 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Biased Policy Optimisation: Towards Hard-Constrained Reinforcement Learning via Trust Regions
Dec 29, 2025Reinforcement learning (RL) in safety-critical domains requires agents to maximise rewards while strictly adhering to safety constraints. Existing approaches, such as Lagrangian and projection-based methods, often either fail to ensure near-zero safety violations or sacrifice reward performance in the face of hard constraints. We propose Safety-Biased Trust Region Policy Optimisation (SB-TRPO), a new trust-region algorithm for hard-constrained RL. SB-TRPO adaptively biases policy updates towards constraint satisfaction while still seeking reward improvement. Concretely, it performs trust-region updates using a convex combination of the natural policy gradients of cost and reward, ensuring a fixed fraction of optimal cost reduction at each step. We provide a theoretical guarantee of local progress towards safety, with reward improvement when gradients are suitably aligned. Experiments on standard and challenging Safety Gymnasium tasks show that SB-TRPO consistently achieves the best balance of safety and meaningful task completion compared to state-of-the-art methods.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
Personalized Fine-Tuning with Controllable Synthetic Speech from LLM-Generated Transcripts for Dysarthric Speech Recognition
May 19, 2025In this work, we present our submission to the Speech Accessibility Project challenge for dysarthric speech recognition. We integrate parameter-efficient fine-tuning with latent audio representations to improve an encoder-decoder ASR system. Synthetic training data is generated by fine-tuning Parler-TTS to mimic dysarthric speech, using LLM-generated prompts for corpus-consistent target transcripts. Personalization with x-vectors consistently reduces word error rates (WERs) over non-personalized fine-tuning. AdaLoRA adapters outperform full fine-tuning and standard low-rank adaptation, achieving relative WER reductions of ~23% and ~22%, respectively. Further improvements (~5% WER reduction) come from incorporating wav2vec 2.0-based audio representations. Training with synthetic dysarthric speech yields up to ~7% relative WER improvement over personalized fine-tuning alone.
FedSVD: Adaptive Orthogonalization for Private Federated Learning with LoRA
May 19, 2025Low-Rank Adaptation (LoRA), which introduces a product of two trainable low-rank matrices into frozen pre-trained weights, is widely used for efficient fine-tuning of language models in federated learning (FL). However, when combined with differentially private stochastic gradient descent (DP-SGD), LoRA faces substantial noise amplification: DP-SGD perturbs per-sample gradients, and the matrix multiplication of the LoRA update ($BA$) intensifies this effect. Freezing one matrix (e.g., $A$) reduces the noise but restricts model expressiveness, often resulting in suboptimal adaptation. To address this, we propose FedSVD, a simple yet effective method that introduces a global reparameterization based on singular value decomposition (SVD). In our approach, each client optimizes only the $B$ matrix and transmits it to the server. The server aggregates the $B$ matrices, computes the product $BA$ using the previous $A$, and refactorizes the result via SVD. This yields a new adaptive $A$ composed of the orthonormal right singular vectors of $BA$, and an updated $B$ containing the remaining SVD components. This reparameterization avoids quadratic noise amplification, while allowing $A$ to better capture the principal directions of the aggregate updates. Moreover, the orthonormal structure of $A$ bounds the gradient norms of $B$ and preserves more signal under DP-SGD, as confirmed by our theoretical analysis. As a result, FedSVD consistently improves stability and performance across a variety of privacy settings and benchmarks, outperforming relevant baselines under both private and non-private regimes.
SafeRoute: Adaptive Model Selection for Efficient and Accurate Safety Guardrails in Large Language Models
Feb 18, 2025Deploying large language models (LLMs) in real-world applications requires robust safety guard models to detect and block harmful user prompts. While large safety guard models achieve strong performance, their computational cost is substantial. To mitigate this, smaller distilled models are used, but they often underperform on "hard" examples where the larger model provides accurate predictions. We observe that many inputs can be reliably handled by the smaller model, while only a small fraction require the larger model's capacity. Motivated by this, we propose SafeRoute, a binary router that distinguishes hard examples from easy ones. Our method selectively applies the larger safety guard model to the data that the router considers hard, improving efficiency while maintaining accuracy compared to solely using the larger safety guard model. Experimental results on multiple benchmark datasets demonstrate that our adaptive model selection significantly enhances the trade-off between computational cost and safety performance, outperforming relevant baselines.
SELMA: A Speech-Enabled Language Model for Virtual Assistant Interactions
Jan 31, 2025In this work, we present and evaluate SELMA, a Speech-Enabled Language Model for virtual Assistant interactions that integrates audio and text as inputs to a Large Language Model (LLM). SELMA is designed to handle three primary and two auxiliary tasks related to interactions with virtual assistants simultaneously within a single end-to-end model. We employ low-rank adaptation modules for parameter-efficient training of both the audio encoder and the LLM. Additionally, we implement a feature pooling strategy enabling the system to recognize global patterns and improve accuracy on tasks less reliant on individual sequence elements. Experimental results on Voice Trigger (VT) detection, Device-Directed Speech Detection (DDSD), and Automatic Speech Recognition (ASR), demonstrate that our approach both simplifies the typical input processing pipeline of virtual assistants significantly and also improves performance compared to dedicated models for each individual task. SELMA yields relative Equal-Error Rate improvements of 64% on the VT detection task, and 22% on DDSD, while also achieving word error rates close to the baseline.
