabilistic Programs with Stochastic Support
Nov 01, 2023



We introduce Support Decomposition Variational Inference (SDVI), a new variational inference (VI) approach for probabilistic programs with stochastic support. Existing approaches to this problem rely on designing a single global variational guide on a variable-by-variable basis, while maintaining the stochastic control flow of the original program. SDVI instead breaks the program down into sub-programs with static support, before automatically building separate sub-guides for each. This decomposition significantly aids in the construction of suitable variational families, enabling, in turn, substantial improvements in inference performance.
Beyond Bayesian Model Averaging over Paths in Probabilistic Programs with Stochastic Support
Oct 23, 2023
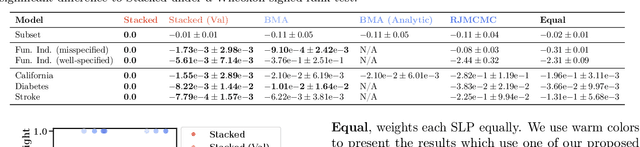


The posterior in probabilistic programs with stochastic support decomposes as a weighted sum of the local posterior distributions associated with each possible program path. We show that making predictions with this full posterior implicitly performs a Bayesian model averaging (BMA) over paths. This is potentially problematic, as model misspecification can cause the BMA weights to prematurely collapse onto a single path, leading to sub-optimal predictions in turn. To remedy this issue, we propose alternative mechanisms for path weighting: one based on stacking and one based on ideas from PAC-Bayes. We show how both can be implemented as a cheap post-processing step on top of existing inference engines. In our experiments, we find them to be more robust and lead to better predictions compared to the default BMA weights.
Exact Bayesian Inference on Discrete Models via Probability Generating Functions: A Probabilistic Programming Approach
May 26, 2023



We present an exact Bayesian inference method for discrete statistical models, which can find exact solutions to many discrete inference problems, even with infinite support and continuous priors. To express such models, we introduce a probabilistic programming language that supports discrete and continuous sampling, discrete observations, affine functions, (stochastic) branching, and conditioning on events. Our key tool is probability generating functions: they provide a compact closed-form representation of distributions that are definable by programs, thus enabling the exact computation of posterior probabilities, expectation, variance, and higher moments. Our inference method is provably correct, fully automated and uses automatic differentiation (specifically, Taylor polynomials), but does not require computer algebra. Our experiments show that its performance on a range of real-world examples is competitive with approximate Monte Carlo methods, while avoiding approximation errors.