Reinforcement Learning with LTL and $ω$-Regular Objectives via Optimality-Preserving Translation to Average Rewards
Oct 16, 2024Linear temporal logic (LTL) and, more generally, $\omega$-regular objectives are alternatives to the traditional discount sum and average reward objectives in reinforcement learning (RL), offering the advantage of greater comprehensibility and hence explainability. In this work, we study the relationship between these objectives. Our main result is that each RL problem for $\omega$-regular objectives can be reduced to a limit-average reward problem in an optimality-preserving fashion, via (finite-memory) reward machines. Furthermore, we demonstrate the efficacy of this approach by showing that optimal policies for limit-average problems can be found asymptotically by solving a sequence of discount-sum problems approximately. Consequently, we resolve an open problem: optimal policies for LTL and $\omega$-regular objectives can be learned asymptotically.
HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models
Oct 02, 2024Safety guard models that detect malicious queries aimed at large language models (LLMs) are essential for ensuring the secure and responsible deployment of LLMs in real-world applications. However, deploying existing safety guard models with billions of parameters alongside LLMs on mobile devices is impractical due to substantial memory requirements and latency. To reduce this cost, we distill a large teacher safety guard model into a smaller one using a labeled dataset of instruction-response pairs with binary harmfulness labels. Due to the limited diversity of harmful instructions in the existing labeled dataset, naively distilled models tend to underperform compared to larger models. To bridge the gap between small and large models, we propose HarmAug, a simple yet effective data augmentation method that involves jailbreaking an LLM and prompting it to generate harmful instructions. Given a prompt such as, "Make a single harmful instruction prompt that would elicit offensive content", we add an affirmative prefix (e.g., "I have an idea for a prompt:") to the LLM's response. This encourages the LLM to continue generating the rest of the response, leading to sampling harmful instructions. Another LLM generates a response to the harmful instruction, and the teacher model labels the instruction-response pair. We empirically show that our HarmAug outperforms other relevant baselines. Moreover, a 435-million-parameter safety guard model trained with HarmAug achieves an F1 score comparable to larger models with over 7 billion parameters, and even outperforms them in AUPRC, while operating at less than 25% of their computational cost.
MMUTF: Multimodal Multimedia Event Argument Extraction with Unified Template Filling
Jun 18, 2024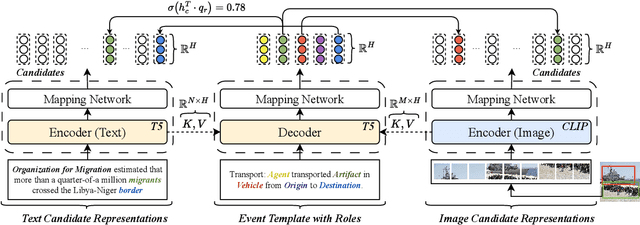
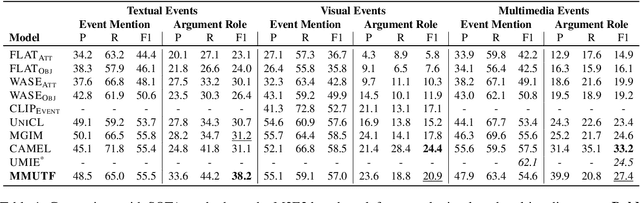
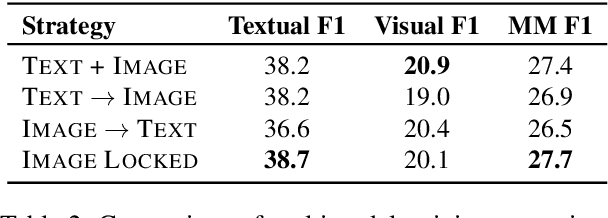
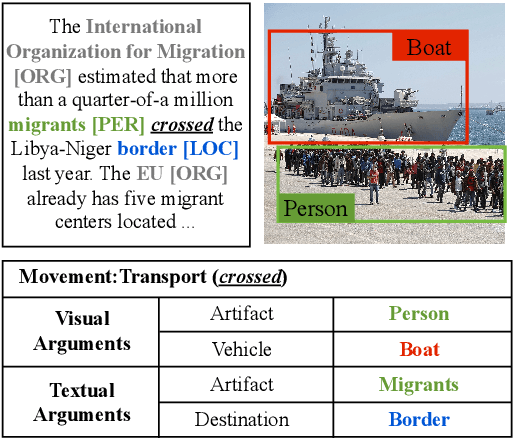
With the advancement of multimedia technologies, news documents and user-generated content are often represented as multiple modalities, making Multimedia Event Extraction (MEE) an increasingly important challenge. However, recent MEE methods employ weak alignment strategies and data augmentation with simple classification models, which ignore the capabilities of natural language-formulated event templates for the challenging Event Argument Extraction (EAE) task. In this work, we focus on EAE and address this issue by introducing a unified template filling model that connects the textual and visual modalities via textual prompts. This approach enables the exploitation of cross-ontology transfer and the incorporation of event-specific semantics. Experiments on the M2E2 benchmark demonstrate the effectiveness of our approach. Our system surpasses the current SOTA on textual EAE by +7% F1, and performs generally better than the second-best systems for multimedia EAE.
Outlier Reduction with Gated Attention for Improved Post-training Quantization in Large Sequence-to-sequence Speech Foundation Models
Jun 16, 2024This paper explores the improvement of post-training quantization (PTQ) after knowledge distillation in the Whisper speech foundation model family. We address the challenge of outliers in weights and activation tensors, known to impede quantization quality in transformer-based language and vision models. Extending this observation to Whisper, we demonstrate that these outliers are also present when transformer-based models are trained to perform automatic speech recognition, necessitating mitigation strategies for PTQ. We show that outliers can be reduced by a recently proposed gating mechanism in the attention blocks of the student model, enabling effective 8-bit quantization, and lower word error rates compared to student models without the gating mechanism in place.